Что на самом деле означает кластеризованный и некластеризованный индекс?
у меня ограниченное воздействие БД и я использовал БД только в качестве программиста приложений. Я хочу знать, о Clustered и Non clustered indexes.
Я погуглил, и то, что я нашел, было:
кластеризованный индекс-это специальный тип индекса, который переупорядочивает путь записи в таблице физически на хранении. Поэтому таблица может иметь только один кластеризованный индекс. Листовые узлы кластеризованный индекс содержит данные страницы. Некластеризованный индекс специальный тип индекса в чего логический порядок индекса не сопоставьте физический сохраненный порядок строки на диске. Узел лист некластеризованный индекс не состоит из страница данных. Вместо листьев узлы содержат строки индекса.
то, что я нашел в SO, было каковы различия между кластерным и некластерным индексом?.
может кто-нибудь объяснить это на простом английском языке?
9 ответов
с кластеризованным индексом строки хранятся физически на диске в том же порядке, как индекс. Поэтому здесь может быть только один кластеризованный индекс.
с некластеризованным индексом есть второй список, который имеет указатели на физические строки. У вас может быть много некластеризованных индексов, хотя каждый новый индекс увеличивает время, необходимое для записи новых записей.
Это вообще быстрее читать из кластеризованного индекса, если вы хотите вернуть все столбцы. Вам не нужно сначала идти к индексу, а затем к таблице.
запись в таблице с кластеризованным индексом может быть медленнее, если необходимо изменить данные.
кластеризованный индекс означает, что вы говорите базе данных хранить значения закрытия фактически близко друг к другу на диске. Это имеет преимущество быстрого сканирования / извлечения записей, попадающих в некоторый диапазон значений кластеризованных индексов.
например, у вас есть две таблицы: Customer и Order:
Customer
----------
ID
Name
Address
Order
----------
ID
CustomerID
Price
Если вы хотите быстро получить все заказы одного конкретного клиента, вы можете создать кластеризованный индекс в столбце "CustomerID" таблицы заказов. Этот способ записи с тем же CustomerID будут физически храниться близко друг к другу на диске (кластеризованном), что ускоряет их извлечение.
P.S. индекс CustomerID, очевидно, не будет уникальным, поэтому вам нужно либо добавить второе поле для "унификации" индекса, либо позволить базе данных обрабатывать это для вас, но это другая история.
по несколько индексов. Для каждой таблицы может быть только один кластеризованный индекс, так как это определяет физическое расположение данных. Если вам нужна аналогия, представьте себе большую комнату со множеством столов. Вы можете либо поместить эти таблицы в несколько рядов, либо собрать их вместе, чтобы сформировать большой стол для конференций, но не в обоих направлениях одновременно. Таблица может иметь другие индексы, они будут указывать на записи в кластеризованном индексе, который в свою очередь, наконец, скажет, где найти фактические данные.
в хранилище, ориентированном на строки SQL Server, кластеризованные и некластеризованные индексы организованы в виде деревьев B.
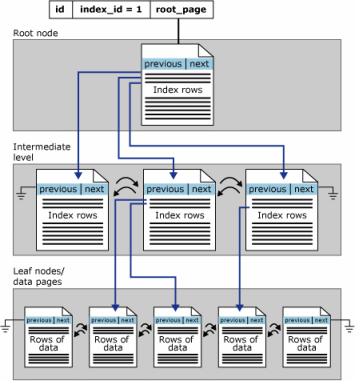
ключевое различие между кластеризованными индексами и некластеризованными индексами заключается в том, что уровень листа кластеризованного индекса is столе. Это имеет два следствия.
- строки на листовых страницах кластеризованного индекса всегда содержат что-то для каждого из (не разреженных) столбцов в таблице (либо значение, либо указатель на фактическое значение).
- кластеризованный индекс является первичной копией таблицы.
некластеризованные индексы также могут выполнять пункт 1 с помощью INCLUDE предложение (начиная с SQL Server 2005) явно включать все неключевые столбцы, но они являются вторичными представлениями, и всегда есть другая копия данных вокруг (таблица сам.)
CREATE TABLE T
(
A INT,
B INT,
C INT,
D INT
)
CREATE UNIQUE CLUSTERED INDEX ci ON T(A,B)
CREATE UNIQUE NONCLUSTERED INDEX nci ON T(A,B) INCLUDE (C,D)
два индекса выше будут почти идентичными. С индексными страницами верхнего уровня, содержащими значения для ключевых столбцов A,B и страницы уровня листа, содержащие A,B,C,D
в таблице может быть только один кластеризованный индекс, поскольку строки данных сами могут быть отсортированы только в одном порядке.
приведенная выше цитата из SQL Server books online вызывает много путаницы
на мой взгляд это гораздо лучше сформулировать как.
в таблице может быть только один кластеризованный индекс, потому что строки уровня листа кластеризованного индекса are строки таблицы.
цитата книги онлайн не является неправильной, но вы должны быть ясно, что" сортировка " как некластеризованных, так и кластеризованных индексов логична, а не физическая. Если Вы читаете страницы на уровне листа, следуя связанному списку, и читаете строки на странице в порядке массива слотов, то вы будете читать строки индекса в отсортированном порядке, но физически страницы могут не быть отсортированы. Общепринятое мнение, что с кластеризованным индексом строки всегда хранятся физически на диске в том же порядке, что и индекс ключ ложно.
это была бы абсурдная реализация. Например, если строка вставлена в середину таблицы 4GB, SQL Server делает не скопировать файл 2 Гб данных в файл, чтобы освободить место для вновь вставленной строки .
вместо этого происходит разделение страницы. Каждая страница на уровне листа как кластеризованных, так и некластеризованных индексов имеет адрес (File:Page) следующей и предыдущей страниц в логическом порядке ключей. Эти страницы не должны быть ни смежными, ни в ключевом порядке.
например, связанная цепочка страниц может быть 1:2000 <-> 1:157 <-> 1:7053
когда происходит разделение страницы, новая страница выделяется из любого места в файловой группе (из смешанного экстента, для небольших таблиц или непустой униформы экстент, принадлежащий этому объекту или вновь выделенному однородному экстенту). Это может быть даже не в одном файле, если файловая группа содержит более одного.
степень, в которой логический порядок и смежность отличаются от идеализированной физической версии, является степенью логической фрагментации.
во вновь созданной базе данных с одним файлом я запустил следующее.
CREATE TABLE T
(
X TINYINT NOT NULL,
Y CHAR(3000) NULL
);
CREATE CLUSTERED INDEX ix
ON T(X);
GO
--Insert 100 rows with values 1 - 100 in random order
DECLARE @C1 AS CURSOR,
@X AS INT
SET @C1 = CURSOR FAST_FORWARD
FOR SELECT number
FROM master..spt_values
WHERE type = 'P'
AND number BETWEEN 1 AND 100
ORDER BY CRYPT_GEN_RANDOM(4)
OPEN @C1;
FETCH NEXT FROM @C1 INTO @X;
WHILE @@FETCH_STATUS = 0
BEGIN
INSERT INTO T (X)
VALUES (@X);
FETCH NEXT FROM @C1 INTO @X;
END
затем проверьте макет страницы с
SELECT page_id,
X,
geometry::Point(page_id, X, 0).STBuffer(1)
FROM T
CROSS APPLY sys.fn_PhysLocCracker( %% physloc %% )
ORDER BY page_id
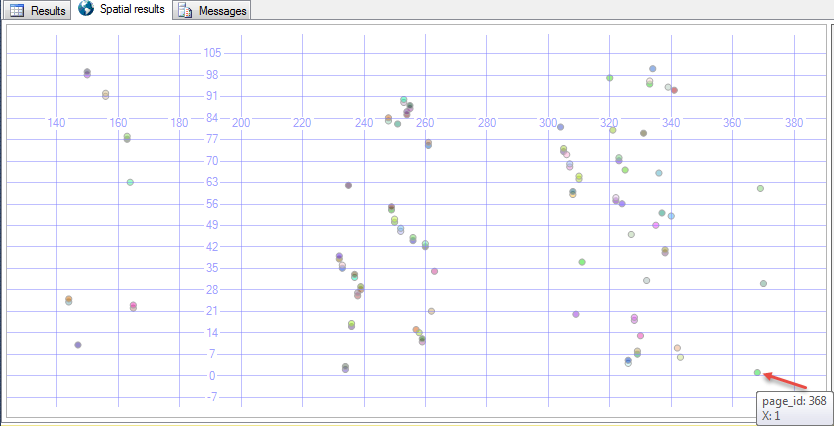
результаты были повсюду. Первая строка в порядке клавиш (со значением 1 - выделена стрелкой ниже) была почти на последней физической странице.
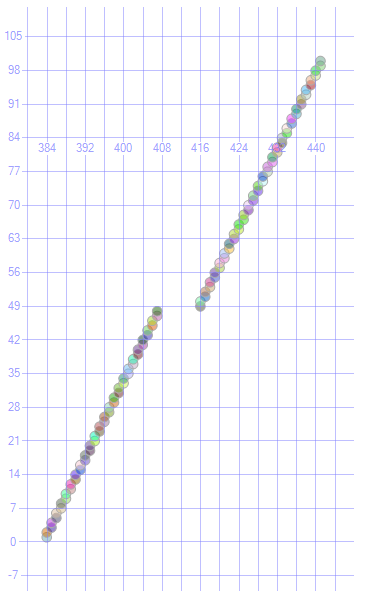
фрагментация может быть уменьшена или удалена путем перестройки или реорганизации индекса для увеличения корреляции между логическим порядком и физическим порядком.
после
ALTER INDEX ix ON T REBUILD;
я получил следующее
если таблица не имеет кластеризованного индекса это называется кучей.
некластеризованные индексы могут быть построены на куче или кластеризованном индексе. Они всегда содержат локатор строк обратно в базовую таблицу. В случае кучи это физический идентификатор строки (rid) и состоит из трех компонентов (File:Page:Slot). В случае кластеризованного индекса локатор строк является логическим (ключ кластеризованного индекса).
для последнего случая, если некластеризованный индекс уже естественно включает ключевой столбец(ы) CI либо как Ключевые столбцы NCI или INCLUDE-D столбцов, то ничего не добавляется. В противном случае отсутствующие ключевые столбцы CI молча добавляются в NCI.
SQL Server всегда гарантирует, что ключевые столбцы уникальны для обоих типов индексов. Однако механизм, в котором это применяется для индексов, не объявленных уникальными, отличается между двумя типами индексов.
кластеризованные индексы получают uniquifier добавлено для любых строк со значениями ключей, которые дублируют существующую строку. Это просто восходящее целое число.
для некластеризованных индексов, не объявленных уникальными, SQL Server автоматически добавляет локатор строк в ключ некластеризованного индекса. Это относится ко всем строкам, а не только к тем, которые на самом деле являются дубликатами.
кластеризованная и некластеризованная номенклатура также используется для индексов хранилища столбцов. Бумага! .. --97-->усовершенствования хранилищ столбцов SQL Server государства
хотя данные хранилища столбцов на самом деле не " кластеризованы" на любом ключе, мы решено сохранить традиционное соглашение SQL Server о ссылке к первичному индексу как кластеризованному индексу.
Я понимаю, что это очень старый вопрос, но я думал, что предложу аналогию, чтобы проиллюстрировать прекрасные ответы выше.
КЛАСТЕРИЗОВАННЫЙ ИНДЕКС
если вы войдете в Публичную библиотеку, вы обнаружите, что все книги расположены в определенном порядке (скорее всего, десятичная система Дьюи или DDS). Это соответствует "кластерный индекс" книги. Если DDS# для книги, которую вы хотите, был 005.7565 F736s, вы бы начали с поиска строки книжные полки с надписью 001-099 или что-то подобное. (Этот знак endcap в конце стека соответствует "промежуточному узлу" в индексе.) В конце концов вы бы сверлить до конкретной полки с надписью 005.7450 - 005.7600, затем вы будете сканировать, пока не найдете книгу с указанным DDS#, и в этот момент вы нашли свою книгу.
НЕКЛАСТЕРИЗОВАННЫЙ ИНДЕКС
но если вы не пришли в библиотеку с DDS# вашей книги наизусть, то вам понадобится второй указатель, чтобы помочь вам. В старые времена в передней части библиотеки вы найдете замечательное бюро ящиков, известное как"карточный каталог". В нем были тысячи карточек 3х5-по одной на каждую книгу, отсортированных в алфавитном порядке (возможно, по названию). Это соответствует "некластерного индекса". Эти каталоги карт были организованы в иерархическую структуру, так что каждый ящик был помечен диапазоном карт, которые он содержал (Ka - Kl, например; т. е. "промежуточный узел"). Еще раз, вы бы сверлить, пока вы не нашли свою книгу, но в этой дело, как только вы его нашли (i.e, "листовой узел"), у вас нет самой книги, а только карта с индекс номер (DDS#), с помощью которого вы можете найти фактическую книгу в кластеризованном индексе.
ниже приведены некоторые характеристики кластеризованных и некластеризованных индексов:
Кластеризованных Индексов
- кластеризованные индексы-это индексы, которые однозначно идентифицируют строки в таблице SQL.
- каждая таблица может иметь ровно один кластеризованный индекс.
- можно создать кластеризованный индекс, который охватывает более одного столбца. Например:
create Index index_name(col1, col2, col.....). - по умолчанию столбец с первичным ключом уже имеет кластеризованный индекс.
некластерные индексы
- некластеризованные индексы похожи на простые индексы. Они просто используются для быстрого поиска данных. Не уверен, что есть уникальные данные.
очень простым, нетехническим эмпирическим правилом было бы то, что кластеризованные индексы обычно используются для вашего первичного ключа (или, по крайней мере, уникального столбца) и что некластеризованные используются для других ситуаций (возможно, внешний ключ). Действительно, SQL Server по умолчанию создаст кластеризованный индекс для столбцов первичного ключа. Как вы узнаете, кластеризованный индекс относится к способу физической сортировки данных на диске, что означает, что это хороший всесторонний выбор для большинства ситуаций.
Кластерный Индекс
кластерный индекс определяет физический порядок данных в таблице.По этой причине таблица имеет только 1 кластеризованный индекс.
как "словарь" нет необходимости в любом другом индексе, его уже индекс в соответствии со словами
Некластеризованный Индекс
некластеризованный индекс аналогичен индексу в книге.Данные хранятся в одном месте. этот индекс-это магазин в другом месте, и индекс имеет указывает на место хранения данных.По этой причине таблица имеет более 1 некластеризованного индекса.
как "химия книга" в уставившись есть отдельный индекс, чтобы указать расположение главы и в "конце" есть еще один индекс, указывающий общие слова местоположение
Кластерный Индекс
кластеризованные индексы сортируют и хранят строки данных в таблице или представлении на основе их ключевых значений. Это столбцы, включенные в определение индекса. Для каждой таблицы может быть только один кластеризованный индекс, поскольку сами строки данных могут быть отсортированы только в одном порядке.
строки данных в таблице хранятся в отсортированном порядке только тогда, когда таблица содержит кластеризованный индекс. Когда таблица имеет кластеризованный индекс, таблица называется кластеризованной таблицей. Если таблица не имеет кластеризованного индекса, ее строки данных хранятся в неупорядоченной структуре, называемой кучей.
некластеризованный
некластеризованные индексы имеют структуру, отдельную от строк данных. Некластеризованный индекс содержит значения ключа некластеризованного индекса, и каждая запись значения ключа имеет указатель на строку данных, содержащую значение ключа. Указатель из строки индекса в некластеризованном индексе на строку данных называется строкой локатор. Структура локатора строк зависит от того, хранятся ли страницы данных в куче или кластеризованной таблице. Для кучи локатор строк-это указатель на строку. Для кластеризованной таблицы локатором строк является ключ кластеризованного индекса.
вы можете добавить неключевые столбцы на уровень листа некластеризованного индекса, чтобы обойти существующие ограничения ключа индекса и выполнить полностью покрытые, индексированные запросы. Дополнительные сведения см. В разделе создание индексов с включенными столбцами. Подробнее о index ограничения по ключам см. спецификации максимальной емкости для SQL Server.
Если файл, содержащий записи, упорядочен последовательно, индекс кластеризации-это индекс, ключ поиска которого также определяет последовательный порядок файла. Индексы кластеризации также называются первичными индексами; термин первичный индекс может обозначать индекс первичного ключа, но на самом деле такие индексы могут быть построены на любом ключе поиска. Ключ поиска индекса кластеризации часто является первичным ключом, хотя это не обязательно так. Индексы, ключ поиска которых задает другой порядок из последовательного порядка файлов называются некластеризующиеся индексы, или вторичные индексы. Термины"кластерный" и "некластеризованный " часто используются вместо "кластеризации" и "nonclustering."