Как работает PHP-память
Я всегда слышал и искал новую php "хорошую практику написания", например: лучше (для производительности) проверить, существует ли ключ массива, чем поиск в массиве, но также кажется лучше для памяти:
предполагая, что у нас есть:
$array = array
(
'one' => 1,
'two' => 2,
'three' => 3,
'four' => 4,
);
это выделяет 1040 байт памяти,
и
$array = array
(
1 => 'one',
2 => 'two',
3 => 'three',
4 => 'four',
);
требуется 1136 байт
Я понимаю, что key и value конечно будет иметь различный механизм хранения, но
пожалуйста, вы можете указать мне на принцип, как это работает?
Пример 2 (для @teuneboon):
$array = array
(
'one' => '1',
'two' => '2',
'three' => '3',
'four' => '4',
);
1168 байт
$array = array
(
'1' => 'one',
'2' => 'two',
'3' => 'three',
'4' => 'four',
);
1136 байт
потребляя ту же память:
4 => 'four','4' => 'four',
4 ответов
Примечание, ответ ниже применим для PHP до к версии 7, как и в PHP 7, были внесены основные изменения, которые также включают структуры значений.
TL; DR
ваш вопрос на самом деле не о "как работает память в PHP" (здесь, я полагаю, вы имели в виду "выделение памяти"), но о "как работают массивы в PHP" - и эти два вопроса разные. Подводя итог, что написано ниже:
- массивы PHP не являются "массивами" в классическом смысле. Это хэш-карты
- Hash-map для массива PHP имеет определенную структуру и использует множество дополнительных вещей хранения, таких как указатели внутренних ссылок
- элементы хэш-карты для PHP хэш-карты также используют дополнительные поля для хранения информации. И-да, важны не только строковые/целочисленные ключи, но и сами строки, которые используются для ваших ключей. С строковые ключи в вашем случае "выиграют" с точки зрения объема памяти, потому что оба варианта будут хэшироваться в
- "String-numeric" ключи, такие как
'4', будет рассматриваться как целочисленные ключи и переведен в целое число результат хэша, поскольку это был целочисленный ключ. Таким образом,'4'=>'foo'и4 => 'foo'то же самое.
ulong (unsigned long) keys hash-map, поэтому реальная разница будет в значениях, где опция string-keys имеет целочисленные значения (фиксированная длина), а опция integer-keys имеет значения строк (зависящая от символов длина). Но это не всегда может быть правдой из-за возможных столкновений.
кроме того, важное примечание: графика здесь авторские права PHP internals book
хэш-карта для массивов PHP
массивы PHP и массивы C
вы должны понять одну очень важную вещь: PHP написан на C, где таких вещей, как" ассоциативный массив " просто не существует. Итак, в C "array" - это именно то, что" array " - т. е. это просто последовательная область в памяти, к которой можно получить доступ с помощью подряд смещение. Ваши "ключи" могут быть только числовыми, целыми и только последовательными, начиная с нуля. Вы не можете, например,3,-6,'foo' как ваши "ключи" есть.
поэтому для реализации массивов, которые находятся в PHP, есть опция хэш-карты, она использует хэш-функция to хэш ваши ключи и преобразовать их в целые числа, которые можно использовать для C-массивов. Однако эта функция никогда не сможет создать биекция между строковыми ключами и их число хэшируется результаты. И легко понять почему: потому что мощностью набора строк намного больше, чем мощность целого набора. Давайте проиллюстрируем на примере: мы пересчитаем все строки длиной до 10, которые имеют только буквенно-цифровые символы (так,0-9, a-z и A-Z, всего 62): это 6210 всего строк возможно. Это вокруг 8.39 E+17. Сравнить его с 4E+9 который у нас есть для типа unsigned integer (длинное целое число, 32 бита), и вы получите идею - будет конфликты.
PHP hash-ключи и коллизии карт
теперь, чтобы разрешить коллизии, PHP просто поместит элементы, которые имеют тот же результат хэш-функции, в один связанный список. Итак, hash-map не будет просто "список хэшированных элементов", но вместо этого он будет хранить указатели на списки элементов (каждый элемент в определенном списке будет иметь тот же ключ хэш-функции). И здесь вы должны указать, как это повлияет на распределение памяти: если Ваш массив имеет строковые ключи, которые не привели к столкновениям, то никаких дополнительных указателей внутри этого списка не потребуется, поэтому объем памяти будет уменьшен (на самом деле, это очень небольшие накладные расходы, но, поскольку мы говорим о точный память распределение, это следует учитывать). И точно так же, если ваши строковые ключи приведут ко многим коллизиям, то будет создано больше дополнительных указателей, поэтому общий объем памяти будет немного больше.
чтобы проиллюстрировать эти отношения в этих списках, вот график:
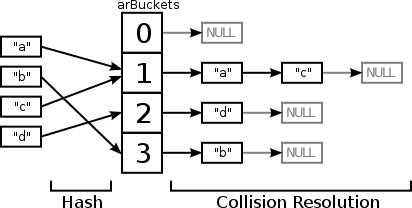
выше описано, как PHP будет разрешать коллизии после применения хэш-функции. Итак, одна из ваших частей вопроса лежит здесь, указатели внутри списков разрешения столкновений. Кроме того, элементы связанных списков обычно называются ведра и массив, содержащий указатели на главы этих списков, внутренне называется arBuckets. Из-за оптимизации структуры (так, чтобы сделать такие вещи, как удаление элемента, быстрее), реальный элемент списка имеет два указателя, предыдущий элемент и следующий элемент - но это только изменит объем памяти для массивов без столкновений/столкновений немного шире, но не изменит концепцию себя.
еще один список: порядка
чтобы полностью поддерживать массивы, как они есть в PHP, также необходимо поддерживать ордер, так что это достигается с другим внутренним списком. Каждый элемент массивов также является членом этого списка. Это не будет иметь значения с точки зрения распределения памяти, так как в обоих вариантах этот список должен поддерживаться, но для полной картины я упоминаю этот список. Вот графика:
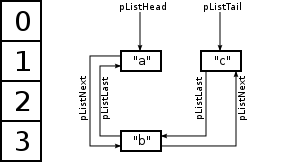
кроме pListLast и pListNext, сохраняются указатели на головку и хвост списка заказов. Опять же, это не напрямую связано с вашим вопросом, но дальше я дам внутреннюю структуру ведра, где присутствуют эти указатели.
элемент массива внутри
теперь мы готовы рассмотреть: что такое элемент массива, так, ведра:
typedef struct bucket {
ulong h;
uint nKeyLength;
void *pData;
void *pDataPtr;
struct bucket *pListNext;
struct bucket *pListLast;
struct bucket *pNext;
struct bucket *pLast;
char *arKey;
} Bucket;
здесь мы являются:
-
hявляется целочисленным (ulong) значением ключа, это результат хэш-функции. Для целых ключей это так же, как и сам ключ (хэш-функция возвращает себя) -
pNext/pLastявляются указателями внутри связанного списка разрешения столкновения -
pListNext/pListLastявляются указателями внутри связанного списка order-resolution -
pDataуказатель на сохраненное значение. На самом деле, value не совпадает с inserted at создание массива, это скопировать, но, чтобы избежать ненужных накладных расходов, PHP используетpDataPtr(т.pData = &pDataPtr)
С этой точки зрения вы можете получить следующее, где разница: так как строка ключа будет хэшироваться (таким образом,h всегда ulong и, следовательно, одинакового размера), это будет вопрос того, что хранится в значениях. Таким образом, для вашего массива string-keys будут целочисленные значения, в то время как для массива integer-keys будут строковые значения, и это делает разница. Тем не менее - нет, это не волшебная: вы не можете "сохранить память" с хранением строковых ключей таким образом все время, потому что, если ваши ключи будут большими, и их будет много, это вызовет накладные расходы (ну, с очень высокой вероятностью, но, конечно, не гарантировано). Он будет "работать" только для произвольных коротких строк, что не вызовет много коллизий.
хэш-таблица
об этом уже говорили элементы (ведра) и их структура, но есть и сама хэш-таблица, которая, по сути, является структурой данных массива. Итак, это называется _hashtable:
typedef struct _hashtable {
uint nTableSize;
uint nTableMask;
uint nNumOfElements;
ulong nNextFreeElement;
Bucket *pInternalPointer; /* Used for element traversal */
Bucket *pListHead;
Bucket *pListTail;
Bucket **arBuckets;
dtor_func_t pDestructor;
zend_bool persistent;
unsigned char nApplyCount;
zend_bool bApplyProtection;
#if ZEND_DEBUG
int inconsistent;
#endif
} HashTable;
я не буду описывать все поля, так как я уже предоставил много информации, которая связана только с вопросом, но я кратко опишу эту структуру:
-
arBucketsэто то, что было описано выше, ведра хранения, -
pListHead/pListTailуказатели на порядок-список разрешения -
nTableSizeопределяет размер хэш-таблицы. И это напрямую связано с выделением памяти:nTableSizeвсегда сила 2. Таким образом, неважно, будет ли у вас 13 или 14 элементов в массиве: фактический размер будет 16. Учитывайте это, когда хотите оценить размер массива.
вывод
это действительно трудно предсказать, будет один массив больше, чем другой в вашем случае. Да, есть рекомендации, которые следуя из внутренней структуры, но если строковые ключи сопоставимы по своей длине с целочисленными значениями (например,'four', 'one' в вашем примере) - реальная разница будет в таких вещах, как-сколько столкновений произошло, сколько байтов было выделено для сохранения значения.
но выбор правильной структуры должен быть вопросом смысла, а не Памяти. Если вы намерены построить соответствующие индексированные данные, то выбор всегда будет очевиден. Сообщение выше только об одной цели: показать, как массивы фактически работают в PHP и где вы можете найти разницу в распределении памяти в вашем примере.
вы также можете проверить статью о массивах и хэш-таблицах в PHP: это хэш-таблицы в PHP по PHP internals book: я использовал некоторые графики оттуда. Кроме того, чтобы понять, как значения выделяются в PHP, проверьте звал структуры статья, это может помочь вам понять, какие будут различия между строками & выделение целых чисел для значений ваших массивов. Я не включил объяснения из него здесь, так как гораздо более важный момент для меня - показать структуру данных массива и то, что может быть разницей в контексте строковых ключей/целочисленных ключей для вашего вопроса.
хотя оба массива доступны по-разному (т. е. через строку или целое значение), шаблон памяти в основном похож.
это потому, что распределение строк либо происходит как часть звал creation или когда новый ключ массива должен быть выделен; небольшая разница заключается в том, что числовые индексы не требуют всей структуры zval, потому что они хранятся как (без знака) долго.
наблюдаемые различия в распределении памяти настолько минимальны, что их можно в значительной степени объяснить либо неточностью memory_get_usage() или распределения из-за дополнительного создания ведра.
вывод
то, как вы хотите использовать свой массив, должно быть руководящим принципом при выборе того, как он должен быть индексирован; память должна стать исключением из этого правила только тогда, когда вы закончите его.
из PHP ручной сборки мусораhttp://php.net/manual/en/features.gc.php
gc_enable(); // Enable Garbage Collector
var_dump(gc_enabled()); // true
var_dump(gc_collect_cycles()); // # of elements cleaned up
gc_disable(); // Disable Garbage Collector
PHP не очень хорошо возвращает освобожденную память; его основное использование в Интернете не требует этого, и эффективная сборка мусора отнимает время от предоставления вывода; когда скрипт заканчивается, память все равно будет возвращена.
сборка мусора происходит.
-
когда вы говорите ему
int gc_collect_cycles ( void ) когда вы оставляете функцию
- когда скрипт заканчивается
лучшее понимание сборки мусора PHP с веб-узла (без принадлежности). http://www.sitepoint.com/better-understanding-phps-garbage-collection/
Если вы рассматриваете байт за байтом, как данные находятся в памяти. Различные порты будут влиять на эти значения. Производительность процессоров 64bit лучше всего, когда данные сидят на первом бит 64-битного слова. Для максимальной производительности конкретного двоичного файла они будут выделять начало блока памяти на первом бит, оставляя до 7 байтов неиспользуемыми. Этот конкретный процессор зависит от того, какой компилятор использовался для компиляции PHP.исполняемый. Я не могу предложить никакого способа предсказать точное использование памяти, учитывая, что она будет определяться по-разному разными компиляторами.
Alma Do, post переходит к специфике источника, который отправляется компилятору. Что запрашивает источник PHP и оптимизирует компилятор.
смотреть на конкретные примеры, которые вы выложили. Когда ключ является буквой ascii, они берут 4 байта (64 бита) больше на запись ... это наводит меня на мысль (при условии отсутствия мусора или дыр в памяти и т. д.), что ключи ascii больше 64 бит, но цифровые клавиши вписываются в 64-битное слово. Он предлагает мне использовать 64-битный компьютер и ваш PHP.exe компилируется для 64-битных процессоров.
массивы в PHP реализованы в виде хэш-карт. Следовательно, длина значения, используемого для ключа, мало влияет на требования к данным. В более старых версиях PHP наблюдалось значительное снижение производительности с большими массивами, поскольку размер хэша был зафиксирован при создании массива - при возникновении коллизий увеличивающееся количество хэш-значений сопоставлялось бы со связанными списками значений, которые затем нужно было дополнительно искать (с алгоритмом O(n)) вместо одного значения, но больше в последнее время хэш либо использует гораздо больший размер по умолчанию, либо изменяется динамически (он просто работает - я не могу беспокоиться о чтении исходного кода).
сохранение 4 байт из ваших скриптов не вызовет у Google бессонных ночей. Если вы пишете код, который использует большие массивы (где экономия может быть более значительной), вы, вероятно, делаете это неправильно - время и ресурс, необходимые для заполнения массива, могут быть лучше потрачены в другом месте (например, индексированы хранение.)