Агломеративная кластеризация в Matlab
у меня есть простой 2-мерный набор данных, который я хочу кластеризировать агломеративным образом (не зная оптимального количества кластеров для использования). Единственный способ, которым я смог успешно кластеризировать свои данные, - это дать функции значение "maxclust".
для простоты предположим, что это мой набор данных:
X=[ 1,1;
1,2;
2,2;
2,1;
5,4;
5,5;
6,5;
6,4 ];
естественно, я бы хотел, чтобы эти данные образовали 2 кластера. Я понимаю, что если бы я знал это, я мог бы просто сказать:
T = clusterdata(X,'maxclust',2);
и найти, какие точки попадают в каждый кластер я мог бы сказать:
cluster_1 = X(T==1, :);
и
cluster_2 = X(T==2, :);
но, не зная, что 2 кластера будут оптимальными для этого набора данных, как мне кластеризировать эти данные?
спасибо
2 ответов
весь смысл этого метода заключается в том, что он представляет кластеры, найденные в иерархии, и вам решать, сколько деталей вы хотите получить..
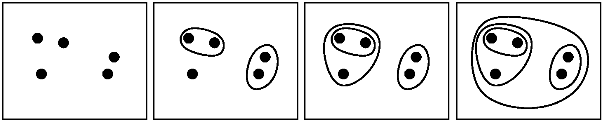
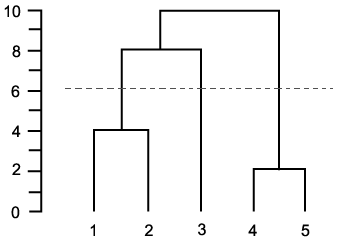
подумайте об этом как о горизонтальной линии, пересекающей дендрограмму, которая движется, начиная с 0 (каждая точка является собственным кластером) до максимального значения (все точки в одном кластере). Вы могли бы:
- остановка при достижении заданного количества кластеры (пример)
- вручную поместите его с определенным значением высоты (пример)
- выберите место, где кластеры слишком далеко друг от друга в соответствии с критерием расстояния (т. е. есть большой прыжок на следующий уровень) (пример)
Это можно сделать либо с помощью 'maxclust' или 'cutoff' аргументы функций CLUSTER / CLUSTERDATA
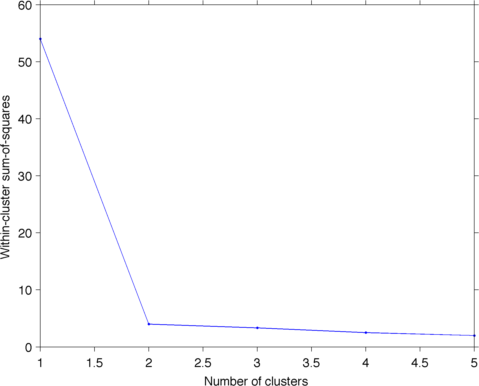
чтобы выбрать оптимальное количество кластеров, один общий подход-сделать участок похожим на участок осыпи. Затем вы ищете "локоть" в сюжете, и это количество кластеров, которые вы выбираете. Для критерия здесь мы будем использовать сумму квадратов внутри кластера:
function wss = plotScree(X, n)
wss = zeros(1, n);
wss(1) = (size(X, 1)-1) * sum(var(X, [], 1));
for i=2:n
T = clusterdata(X,'maxclust',i);
wss(i) = sum((grpstats(T, T, 'numel')-1) .* sum(grpstats(X, T, 'var'), 2));
end
hold on
plot(wss)
plot(wss, '.')
xlabel('Number of clusters')
ylabel('Within-cluster sum-of-squares')
>> plotScree(X, 5)
ans =
54.0000 4.0000 3.3333 2.5000 2.0000