Алгоритм распознавания жестов на основе дискретных точек
Я пытаюсь решить проблему сопоставления человеческого сгенерированного жеста с известным жестом. Созданный человеком жест будет представлен последовательностью точек, которые необходимо будет интерполировать в путь и сравнить с существующим путем. Изображение ниже показывает, что я пытаюсь сравнить 
не могли бы вы помочь указать мне в правильном направлении с ресурсами или концепциями, которые я могу прочитать, чтобы построить алгоритм, соответствующий этим двум путям? У меня нет опыт в этом, прежде чем так любые идеи будут оценены.
1 ответов
прием ввод
измерьте вход на некотором интервале. Каждые xx миллисекунд измерьте координаты руки/пальца/стилуса пользователя.
сохранение шаблонов и ввода
Шаблоны (ожидаемый ввод)
изменить шаблон. В настоящее время это непрерывная "функция", но измерение ввода как такового затруднено. Используйте дискретные точки На некотором интервале. Этот интервал can быть очень коротким, в зависимости от того, насколько точно вы требуется жесты, чтобы быть. На самом деле, он должен быть очень коротким; чем больше точек для сравнения, тем лучше (я объясню это немного лучше в следующем разделе).
вход (получен от пользователя)
при измерении входного сигнала интервал ввода-измерения должен быть достаточно коротким, чтобы каждая полученная последовательная пара входных точек была достаточно близка для сравнения с ожидаемыми точками.
представьте, что пользователь выполняет какой-то жест очень быстро (и завершает это в то время, когда ваш input-reader читает только три кадра). Шаблон и вход не могут быть надежно сопоставлены:
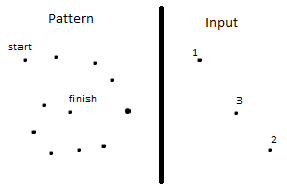
чтобы избежать этого, ваш считыватель должен иметь относительно короткий интервал. Однако это, вероятно, не является большой проблемой, так как большинство аппаратных средств может читать даже самые быстрые человеческие жесты.
назад к шаблонам: они всегда должны быть достаточно подробными, чтобы включать больше точек, чем любой возможный вход. Больше ожидаемых очков позволяют лучше точность. Если пользователь движется медленно, на входе будет больше точек; если они двигаются быстро, на входе будет меньше.
подумайте об этом: завершение одного жеста дает вам вдвое меньше входных кадров, чем включает шаблон. Пользователь двигался с" нормальной " скоростью, поэтому, чтобы упростить алгоритм, вы можете "заглушить" свой шаблон в 2 раза, а затем напрямую сравнить входные координаты с координатами шаблона.
этот метод проще, чем альтернатива, которая приходит к ум (см. Следующий раздел).
шаблон "плотность" (координатная частота)
если у вас есть небольшое количество, но вам придется сделать приближений для согласования входа.
вот "экстремальный" пример, но это доказывает концепцию. Учитывая этот шаблон и ввод:
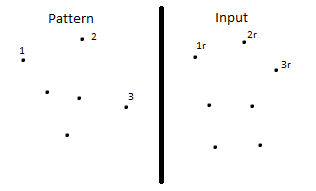
пункт 3r нельзя надежно сравнить с пунктом 2 или пунктом 3, поэтому вам нужно использовать некоторую функцию пунктов 2, 3 и 3r, чтобы определить, является ли 3r на правильном пути. Теперь рассмотрим тот же вход, но где шаблон имеет более высокую плотность:
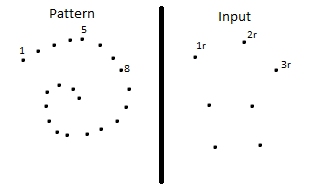
теперь вам не нужно идти на компромисс, так как 3r по существу наверняка по шаблону жеста. Небольшое снижение плотности рисунка заставляет его довольно хорошо соответствовать входным данным.
позиционирование
относительное позиционирование
вместо сравнения абсолютных позиций (например, на сенсорном экране), вы вероятно, хотят, чтобы жест был разрешен в любом месте на какой-то плоскости пространства. Для этого необходимо связать начальную точку входных данных с некоторой системой координат.
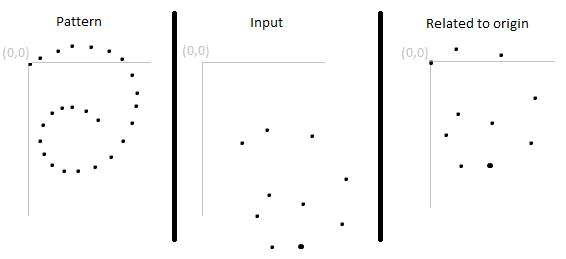
нормализация
чтобы быть удобным для пользователя, позвольте жестам выполняться в диапазоне "размеров". Вы не хотите сравнивать необработанные данные, потому что, скорее всего, размер плоскости ввода не соответствует размеру плоскости шаблона.
нормализовать вход в x-и y-направлении, чтобы соответствовать размеру вашего шаблона. Do не сохранить пропорции.
- связать входные данные с системой координат, как в предыдущем пуле
- найти наибольшее горизонтальное и вертикальное расстояние между двумя вход точек (назовем их
RecMaxHиRecMaxV) - найти наибольшее горизонтальное и вертикальное расстояние между двумя шаблон точек (назовем их
ExpMaxHиExpMaxV) - умножьте x-координаты всех входных точек на
ExpMaxH/RecMaxH - несколько y-координат всех входных точек по
ExpMaxV/RecMaxV
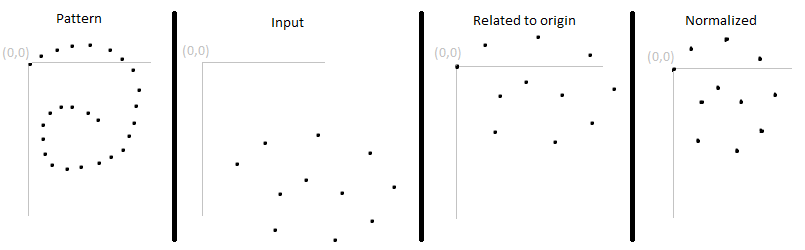
теперь у вас есть еще два похожих набора точек, которые можно сравнить. Нормализация может быть намного более подробной; например, вы можете нормализовать наборы из 3 точек за раз, чтобы получить невероятно похожие изображения (но вам, вероятно, придется сделать это для каждого шаблона, а затем сравнить сумму из всех различий найти наиболее вероятный соответствующий шаблон).
Я предлагаю хранить шаблон всех жестов в виде графика одинакового размера; это уменьшает вычисление при измерении близости ввода к возможным совпадениям шаблонов.
когда измерять вход
пользователем
представьте себе кнопку, которая при нажатии / активации заставляет вашу программу начинать измерение входов. Это будет похоже на голосовой поиск Google, который не постоянно запись и поиск; вместо этого вы говорите "Ок Джарвис" или нажмите значок удобного микрофона и начните говорить свой запрос.
преимущества:
- упрощает алгоритм
- предотвращает непреднамеренное инициирование события пользователем. Представьте, что каждое сказанное вами слово было проанализировано и отправлено в Google как часть поискового запроса. Иногда ты просто ничего не хочешь делать.
недостатки:
- менее удобный. Пользователь должен идти из его / ее пути, чтобы вызвать запись для жестов.
если вы пишете, например, поиск жестов (смешной пример), это, вероятно, лучший метод для реализации. Никто не хочет, чтобы каждый их шаг интерпретировался как действие в вашем приложении. Однако, если вы пишете игру в стиле Kinect или на основе жестов, вы, вероятно, хотите постоянно записывать и искать жесты.
постоянный
ваша программа constatly записывает координаты жестов на заданном интервале (это может быть уменьшено до "записи, если есть движение, в противном случае не сохраняет координаты"). Вы должны принять решение: сколько "кадров" вы будете записывать, пока не решите, что сохраненное в данный момент движение не является признанным жестом?
хранить координаты в буфере: очередь 1.5 или 2 (чтобы быть осторожным) раз до тех пор, как наибольшее количество кадров вы готовы записать.
как только вы определяете что в этом буфере существует последовательность кадров, которые соответствуют шаблону, выполняют результат этого жеста и очищают очередь.
если есть возможность, что следующий жест является " опцией "для самого последнего жеста, запишите состояние приложения как" в настоящее время ожидание опции для ____ жеста " и дождитесь появления опции.
если определено, что первые X кадров в буфере не могут соответствовать шаблону (из-за их последовательности или расположения) удалите их из очереди.
преимущества:
- позволяет более динамичную обработку жестов
- ввод пользователя распознается автоматически
недостатки:
- более сложный алгоритм
- более тяжелые вычисления
если вы пишете игру, которая работает на основе ввода в режиме реального времени, это, вероятно, правильно выбор.
алгоритм
если вы используете пользовательское распознавание:
- запишите все входные данные в разрешенный таймфрейм (или пока пользователь не подаст знак, что они сделаны)
- чтобы оценить вход, уменьшите плотность вашего шаблона, чтобы соответствовать входу
- связать входные данные с системой координат
- нормализует входной сигнал
- используйте метод сравнения функций (слабость этого расчет зависит от вас: стандартное отклонение, дисперсия, общая разница в значениях и т. д.) и выбрать наименее-разные возможности.
- если нет возможности, достаточно похожей, чтобы соответствовать требуемому порогу (вы должны решить это), не принимайте вход.
если вы используете постоянное измерение:
в вашем буфере обработайте последовательность max_sequence_size (вы решаете), начиная с каждый кратный frame_multiples (вам решать) как возможный жест. Например, если все мои возможные жесты имеют длину не более 20 кадров, и я считаю, что каждые 5 кадров может начинаться новый жест (и я не потеряю никаких критических данных в этих 5 кадрах), я буду сравнивать каждую часть буфера со всеми возможными жестами (части от 0-19, 5-24, 10-29 и т. д.). Это более тяжелые вычисления, когда frame_multiples уменьшается. Для идеального измерения frame_multiples равно 1 (но это, вероятно, не разумно).
надеюсь, вы мне понравилось читать этот ответ так же, как и писать его. Я никогда не делала этого раньше, но ты пробудил мой интерес к тебе, что случается не часто. пожалуйста редактировать и улучшать мой ответ! Если есть часть, которая кажется неполной, добавьте к ней. Мне очень любопытны (особенно, более опытные) ответы и критика.