Алгоритмы Кластеризации На Python
Я искал scipy и sklearn для алгоритмов кластеризации для конкретной проблемы, которую у меня есть. Мне нужен какой-то способ характеризовать популяцию N частиц в k групп, где k не обязательно знать, и в дополнение к этому не известны априорные длины связывания (похожие на это вопрос).
Я пробовал kmeans, который хорошо работает, если вы знаю сколько кластеров вы хотите. Я пробовал dbscan, который плохо работает если только ты ... --5-->рассказать это характерная шкала длины, на которой можно перестать искать (или начать искать) кластеры. Проблема в том, что у меня есть потенциально тысячи таких кластеров частиц, и я не могу тратить время, чтобы сказать алгоритмам kmeans/dbscan, что они должны уйти.
вот пример того, что dbscan найти:
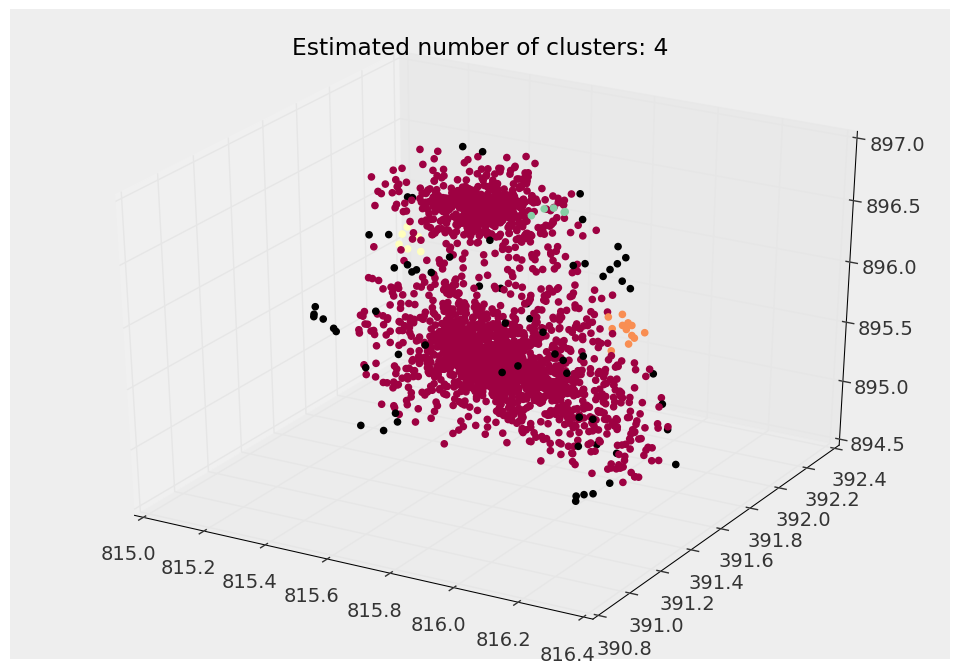
вы можете видеть, что здесь действительно есть две отдельные популяции, хотя корректировка фактора Эпсилона ( максимум. расстояние между соседними кластерами), я просто не могу заставить его увидеть эти две популяции частиц.
есть ли другие алгоритмы, которые будут работать здесь? Я ищу минимальную информацию заранее - другими словами, Я хотел бы, чтобы алгоритм мог принимать "умные" решения о том, что может составлять отдельный кластер.
4 ответов
Я нашел тот, который не требует априорной информации/догадок и делает очень хорошо для того, что я прошу его сделать. Это называется Среднее Смещение и находится в SciKit-Learn. Это также относительно быстро (по сравнению с другими алгоритмами, такими как распространение сродства).
вот пример того, что это дает:
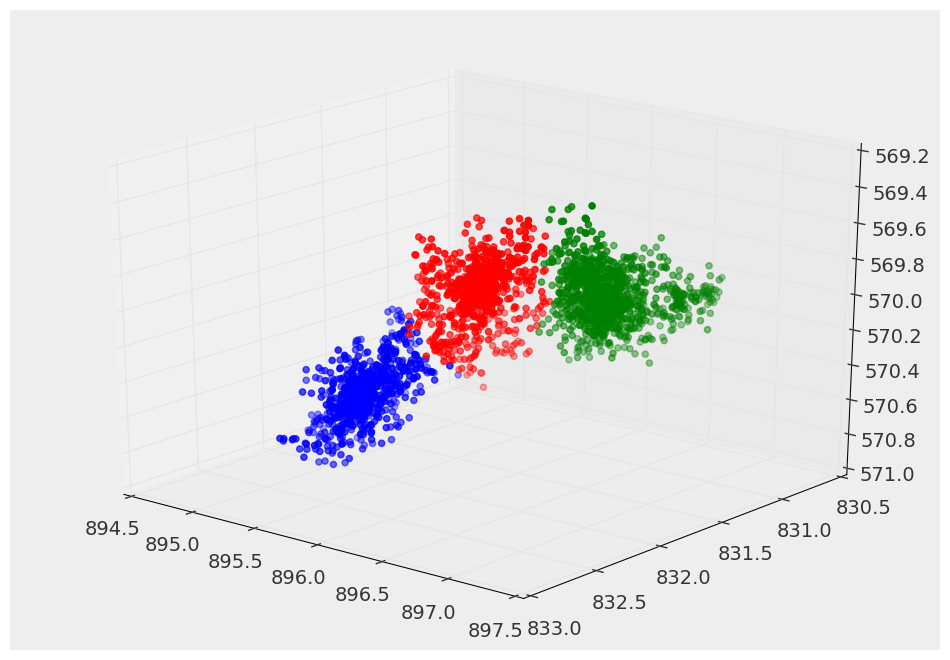
Я также хочу отметить, что в документации говорится, что это не хорошо.
при использовании DBSCAN может быть полезно масштабировать / нормализовать данные или расстояния заранее, так что оценка Эпсилона будет относительной.
существует реализация DBSCAN-я думаю, что это один Anony-мусс где-то обозначается как "плавающий вокруг" -, который приходит с функцией оценки Эпсилона. Он работает, пока его не кормят с большими наборами данных.
есть несколько неполные версии of Оптика в github. Возможно вы можете найти один, чтобы приспособить его для ваших целей. До сих пор пытаюсь выяснить, какой эффект имеет minPts, используя один и тот же метод извлечения.
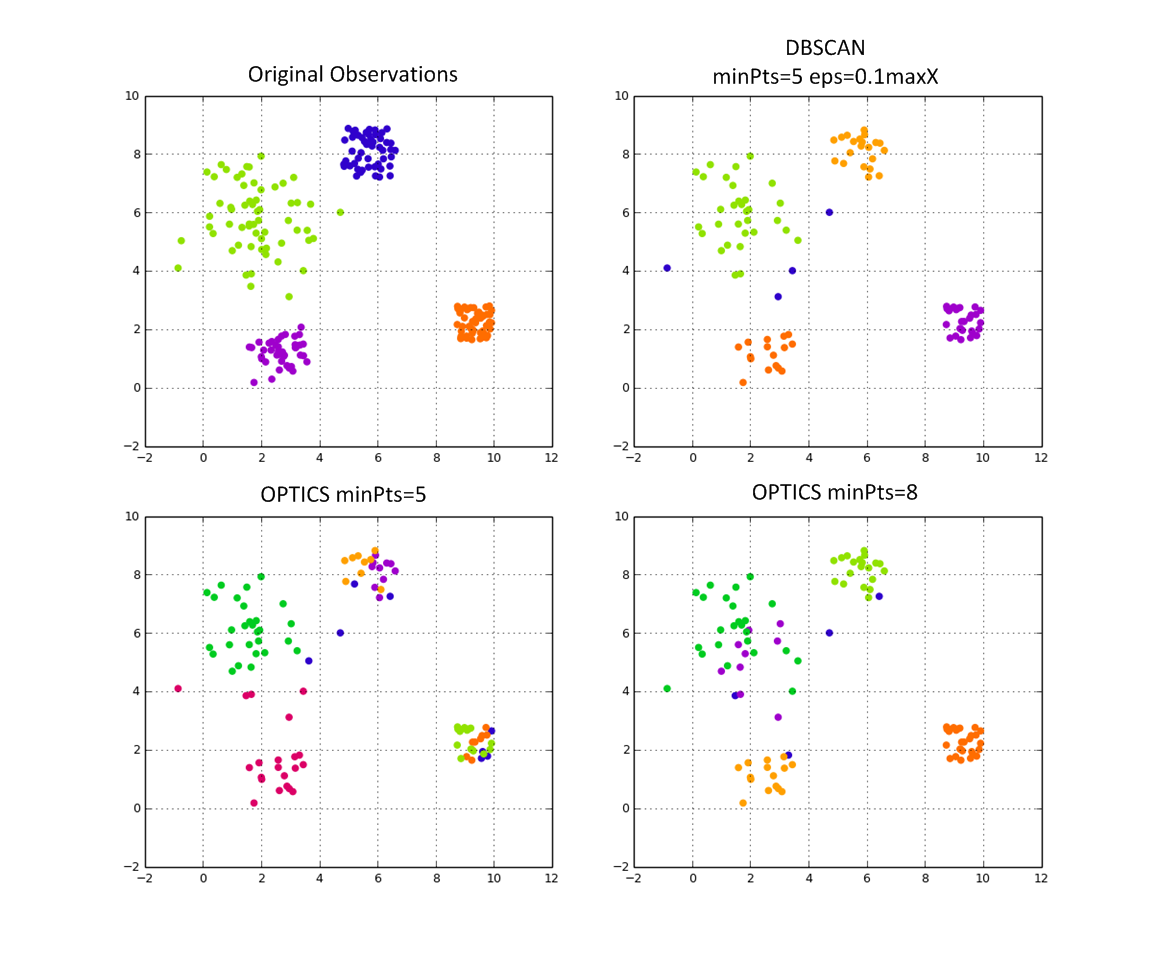
вы можете попробовать минимальное связующее дерево (алгоритм zahn), а затем удалить самый длинный край, похожий на альфа-фигуры. Я использовал его с триангуляцией Делоне и вогнутым корпусом:http://www.phpdevpad.de/geofence. Можно также попробовать иерархический кластер, например clusterfck.
ваш сюжет указывает, что вы выбрали minPts параметр путь слишком мал.
посмотрите на оптику, которой больше не нужен параметр epsilon DBSCAN.