Анализатор Prolog-DCG со входом из файла
в рамках проекта мне нужно написать парсер, который может читать файл и анализировать факты, которые я могу использовать в своей программе.
структура файла выглядит следующим образом:
property = { el1 , el2 , ... }.
что я хочу в конце:
property(el1).
property(el2).
...
Я читаю свой файл так:
main :-
open('myFile.txt', read, Str),
read_file(Str,Lines),
close(Str),
write(Lines), nl.
read_file(Stream,[]) :-
at_end_of_stream(Stream).
read_file(Stream,[X|L]) :-
+ at_end_of_stream(Stream),
read(Stream,X),
parse(X), % Here I call upon my parser.
read_file(Stream,L).
теперь я прочитал в нескольких книгах и в интернете о DCG, но все они объясняют те же простые примеры, где вы можете генерировать предложения, такие как "кошка ест летучую мышь" и т. д... Когда я хочу чтобы использовать его для приведенного выше примера, я терплю неудачу.
мне удалось "разобрать" нижнюю строку:
property = el1.
to
property(el1).
С этого:
parse(X) :-
X =.. List, % Reason I do this is because X is one atom and not a list.
phrase(sentence(Statement), List),
asserta(Statement).
sentence(Statement) --> ['=', Gender, Person] , { Statement =.. [Gender, Person] }.
Я даже не знаю, правильно ли я использую dcg здесь, поэтому любая помощь в этом будет оценена. Теперь проблема в том, как это сделать с несколькими элементами в моем списке и как обрабатывать " {"и"}".
Что я действительно хочу, это dcg, который может справиться с этим типы предложений (с более чем 2 элементами): 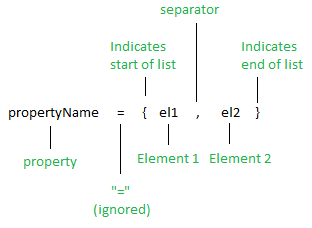
теперь я знаю, что многие люди здесь ссылаются на библиотеки dcg_basics и pio, когда дело доходит до dcgs. Однако у меня есть дополнительная проблема, что при попытке использовать библиотеку я получаю сообщение об ошибке:
ERROR: (c:/users/ldevriendt/documents/prolog/file3.pl:3):
Type error: `text' expected, found `http/dcg_basics'
Warning: (c:/users/ldevriendt/documents/prolog/file3.pl:3):
Goal (directive) failed: user:[library(http/dcg_basics)]
когда я делаю это:
:- [library(http/dcg_basics)].
дополнительная информация:
- я использую программы: SWI-Prolog-редактор в среде Windows.
любой помощь в этом будет оценена!
EDIT: цель этого вопроса-узнать больше о DCG и его использовании в парсерах.
4 ответов
пока ваш файл находится в простом синтаксисе Prolog, вам рекомендуется использовать термин Prolog IO. Полностью структурированные термины читаются с помощью один звонок. Использование DCG его путь более сложный и немного менее эффективный (не уверен, что здесь следует измерять, но read (Term) вызывает парсер пролога, реализованный в C...) Этот другой вопрос, который использует тот же самый формат (по крайней мере, вы можете проверить, получил ли какой-то другой парень ответ здесь, так о вашем же назначение...)
редактировать после комментариев...
вы правы, что DCG являются право способ обработки общего анализа в прологе. Аргументы в производствах DCG можно рассматривать как семантические атрибуты, поэтому программирование DCG можно рассматривать как предоставление работающего семантический анализ на входе (см. Атрибут Грамматики, важная техника-также-в языковой инженерии).
и действительно, представленные примеры могут прекрасно решается без хаков, необходимых с термином IO.
вот это:
:- use_module(library(pio)). % autoload(ed), added just for easy browsing
:- use_module(library(dcg/basics)).
property(P) -->
b, "my props", b, "=", b, "{", elS(Es) , b, "}", b,
{ P =.. [property|Es] }.
elS([E|Es]) --> el(E), b, ("," -> elS(Es) ; {Es = []}).
el(N) --> number(N).
el(S) --> csym(S). % after Jeremy Knees comment...
b --> blanks.
% parse a C symbol
csym(S) -->
[F], { code_type(F, csymf) },
csym1(Cs),
!, { atom_codes(S, [F|Cs]) }.
csym1([C|Cs]) -->
[C], { code_type(C, csym) },
csym1(Cs).
csym1([]) --> [].
С этим у нас есть
?- phrase(property(P), "my props = {1,2,3}").
P = property(1, 2, 3).
благодаря библиотеке(pureio) мы можем применить семантическое Программирование к потокам пролога и получить вознаграждение за такое же поведение фразы/2.
больше
этой другого ответа показать практический способ реализации калькулятора выражений с разрешением оператора и ленивый оценка.
Ну, цель домашку учиться. Выполнение этого с DCG научит вас более полезному навыку, чем хорсинг операторов.
Я думаю, что ваши проблемы меньше с DCG по своей сути, чем с обработкой строк.
У вас есть куча мест, где вы используете univ (=.. operator) для преобразования между списками и строками. Univ, вероятно, не то, что вы хотите здесь. Университет объединяет термин со списком.
foo(bar, baz) =.. [foo, bar, baz]
что нужно поймите, что строка в Prolog может быть в нескольких разных формах Строка "привет, Флорес" может быть
'привет Флорес' - это атом - "твердый кусок" вещи. Одинарные кавычки не нужны для некоторых последовательностей символов( см. вашу книгу), поэтому hi_flores-отличный атом без одинарных кавычек.
[104,105,32,70,108,111,114,101,115] - a list of ASCII codes. This is likely what you want. These can be written with double quotes, "hi Floris" in prolog code.
To save your sanity, put
:- portray_text(true).
в вашем файле, чтобы он печатал "привет, Флорис" в отладке, а не кучу чисел.
есть также список из одного символа атомы!--4-->
[h, i,'', 'F', l, o, r, i, s]
но вы, вероятно,не хотите их.
вы можете найти sicstus compatability pred read_line полезным.
Теперь, в DCG, вы иногда хотите соответствовать "литералам" - буквально этой вещи. Если да, внесите это в список. Вот DCG для операторов if на каком-то неопределенно VBish языке
if_statement --> "if", wh, "(", condition, ")", wh,
"then", wh, body, wh, "else", wh,
else_body, wh, "endif".
% whitespace
wh --> [].
wh --> " ", wh.
wh --> [10], wh. % handle newline and cr
wh --> [12], wh.
wh везде являются необязательными пробелами.
Теперь, для общей стратегии, вы можете либо читать по одной строке за раз, либо читать во всем файле. Для одной строки, read_line, который возвращает список кодов. read_file_to_codes получит весь файл.
Если вы используете всю стратегию файла, и новые строки значительны, вам нужно будет удалить их из определения пробелов, очевидно.
и, конечно, все это приводит к вопросу, почему вопросы об этой проблеме наводняют так, а не инструктора в коробке.
Я анализирую строку в список, а затем манипулирую списком. Используя DCG, вы можете конвертировать
T = (saf>{saf, as13s}>a32s>asf).
to
S = [saf-0, saf-1, as13s-1, a32s-2, asf-3] .
Примечание делать:
1. parseLine(<<Yourpattern>>,Position) --> parseLine(L,Position), parseLine(R,NewPosition)
2. parseLine(Item,Pos) --> [Item-Pos].
здесь у вас есть 2 шаблона для обработки: (L>R) и {L,R}. Это будет не так уж сложно и легко прочесть.
IMHO, правила грамматики DCG довольно уродливы при токенизации, я действительно думаю, что DCG никогда не должен был даже предлагаться для этой задачи; реальная сделка с DCG заключается в анализе токенов, потому что prolog использует символику, поэтому я могу сказать, что лучший вариант-создать иностранный вызов, скажем, c tokenizer, который объединится с простым списком токенов, а затем пусть DCG делает то, что он Таким образом, реализация чище, и вам не нужно беспокоиться о разборе cr, пробелов...
скажем, у вас есть гипотетический язык, который имеет утверждение, которое выглядит следующим образом:
object:
object in a yields b,
object in b yields C.
Я не хочу даже представить себе, что это означает в DCG; я слишком ленив, чтобы узнать, как это сделать с помощью инструмента, который не предназначен для такой задачи. Лучше было бы иметь иностранный вызов предиката, который предоставит мне простой список токенов.
tokenize(A,ListOfTokens), phrase(yourDGCstartRule(Information), ListOfTokens, _).
список для нашего примера будет выглядеть просто как:
ListOfTokens = [object,:,object,in,a,yields,b,',',object,in,b,yields,c].
I подумайте, что это намного более элегантно,и ваши правила соответствуют. Я могу ошибаться в своих мыслях, но в конце концов это вопрос вкуса, и для меня DCG не является токенизатором, и я никогда не буду использовать его для этого, если это строго не требуется. По общему признанию, я могу найти некоторые приложения, где было бы целесообразно использовать его также как токенизатор, но все же я думаю, что задачи должны быть разделены.
обратите внимание, что я не говорю, что у prolog нет хороших возможностей, вы всегда можете это сделать токенизация в прологе, но вы должны разделить задачи и позволить DCG иметь дело только с символами и некоторыми другими строго необходимыми символами или строками (как строки верхнего регистра, например, имена собственные или другие символы).
наконец, мне кажется, что люди, возможно, забыли, что токенизация и синтаксический анализ-это две отдельные задачи; больше в прологе, так как токены-это символы, в которых пролог хорош, и разбор токенов / символов (не символов), что DCG делает лучше, для как embeeded семантики интерфейсы prolog, который является желаемым сценарием.