ARM сидит без дела, пока NEON делает свои операции?
может выглядеть примерно так: рука и неон могут работать параллельно?, но это не так, у меня несколько другая проблема ( может быть проблема с моим пониманием):
в стеке протоколов, пока мы вычисляем контрольную сумму, которая выполняется на GPP, я передаю эту задачу NEON как часть функции:
вот функция контрольной суммы, которую я написал как часть NEON, опубликованная в Stack Overflow:реализация кода контрольной суммы для Neon in Встроенные функции
теперь предположим, что из linux эта функция называется,
ip_csum(){
…
…
csum = do_csum(); //function call from arm
…
…
}
do_csum(){
…
…
//NEON optimised code
…
…
returns the final checksum to ip_csum/linux/ARM
}
в этом случае.. что происходит с ARM, когда NEON делает вычисления? рука сидит без дела? или он переходит к другим операциям?
Как вы можете видеть, вызывается do_csum, и мы ждем этого результата (или это то, что он выглядит)..
Примечание:
- на языке Cortex-А8
- do_csum, как вы можете см. из ссылки закодировано с помощью intrinsics
- компиляция с использованием GNU tool-chain
- будет хорошо, если вы также возьмете многопоточность или любую другую концепцию или войдете в картину, когда эти операции inter происходят.
вопросы:
- ARM сидит без дела, пока NEON делает свои операции? ( в данном случае)
- или его отложить текущего кода ip_csum, и взять другой процесс / поток, пока неон не будет сделан? (Я почти не понимаю, что здесь происходит)
- если он сидит без дела, как мы можем заставить руку работать над чем-то еще, пока неон не будет сделан?
3 ответов
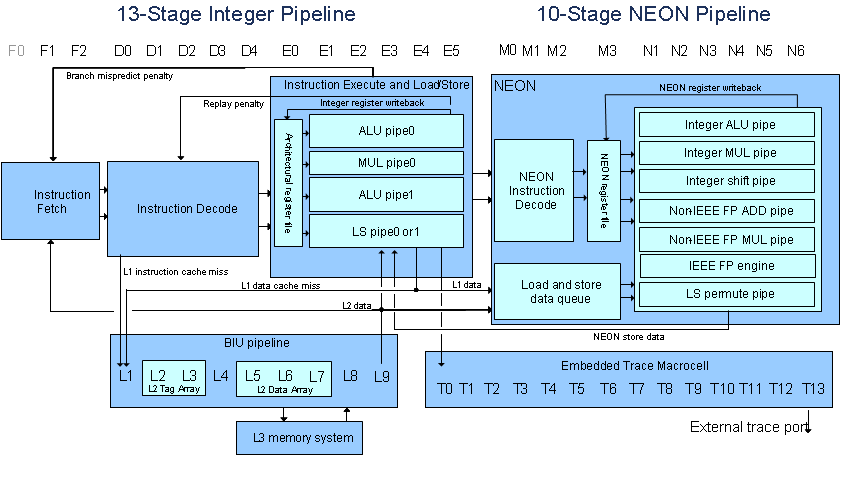
(Изображение с TI Wiki Cortex A8)
ARM (или, скорее, целочисленный конвейер) не простаивает во время обработки неоновых инструкций. В коре A8 неон находится в "конце" конвейера процессора, инструкции проходят по конвейеру, и если они являются инструкциями ARM, они выполняются в "начале" конвейера, а неоновые инструкции выполняются в конце. Каждые часы нажимают инструкцию вниз трубопровод.
вот несколько советов о том, как читать диаграмму выше:
- каждый цикл, если это возможно, процессор извлекает пару команд (две инструкции).
- выборка по конвейеру, поэтому для распространения инструкций в блок декодирования требуется 3 цикла.
- для декодирования инструкции требуется 5 циклов (D0-D4). Опять же, это все конвейеры, поэтому это влияет на задержку, но не на пропускную способность. Больше инструкций keep течет по трубопроводу, где это возможно.
- теперь мы достигаем части execute / load store. Неоновые инструкции проходят через этот этап (но они делают это, пока другие инструкции, возможно, выполняются).
- мы добираемся до неоновой части, если инструкция, полученная 13 циклов назад, была неоновой инструкцией, теперь декодируется и выполняется в неоновом конвейере.
- пока это происходит, целочисленные инструкции, которые следовали за этой инструкцией, могут выполняться одновременно в конвейере integer.
- конвейер является довольно сложным зверем, некоторые инструкции являются многоцикловыми, некоторые имеют зависимости и будут останавливаться, если эти зависимости не выполняются. Другие события, такие как ветви, сбросят трубопровод.
Если вы выполняете последовательность, которая является 100% неоновыми инструкциями (что довольно редко, так как обычно участвуют некоторые регистры ARM, поток управления и т. д.) тогда есть некоторый период, когда конвейер integer не делает ничего полезного. Большинство кодов будут выполняться одновременно, по крайней мере, в течение некоторого времени, в то время как искусно спроектированный код может максимизировать производительность при правильном сочетании инструкций.
этот онлайн-инструмент счетчик циклов для Cortex A8 отлично подходит для анализа производительности вашего кода сборки и дает информацию о том, что выполняется в каких единицах и что тормозит.
ARM не "простаивает" при выполнении неоновых операций, но управления них.
Чтобы полностью использовать мощность обоих блоков, можно тщательно спланировать чередующуюся последовательность операций:
loop:
SUBS r0,r0,r1 ; // ARM operation
addpq.16 q0,q0,q1 ; NEON operation
LDR r0, [r1, r2 LSL #2]; // ARM operation
vld1.32 d0, [r1]! ; // NEON operation using ARM register
bne loop; // ARM operation controlling the flow of both units...
ARM cortex-A8 может выполнять в каждом такте до 2 инструкций. Если оба они являются независимыми неоновыми операциями, нет смысла помещать инструкцию ARM между ними. OTOH если известно, что задержка VLD (нагрузки) велика, можно разместить много инструкций ARM между загрузкой и первым использованием загруженного значения. Но в каждом случае комбинированное использование должно планироваться заранее и чередоваться.
на Application Level Programmers’ Model, вы не можете действительно различить между ARM и неоновыми единицами.
в то время как NEON является отдельным аппаратным блоком (который доступен в качестве опции на серии Cortex-A процессоры), это ядро ARM, которое управляет им в жесткой форме. Это не отдельный DSP, который вы можете общаться асинхронным способом.
вы можете написать лучший код, полностью используя конвейеры на обоих блоках, но это не то же самое, что иметь отдельное ядро.
неон блок есть, потому что он может выполнять некоторые операции (SIMDs) намного быстрее, чем блок ARM на низкой частоте.
любой, кто говорит, что ARM core может делать другие вещи, пока NEON core работает над своим материалом, говорит о параллелизм на уровне инструкций не нравится задачи программы.