Большой-О для восьмилеток? [дубликат]
этот вопрос уже есть ответ здесь:
Я спрашиваю больше о том, что это значит для моего кода. Я понимаю концепции математически, мне просто трудно понять, что они означают концептуально. Например, если чтобы выполнить операцию O(1) над структурой данных, я понимаю, что количество операций, которые она должна выполнить, не будет расти, потому что есть больше элементов. И операция O(n) будет означать, что вы будете выполнять набор операций над каждым элементом. Кто-нибудь может заполнить пробелы?
- например, что именно будет делать операция O(n^2)?
- и что, черт возьми, это значит, если операция O(N log(n))?
- и кто-то должен курить крэк, чтобы напишите O (x!)?
25 ответов
один из способов думать об этом так:
о(N^2) означает, что для каждого элемента, вы делаете что-то с каждым другим элементом, например, сравнивая их. Примером этого является сортировка пузырьков.
O (N log N) означает, что для каждого элемента вы делаете то, что нужно только посмотреть на log N элементов. Обычно это происходит потому, что вы знаете что-то об элементах, которые позволяют вам сделать эффективный выбор. Примером этого являются наиболее эффективные виды, такие как merge род.
O (N!) означает сделать что-то для всех возможных перестановок N элементов. Коммивояжер является примером этого, где есть N! способы посещения узлов, а решение грубой силы-посмотреть на общую стоимость каждой возможной перестановки, чтобы найти оптимальную.
большая вещь, которую означает обозначение Big-O для вашего кода, - это то, как он будет масштабироваться, когда вы удвоите количество "вещей", с которыми он работает. Вот конкретный пример:
Big-O | computations for 10 things | computations for 100 things ---------------------------------------------------------------------- O(1) | 1 | 1 O(log(n)) | 3 | 7 O(n) | 10 | 100 O(n log(n)) | 30 | 700 O(n^2) | 100 | 10000
Итак, возьмите quicksort, который является o(n log(n)) vs bubble sort, который является O (n^2). При сортировке 10 вещей quicksort в 3 раза быстрее, чем сортировка пузырьков. Но при сортировке 100 вещей это в 14 раз быстрее! Очевидно, что выбор самого быстрого алгоритма важен. Когда вы попадаете в базы данных с миллионом строк, он может означает разницу между выполнением запроса за 0,2 секунды и занятием часов.
еще одна вещь, которую следует учитывать, что плохой алгоритм-это то, что закон Мура не может помочь. Например, если у вас есть какой-то научный расчет, который O(n^3), и он может вычислять 100 вещей в день, удвоение скорости процессора дает вам только 125 вещей в день. Тем не менее, сбейте этот расчет до O (n^2), и вы делаете 1000 вещей a день.
пояснение: На самом деле, Big-O ничего не говорит о сравнительной производительности разных алгоритмов в одной и той же конкретной точке размера, а скорее о сравнительной производительности одного и того же алгоритма в разных точках размера:
computations computations computations Big-O | for 10 things | for 100 things | for 1000 things ---------------------------------------------------------------------- O(1) | 1 | 1 | 1 O(log(n)) | 1 | 3 | 7 O(n) | 1 | 10 | 100 O(n log(n)) | 1 | 33 | 664 O(n^2) | 1 | 100 | 10000
возможно, Вам будет полезно визуализировать его:
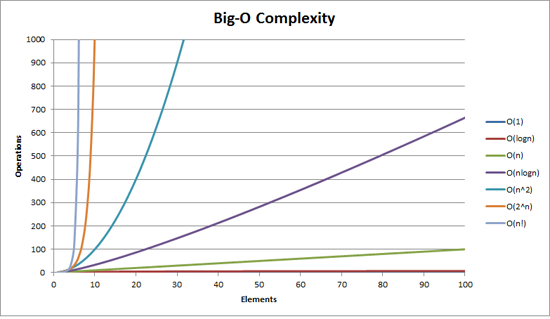
кроме того, on LogY / LogX шкала функции n1/2, n, n2 все выглядят как прямые линии, в то время как на LogY / X масштаб 2n, en, 10n - прямые линии и n! является линеарифмическим (выглядит как N log n).
Это может быть слишком математически, но вот моя попытка. (Я am математик.)
Если что-то O (f(n)), то это время на n элементы будут равны на f(n) + B (измеряется, скажем, тактовыми циклами или операциями процессора). Это ключ к пониманию того, что у вас также есть эти константы на и B, которые возникли от конкретная реализация. B представляет собой по существу "постоянные накладные расходы" вашей операции, например некоторую предварительную обработку, которую вы делаете, которая не зависит от размера коллекции. на представляет скорость вашего фактического алгоритма обработки элементов.
ключ, однако, заключается в том, что вы используете Big O notation, чтобы выяснить как хорошо что-то будет масштабироваться. Таким образом, эти константы не будут иметь большого значения: если вы пытаетесь выяснить, как масштабировать от 10 до 10000 предметов, кого волнуют постоянные накладные расходы B? Аналогично, другие проблемы (см. ниже), безусловно, перевешивают вес мультипликативной константы на.
Так что реальная сделка f(n). Если f растет совсем не с n, например,f(n) = 1, то вы будете масштабировать фантастически- - - ваше время работы всегда будет просто на + B. Если f растет линейно с n, то есть f(n)= n, ваше время работы будет масштабироваться почти так же хорошо, как можно ожидать---если ваши пользователи ждут 10 НС для 10 элементов, они будут ждать 10000 НС для 10000 элементов (игнорируя аддитивную константу). Но если он растет быстрее, как n2, тогда вы в беде; вещи начнут замедляться слишком много, когда вы получите большие коллекции. f(n)= n log (n) - хороший компромисс, как правило: ваша операция не может быть настолько простой, чтобы дать линейное масштабирование, но вам удалось сократить вещи так, что она будет масштабироваться намного лучше, чем f(n)= n2.
практически, вот несколько хороших примеров:
- O (1): извлечение элемента из массива. Мы точно знаем, где он находится в памяти, так мы просто возьмем его. Не имеет значения, имеет ли коллекция 10 элементов или 10000; она все еще находится в индексе (скажем) 3, поэтому мы просто переходим к местоположению 3 в памяти.
- O (n): извлечение элемента из связанного списка. Вот,на = 0.5, потому что в среднем вам придется пройти 1/2 связанного списка, прежде чем вы найдете элемент, который ищете.
- O (n2): различные "тупые" алгоритмы сортировки. Потому что, как правило, их стратегия включает в себя, для каждого элемента (n), вы смотрите на все остальные элементы (так раз другой n, предоставив n2), затем расположитесь в нужном месте.
- O (n log (n)): различные "умные" алгоритмы сортировки. Оказывается, вам нужно всего лишь посмотреть, скажем, 10 элементов в 1010-коллекция элементов, чтобы разумно сортировать себя относительно все еще в коллекции. Потому что все остальные и собирается посмотреть на 10 элементов, и эмерджентное поведение организовано так, чтобы этого было достаточно для создания отсортированного списка.
- O (n!): алгоритм, который "пробует все", так как есть (пропорционально)n! возможные комбинации n элементы, которые могут решить данную проблему. Поэтому он просто проходит через все такие комбинации, пробует их, а затем останавливается, когда он преуспевает.
нет.ответ нойфельда очень хорош, но я бы, вероятно, объяснил его в двух частях: во-первых, существует грубая иерархия O (), в которую попадают большинство алгоритмов. Затем вы можете посмотреть на каждый из них, чтобы придумать эскизы того, что типичный алгоритмы той сложности времени делают.
для практических целей единственными O (), которые когда-либо имели значение, являются:
- O (1)" постоянное время " - требуемое время не зависит от размера входного сигнала. Как грубый категория, я бы включил такие алгоритмы, как хэш-поиск и Union-Find здесь, хотя ни один из них на самом деле не O(1).
- O (log (n)) "логарифмический" - он становится медленнее, когда вы получаете большие входы, но как только ваш вход становится довольно большим, он не изменится достаточно, чтобы беспокоиться. Если ваша среда выполнения в порядке с данными разумного размера, вы можете затопить ее с таким количеством дополнительных данных, как вы хотите, и все будет в порядке.
- O (n) "линейный" - чем больше вход, тем дольше он занимает, в четном компромисс. Три раза размер входного сигнала займет примерно в три раза больше времени.
- O (N log (n)) "лучше, чем квадратичный" - увеличение размера ввода больно, но это все еще управляемо. Алгоритм, вероятно, приличный, просто основная проблема сложнее (решения менее локализованы относительно входных данных), чем те проблемы, которые могут быть решены в линейное время. Если ваши входные размеры получают там, не предполагайте, что вы обязательно могли бы обрабатывать дважды размер без изменения вашей архитектуры (например, путем перемещения вещей в ночные пакетные вычисления или не делать вещи за кадр). Это нормально,если размер ввода немного увеличивается; просто следите за кратными.
- O (n^2) "квадратичный" - он действительно будет работать только до определенного размера вашего ввода, поэтому обратите внимание на то, насколько он может быть большим. Кроме того, ваш алгоритм может сосать-подумайте, есть ли алгоритм o(n log(n)), который даст вам то, что вам нужно. Однажды вы здесь, чувствуйте себя очень благодарными за удивительное оборудование, которым мы были одарены. Не так давно, что вы пытаетесь сделать было бы невозможно для всех практических целей.
- O(n^3) "кубический" - не качественно все, что отличается от O (n^2). Те же замечания, только в большей степени. Есть неплохой шанс, что более умный алгоритм может сократить это время до чего-то меньшего, например O(n^2 log(n)) или O(n^2.8...), но опять же, есть хороший шанс, что это не стоит беда. (Вы уже ограничены в своем практическом размере ввода, поэтому постоянные факторы, которые могут потребоваться для более умных алгоритмов, вероятно, затопят их преимущества для практических случаев. Кроме того, мышление медленное; позволяя компьютеру жевать его, вы можете сэкономить время в целом.)
- O (2^n) "экспоненциальный" - проблема либо принципиально вычислительно сложна, либо вы ведете себя как идиот. Эти проблемы имеют узнаваемый привкус. Ваши входные размеры ограничены на довольно конкретный жесткий предел. Вы быстро поймете, вписываетесь ли вы в этот предел.
и это все. Есть много других возможностей, которые подходят между ними(или больше, чем O (2^n)), но они не часто происходят на практике, и они качественно не сильно отличаются от одного из них. Кубические алгоритмы уже немного растянуты; я включил их только потому, что я сталкивался с ними достаточно часто, чтобы их стоило упомянуть (например, умножение матрицы).
Что на самом деле происходит для этих классов алгоритмов? Ну, я думаю, у вас было хорошее начало, хотя есть много примеров, которые не соответствуют этим характеристикам. Но для вышесказанного я бы сказал, что обычно это звучит примерно так:
- O (1) - вы смотрите только на фиксированный размер куска ваших входных данных, и, возможно, ни один из них. Пример: максимум отсортированного списка.
- или ваш входной размер ограничен. Пример: сложение двух чисел. (Обратите внимание, что добавление N числа-это линейное время.)
- O (log n) - каждый элемент вашего ввода говорит вам достаточно, чтобы игнорировать большую часть остальной части ввода. Пример: когда вы смотрите на элемент массива в двоичном поиске, его значение говорит вам, что вы можете игнорировать "половину" вашего массива, не глядя на него. Или аналогично, элемент, на который вы смотрите, дает вам достаточно резюме части оставшегося ввода, чтобы вам не нужно было смотреть на него.
- нет ничего особенно о половинках, хотя-если вы можете игнорировать только 10% вашего ввода на каждом шаге, это все еще логарифмично.
- O (n) - вы делаете некоторый фиксированный объем работы на входной элемент. (Но смотрите ниже.)
- O (N log (n)) - существует несколько вариантов.
- вы можете разделить входной сигнал в 2 кучи (в не больше чем линейном времени), разрешаете проблему независимо на каждой куче, и после этого совмещаете 2 кучи для того чтобы сформировать окончательное решение. Независимость две стопки-это ключ. Пример: классический рекурсивный mergesort.
- каждый линейно-временной проход над данными получает вас на полпути к вашему решению. Пример: quicksort если вы думаете в терминах максимального расстояния каждого элемента до его конечной отсортированной позиции на каждом шаге разбиения (и да, я знаю, что на самом деле это O(n^2) из-за вырожденных вариантов поворота. Но практически говоря, он попадает в мою категорию o(n log (n)).)
- O ( n^2) - вы должны смотреть на каждый пара входных элементов.
- или нет, но вы думаете, что знаете, и используете неправильный алгоритм.
- O (n^3) - um... У меня нет четкой характеристики этого. Это, вероятно, один из:
- вы умножаете матрицы
- вы смотрите на каждую пару входов, но операция, которую вы делаете, требует просмотра всех входов снова
- вся структура графика вашего ввода уместно
- за O(2^n) - вам необходимо рассмотреть все возможные подмножества входов.
ни один из них не строгий. Особенно не линейные алгоритмы времени(O (n)): я мог бы придумать ряд примеров, где вам нужно посмотреть на все входы, затем половину из них, затем половину из них и т. д. Или наоборот-сложить вместе пары входов, затем повторить на выходных. Это не соответствует описанию выше, так как вы не смотрите на каждом входе один раз, но он все равно выходит в линейное время. Еще, 99.2% времени, линейного времени означает раз за каждый вход.
многие из них легко продемонстрировать с помощью чего-то не программирования, например, перетасовки карт.
сортировка колоды карт, пройдя через всю колоду, чтобы найти туза пик, затем пройдя через всю колоду, чтобы найти 2 пик, и так далее будет худшим случаем N^2, Если колода уже отсортирована назад. Вы просмотрели все 52 карты 52 раза.
В общем, действительно плохие алгоритмы не обязательно преднамеренны, они обычно являются неправильным использованием что-то еще, например, вызов метода, линейного внутри другого метода, который повторяется над тем же набором линейно.
Ok-здесь есть некоторые очень хорошие ответы, но почти все они, похоже, делают ту же ошибку, и это тот, который пронизывает общее использование.
неофициально мы пишем, что f( n) = O(g(n) ) если, до коэффициента масштабирования и для всех n больше некоторого n0, g (n)больше чем f (n). То есть f (n) растет не быстрее чем, или ограничен сверху by, g (n). Это ничего не говорит нам о том, как быстро растет f(n), за исключением того, что это гарантированно не будет хуже, чем g(n).
конкретный пример: n = O (2^n ). Мы все знаем, что n растет гораздо медленнее, чем 2^n, так что это дает нам право сказать, что он ограничен выше экспоненциальной функцией. Между n и 2^n много места, поэтому это не очень жесткий связаны, но это все еще законная связь.
Почему мы (компьютерщики) используйте границы, а не быть точным? Потому что а) границы часто легче доказать и Б) дает нам короткую руку для выражения свойств алгоритмов. Если я скажу, что мой новый алгоритм O (n.log n) это означает, что в худшем случае его время выполнения будет ограничено сверху n.войдите n на N входов, для достаточно большого n (хотя см. мои комментарии ниже, когда я не могу иметь в виду худший случай).
Если вместо этого мы хотим сказать, что функция растет так же быстро, как и какая-либо другая функция, мы используем тэта чтобы сделать эту точку (я напишу T (f (n)), чтобы означать \Theta f (n) в снижение.) T (g (n)) - короткая рука для ограничения от выше и ниже по g (n), опять же, до коэффициента масштабирования и асимптотически.
то есть f( n) = T(g(n) ) f(n) = O(g(n)) и g(n) = O(f (n)). В нашем примере, мы видим, что N != T (2^n ) потому что 2^n != O (n).
зачем беспокоиться об этом? Потому что в вашем вопросе вы пишете: "должен ли кто-то курить крэк, чтобы написать O(x!)?- Ответ " нет " , потому что в основном все, что вы напишете, будет быть ограниченным сверху факторной функцией. Время работы quicksort-O (n!- это просто не очень крепкая связь.
здесь есть еще одно измерение тонкости. Как правило, мы говорим о худший случай ввода когда мы используем нотацию O( g(n)), так что мы делаем составное утверждение: в худшем случае время выполнения не будет хуже, чем алгоритм, который принимает шаги g(n), снова масштабирование по модулю и для достаточно большого n. Но иногда нам хочется поговорить. о времени работы в среднем и даже лучшие случаях.
ванильный quicksort, как всегда, хороший пример. Это T (n^2 ) в худшем случае(на самом деле это займет не менее n^2 шагов, но не значительно больше), но T (n.log n) в среднем случае, то есть ожидаемое количество шагов пропорционально n.log n. В лучшем случае это также T(n.log n) - но вы можете улучшить это, например, проверив, был ли массив уже отсортирован в этом случае лучшим временем выполнения будет T (n ).
Как это относится к вашему вопросу о практической реализации этих границ? Ну, к сожалению, нотация O () скрывает константы, с которыми приходится иметь дело в реальных реализациях. Поэтому, хотя мы можем сказать, что, например, для операции T(n^2) мы должны посетить каждую возможную пару элементов, мы не знаем, сколько раз мы должны их посетить (за исключением того, что это не функция n). Так что мы могли бы посетить каждая пара 10 раз, или 10^10 раз, и утверждение T(n^2) не делает различия. Функции нижнего порядка также скрыты - мы могли бы посетить каждую пару элементов один раз, и каждый отдельный элемент 100 раз, потому что n^2 + 100n = T(n^2). Идея обозначения O () заключается в том, что для достаточно большого n это вообще не имеет значения, потому что n^2 становится настолько больше 100n, что мы даже не замечаем влияния 100n на время работы. Однако мы часто имеем дело с "достаточно маленькими" n такими, что постоянные факторы и так далее имеют реальное, существенное значение.
например, quicksort (средняя стоимость T (n.log n)) и heapsort (средняя стоимость T (n.log n)) - оба алгоритма сортировки с одинаковой средней стоимостью, но quicksort обычно намного быстрее, чем heapsort. Это потому, что heapsort делает несколько больше сравнений на элемент, чем quicksort.
Это не значит, что обозначение O( ) бесполезно, просто неточно. Это довольно тупой инструмент для маленьких n.
(в качестве заключительной заметки к этому трактату помните, что нотация O( ) просто описывает рост любой функции - это не обязательно должно быть время, это может быть память, сообщения, обмениваемые в распределенной системе или количество процессоров, необходимых для параллельного алгоритма.)
Я пытаюсь объяснить простые примеры кода на C#.
на List<int> numbers = new List<int> {1,2,3,4,5,6,7,12,543,7};
O (1) выглядит как
return numbers.First();
O (n) выглядит как
int result = 0;
foreach (int num in numbers)
{
result += num;
}
return result;
O (N log (n)) выглядит как
int result = 0;
foreach (int num in numbers)
{
int index = numbers.length - 1;
while (index > 1)
{
// yeah, stupid, but couldn't come up with something more useful :-(
result += numbers[index];
index /= 2;
}
}
return result;
O (n^2) выглядит как
int result = 0;
foreach (int outerNum in numbers)
{
foreach (int innerNum in numbers)
{
result += outerNum * innerNum;
}
}
return result;
O (n! похоже, надоело придумывать что-то простое.
Но я надеюсь, вы поняли общую мысль?
то, как я описываю это своим нетехническим друзьям, выглядит так:
рассмотрим многозначное сложение. Старомодное дополнение карандашом и бумагой. Ты узнал, когда тебе было 7-8 лет. Учитывая два трех - или четырехзначных числа, вы можете узнать, что они складываются довольно легко.
Если бы я дал вам два 100-значных числа и спросил вас, что они складываются, выяснить это было бы довольно просто, даже если бы вам пришлось использовать карандаш и бумагу. Ля смышленый парень мог бы сделать такое дополнение всего за несколько минут. Для этого потребуется всего около 100 операций.
теперь рассмотрим многозначное умножение. Вы, вероятно, узнали это примерно в 8 или 9 лет. Вы (надеюсь) сделали много повторяющихся упражнений, чтобы узнать механику за ним.
много сложнее задача, что-то, что бы на это у вас уйдет несколько часов, и вряд ли вы обойдетесь без ошибок. Причина этого в том, что(эта версия) умножения равна O (n^2); каждая цифра в Нижнем числе должна быть умножена на каждую цифру в верхнем числе, оставляя в общей сложности около n^2 операций. В случае 100-значных чисел, это 10 000 умножений.нет, алгоритм O(n) не означает, что он будет выполнять операцию над каждым элементом. Нотация Big-O дает вам возможность говорить о" скорости " вашего алгоритма независимо от вашей фактической машины.
O (n) означает, что время, которое займет ваш алгоритм, растет линейно по мере увеличения ввода. O (n^2) означает, что время, которое занимает ваш алгоритм, растет как квадрат вашего ввода. И так далее.
Как я думаю об этом, у вас есть задача очистки проблемы, вызванной каким-то злым злодеем V, который выбирает N, и вы должны оценить, сколько времени потребуется, чтобы закончить вашу проблему, когда он увеличивает N.
O (1) - > увеличение N действительно не имеет никакого значения вообще
O(log (N)) -> каждый раз, когда V удваивает N, вы должны потратить дополнительное количество времени T для выполнения задачи. V удваивает N снова, и вы тратите то же самое сумма.
O (N) -> каждый раз, когда V удваивает N, вы тратите вдвое больше времени.
O (N^2) -> каждый раз, когда V удваивает N, вы тратите 4x столько же времени. (это несправедливо!!!)
O (N log (N)) -> каждый раз, когда V удваивает N, вы тратите вдвое больше времени плюс немного больше.
Это границы алгоритма; компьютерные ученые хотят описать, сколько времени это займет для больших значений N. (что становится важным, когда вы разлагаете числа, которые используются в криптография - если компьютеры ускоряются в 10 раз, сколько еще битов вы должны использовать, чтобы гарантировать, что им потребуется 100 лет, чтобы взломать ваше шифрование, а не только 1 год?)
некоторые границы могут иметь странные выражения, если это имеет значение для людей. Я видел такие вещи, как O(N log(N) log(log(N))) где-то в искусстве программирования кнута для некоторых алгоритмов. (не могу вспомнить, который из них с моей головы)
одна вещь, которая еще не была затронута по какой-то причине:
когда вы видите алгоритмы с такими вещами, как O(2^n) или O(n^3) или другие неприятные значения, это часто означает, что вам придется принять несовершенный ответ на вашу проблему, чтобы получить приемлемую производительность.
правильные решения, которые взрываются, как это часто встречается при решении проблем оптимизации. Почти правильный ответ, поставленный в разумные сроки, лучше, чем правильный ответ поставлено после того как машина распадется в пыль.
рассмотрим шахматы: я не знаю точно, какое правильное решение считается, но это, вероятно, что-то вроде O(n^50) или даже хуже. Теоретически ни один компьютер не может вычислить правильный ответ-даже если вы используете каждую частицу во Вселенной в качестве вычислительного элемента, выполняющего операцию в минимально возможное время для жизни Вселенной, у вас все еще остается много нулей. (Другое дело, может ли квантовый компьютер решить эту проблему.)
в "Intuitition" за большой-О
представьте себе "соревнование" между двумя функциями над x, поскольку x приближается к бесконечности: f(x) и g(x).
теперь, если с некоторого момента (некоторого x) одна функция всегда имеет более высокое значение, чем другая, тогда давайте назовем эту функцию "быстрее", чем другая.
Так, например, если для каждого x > 100 вы видите, что f(x) > g(x), то f(x) "быстрее", чем g(x).
в этом случае мы бы сказали g (x) = O(f (x)). f(x) представляет собой своего рода "ограничение скорости" для g (x), так как в конечном итоге он проходит его и оставляет его навсегда.
Это не совсем определение Big-O notation, в котором также говорится, что f(x) должен быть больше, чем C*g(x) для некоторой постоянной C (что является еще одним способом сказать, что вы не можете помочь g(x) выиграть соревнование, умножив его на постоянный фактор - f(x) всегда будет выигрывать в конце). Формальное определение также использует absolute ценности. Но я надеюсь, что мне удалось сделать это интуитивно.
- и кто-то должен курить крэк, чтобы написать O (x!)?
нет, просто используйте Prolog. Если вы напишете алгоритм сортировки в Prolog, просто описав, что каждый элемент должен быть больше предыдущего, и пусть backtracking сделает сортировку за вас, это будет O(x!). Также известный как"вид перестановки".
Мне нравится ответ Дона нойфельда, но я думаю, что могу добавить что-то о O(N log n).
алгоритм, который использует простую стратегию разделения и завоевания, вероятно, будет O(log n). Самый простой пример этого-найти что-то в отсортированном списке. Ты не начинаешь с самого начала и не ищешь его. Вы идете к середине, вы решаете, следует ли вам идти назад или вперед, прыгать на полпути к последнему месту, куда вы смотрели, и повторять это, пока не найдете предмет, который вы находясь в поиске.
Если вы посмотрите на алгоритмы quicksort или mergesort, вы увидите, что они оба используют подход разделения списка, который нужно отсортировать пополам, сортируя каждую половину (используя тот же алгоритм рекурсивно), а затем рекомбинируя две половины. Такого рода рекурсивные разделяй и властвуй стратегия будет O (N log n).
Если вы подумаете об этом внимательно, вы увидите, что quicksort выполняет алгоритм разбиения O(n) на все n элементов, а затем O (n) разделение дважды по N/2 пунктам, затем 4 раза по n/4 пунктам и т. д... пока вы не доберетесь до n разделов на 1 элемент (который вырождается). Число раз, когда вы делите n пополам, чтобы добраться до 1, примерно равно log n, и каждый шаг равен O(n), поэтому рекурсивное деление и завоевание равно O(N log n). Mergesort строит по-другому, начиная с N рекомбинаций 1 элемента и заканчивая 1 рекомбинацией n элементов, где рекомбинация двух отсортированных списков равна O(n).
Как курить крэк написать O (n!) алгоритм, вы, если у вас нет выбора. Одной из таких проблем считается проблема коммивояжера, приведенная выше.
большинство книг Джона Бентли (например,Жемчужины Программирования) охватывают такие вещи в действительно прагматичной манере. этот разговор данный им включает в себя один такой анализ quicksort.
хотя это не совсем относится к вопросу, кнут придумал интересная идея: преподавание нотации Big-O в классах математики средней школы, хотя я нахожу эту идею довольно эксцентричной.
подумайте об этом, как укладка блоков lego (n) вертикально и перепрыгивая через них.
O (1) означает, что на каждом шаге вы ничего не делаете. Высота остается прежней.
O (n) означает, что на каждом шаге вы складываете блоки c, где C1-константа.
O (n^2) означает, что на каждом шаге вы складываете C2 x N блоков, где c2-константа, а n-количество уложенных блоков.
O (nlogn) означает, что на каждом шаге вы складываете блоки C3 x n x log n, где C3-константа, а n - количество уложенных блоков.
чтобы понять O (N log n), помните, что log n означает log-base-2 из n. Затем посмотрите на каждую часть:
O (n), более или менее, когда вы работаете над каждым элементом в наборе.
O (log n) - это когда количество операций совпадает с показателем, до которого вы поднимаете 2, чтобы получить количество элементов. Например, двоичный поиск должен сократить набор наполовину в N раз.
O (N log n) - это комбинация – вы делаете что-то по строкам двоичного файла поиск каждого элемента в наборе. Эффективные виды часто работают, делая один цикл для каждого элемента, и в каждом цикле делают хороший поиск, чтобы найти правильное место, чтобы поставить элемент или группу в вопросе. Следовательно, N * log n.
просто чтобы ответить на пару комментариев к моему вышеуказанному сообщению:
Доменик - Я на этом сайте, и мне не все равно. Не из педантичности, а потому, что мы - программисты-обычно заботимся о точности. Неправильное использование обозначения O () в стиле, который некоторые сделали здесь, делает его бессмысленным; мы можем также сказать, что что-то занимает n^2 единиц времени, как O( n^2) в соответствии с используемыми здесь соглашениями. Использование O () ничего не добавляет. Это не просто маленький несоответствие между обычным использованием и математической точностью, о которой я говорю, это разница между тем, что это значимо, а это нет.
Я знаю много, много отличных программистов, которые используют эти термины точно. Слова "о, мы программисты, поэтому нам все равно" удешевляют все предприятие.
onebyone - Ну, не совсем, хотя я понимаю вашу точку зрения. Это не O (1) для произвольно большого n, что является своего рода определением O (). Это просто показывает, что O( ) имеет ограниченную применимость для ограниченного n, где мы предпочли бы фактически говорить о количестве предпринятых шагов, а не об ограничении этого числа.
скажите, что ваш восьмилетний журнал (n) означает количество раз, когда вам нужно нарезать длину N войти в два, чтобы она дошла до размера n=1 :p
O (N log n) обычно сортируется O (n^2) обычно сравнивает все пары элементов
Предположим, у вас есть компьютер, который может решить проблему определенного размера. Теперь представьте, что мы можем удвоить производительность несколько раз. Насколько большую проблему мы можем решить с каждым удвоением?
Если мы можем решить проблему двойного размера, Это O (n).
Если у нас есть какой-то множитель, который не один, это своего рода полиномиальная сложность. Например, если каждое удвоение позволяет увеличить размер задачи примерно на 40%, то это O (n^2) и около 30% будет O (n^3).
Если мы просто добавим к размеру проблемы, это экспоненциально или хуже. Например, если каждое удвоение означает, что мы можем решить проблему 1 больше, Это O(2^н). (Вот почему грубое принуждение ключа шифрования становится фактически невозможным с ключами разумного размера: 128-битный ключ требует примерно в 16 квинтиллионов раз больше обработки, чем 64-битный.)
помните басню о черепахе и зайце (черепаха и кролик)?
в долгосрочной перспективе выигрывает черепаха, но в краткосрочной перспективе выигрывает заяц.
Это как O (logN) (черепаха) против O (N) (заяц).
Если два метода отличаются своим big-O, то существует уровень N, на котором один из них выиграет, но big-O ничего не говорит о том, насколько велик этот N.
чтобы оставаться искренним на заданный вопрос, я бы ответил на вопрос так, как я бы ответил 8-летнему ребенку
предположим, что продавец мороженого готовит несколько мороженых (скажем, N ) разных форм, расположенных упорядоченно. Вы хотите съесть мороженое, лежа в середине
Случай 1 : - Вы можете съесть мороженое, только если вы съели все мороженое меньше, чем Вам придется съесть половину всего мороженого, приготовленного (вход).Ответ напрямую зависит от размера входных данных Решение будет порядка o (N)
случай 2 :- Вы можете сразу съесть мороженое в середине
решение будет O (1)
Случай 3: Вы можете съесть мороженое, только если вы съели все мороженое меньше, чем он, и каждый раз, когда вы едите мороженое вы позволяете другому ребенку (новый ребенок каждый раз), чтобы съесть все его мороженое Общее время будет N + N + N.......(N/2) раз Решение будет O (N2)
log (n) означает логарифмический рост. Примером могут служить алгоритмы divide и conquer. Если у вас есть 1000 отсортированных чисел в массиве ( ex. 3, 10, 34, 244, 1203 ... ) и хотите найти номер в списке (найти его позицию), вы можете начать с проверки значения номера в индексе 500. Если он ниже того, что вы ищете, прыгайте до 750. Если он выше того, что вы ищете, прыгайте до 250. Затем вы повторяете процесс, пока не найдете свое значение (и ключ). Каждый раз, когда мы прыгаем, пространство поиска, мы можем отбирать тестирование многих других значений, так как мы знаем, что число 3004 не может быть выше числа 5000 (помните, это отсортированный список).
N log(n) тогда означает N * log (n).
я попытаюсь на самом деле написать объяснение для настоящего восьмилетнего мальчика, помимо технических терминов и математических понятий.
как то, что именно
O(n^2)операцию делать?
если вы находитесь в гостях, и есть n люди в партии, включая вас. Сколько рукопожатий нужно, чтобы все пожали друг другу руки, учитывая, что люди, вероятно, забудут, с кем они пожимали руки точка.
Примечание: это приближается к симплексу, дающему n(n-1) что достаточно близко к n^2.
и что, черт возьми, это значит, если операция
O(n log(n))?
ваша любимая команда выиграла, они стоят в очереди, и есть n игроки в команде. Сколько хэншейков вам потребуется, чтобы пожать руку каждому игроку, учитывая, что вы будете хэншейк каждый несколько раз, сколько раз, сколько цифр в количество игроков n.
Примечание: это даст n * log n to the base 10.
и кто-то должен курить крэк, чтобы написать
O(x!)?
вы богатый ребенок, и в вашем гардеробе есть много тканей, есть x ящики для каждого типа одежды, ящики рядом друг с другом, первый ящик имеет 1 деталь, каждый ящик имеет как много тканей как в ящике к своему левому и одному больше, поэтому вы имеете что-то как 1 шляпа, 2 парики, .. (x-1) брюки,x рубашки. Теперь, сколько способов вы можете одеваться, используя один элемент из каждого ящика.
Примечание: этот пример представляет, сколько листьев в дереве решений, где number of children = depth, что делается через 1 * 2 * 3 * .. * x