Читать побочные подходы реализации с использованием CQRS
я перешел к проекту, который активно использует CQRS + Event sourcing. С первого взгляда он реализован в соответствии со всеми этими книгами и блогами, но, наконец, я понял, что именно раздражает в реализации.
вот архитектура CQRS: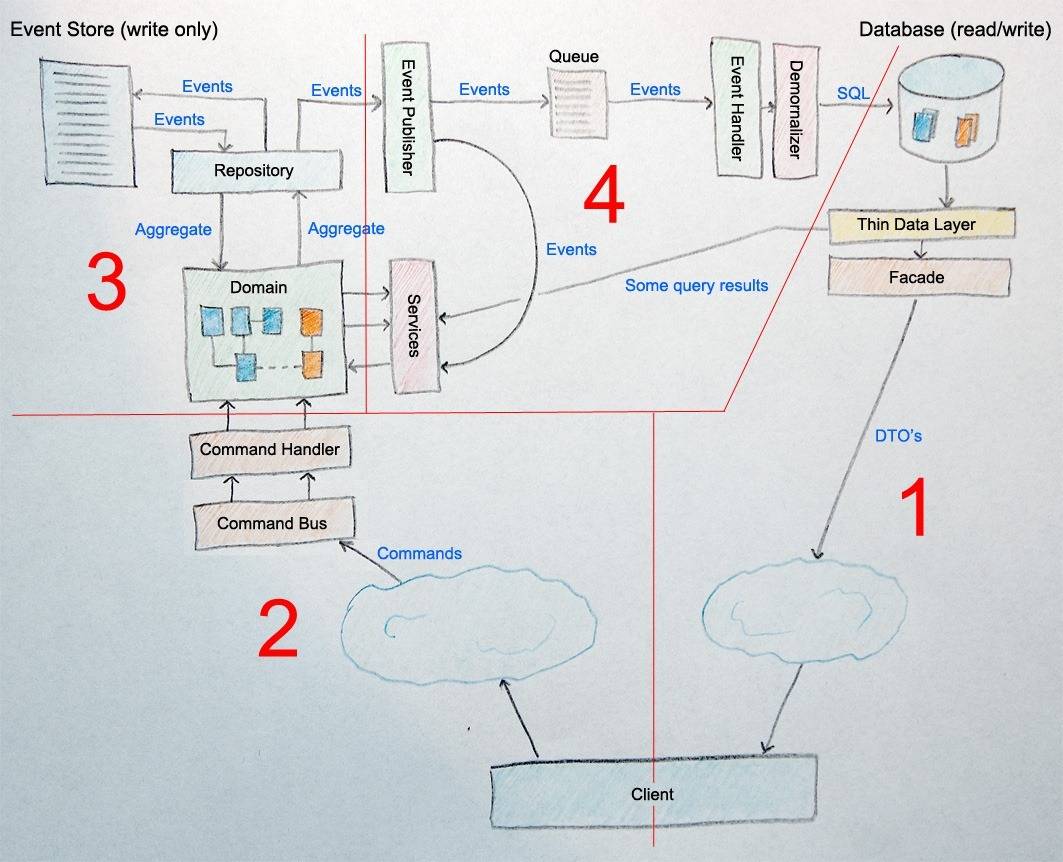
Первоначально я взял эту фотографию из здесь.
Как мы видим на рисунке, сторона чтения получает события из очереди и передает их один за другим в разные наборы проекций (денормализаторы), а затем результирующие ViewModels сохраняются с помощью метода AddOrUpdate в, скажем, DB. Так как я понимаю из рисунка denormalizer может полагаться только на само событие плюс данные из БД на стороне чтения. Например:
- представление учетной записи уже хранится в БД.
- событие EmailChanged прибывает
- мы читаем представление учетной записи из БД
- применяя сменить email на него
- мы сохраняем учетную запись обратно в ДЕЦИБЕЛ.
другой случай (подсчет количества некоторых предметов, скажем заказов):
- событие OrderCreated прибывает
- мы читаем ViewModel, который представляет число ранее поступивших заказов
- увеличьте и сохраните это.
Что мы имеем в нашем проекте: Мы используем все эти события только как уведомление о том, что что-то изменилось в модели домена. Следовательно, что мы делаем:
- берем репозиторий домена и прочитайте все необходимые агрегаты. При этом мы получаем самое последнее их состояние.
- мы просто строим объект ViewModel с нуля
- сохранить вновь созданный объект в Db
подход, который мы используем в нашем проекте, выглядит немного странным для меня, я не вижу всех его недостатков. Если нам нужно перестроить нашу сторону чтения, мы добавляем "активный" денормализатор, и в следующий раз, когда он получает конкретное событие, он воссоздает новую viewmodel.
Если мы используем подход из книг, мне нужно будет иметь отдельную логику utils где-то вне моей системы для восстановления. Что нам для этого нужно:
- отбросьте сторону чтения
- прочитайте все события из магазина событий с самого начала
- пропустите их через проекции
Итак, мой вопрос:
Какой здесь правильный подход?
1 ответов
подход, который мы используем в нашем проекте выглядит немного странно для меня, я не могу но вы видите все его недостатки.
одним из заметных недостатков является то, что после получения события вам необходимо сделать дополнительный вызов в репозиторий соответствующей агрегации. Это означает, что этот репозиторий должен быть открыт либо непосредственно, либо как служба. В дополнение к увеличенным зависимостям дополнительный IO.
для восстановления из хранилища событий подход, который вы описываете, является общепринятым методом. Описанный подход здесь использует журнал событий, посвященный перестроению проекций. Это можно использовать для решения проблем производительности при перестройке. Также взгляните на масштабируемые и простые представления CQRS в облаке и список рассылки DDD/CQRS.