Что такое "энтропия и получение информации"?
Я читаю эту книгу (в nltk) и это сбивает с толку. энтропия is определяется как:
энтропия-это сумма вероятности каждой метки умножить логарифмическую вероятность того же ярлыка
Как я могу применить энтропия и максимальной энтропии С точки зрения анализа текста? Может кто-нибудь дать мне простой, простой пример (визуальный)?
7 ответов
я предполагаю, что энтропия упоминалась в контексте построения деревья решений.
чтобы проиллюстрировать, представьте себе задачу обучение to классификация имена в мужские / женские группы. Это дает список имен, каждый из которых помечен либо m или f, мы хотим узнать модель, что соответствует данным и может быть использовано для прогнозирования пола новый невидимый имя.
name gender
----------------- Now we want to predict
Ashley f the gender of "Amro" (my name)
Brian m
Caroline f
David m
первый шаг решить что особенности данных относятся к целевому классу, который мы хотим предсказать. Некоторые функции примера включают: первая / последняя буква, длина, количество гласных, заканчивается ли она гласной и т. д.. Поэтому после извлечения функции наши данные выглядят так:
# name ends-vowel num-vowels length gender
# ------------------------------------------------
Ashley 1 3 6 f
Brian 0 2 5 m
Caroline 1 4 8 f
David 0 2 5 m
цель состоит в том, чтобы построить дерево решений. Пример дерево будет быть:
length<7
| num-vowels<3: male
| num-vowels>=3
| | ends-vowel=1: female
| | ends-vowel=0: male
length>=7
| length=5: male
в основном каждый узел представляет собой тест, выполненный на одном атрибуте, и мы идем влево или вправо в зависимости от результата теста. Мы продолжаем пересекать дерево, пока не достигнем листового узла, который содержит предсказание класса (m или f)
Итак, если мы запустим имя Амро вниз по этому дереву мы начнем с тестирования"длина" и ответ да, поэтому мы спускаемся по этой ветке. После бранч, следующий тест"количество гласных" снова оценивает в true. Это приводит к узлу листа с надписью m, и таким образом, предсказание мужчина (которым я оказался, поэтому дерево предсказало результат правильно).
дерево решений построенный в нисходящей моде, но вопрос в том, как вы выбираете, какой атрибут разделить на каждый узел? Ответ найти функцию, которая наилучшим разбивает целевой класс на чистейшие возможные дочерние узлы (т. е. узлы, которые не содержат смесь мужских и женских, а чистые узлы только с одним классом).
эта мера чистота называется информация. Он представляет ожидается сумме информация это необходимо для указания того, должен ли новый экземпляр (имя) быть классифицирован как мужской или женский, учитывая пример это достигло узла. Мы вычисляем его основываясь на количестве мужских и женских классов в узле.
энтропия С другой стороны-это мера примесь (наоборот). Она определяется для бинарных класс значения a/b as:
Entropy = - p(a)*log(p(a)) - p(b)*log(p(b))
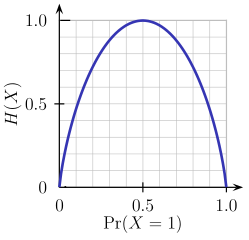
этой двоичная функция энтропии изображено на рисунке ниже (случайная величина может принимать одно из двух значений). Она достигает своего максимум, когда вероятность p=1/2, что означает p(X=a)=0.5 или жеp(X=b)=0.5 имеющие 50%/50% шанс быть либо a или b (неопределенность на максимуме). Функция энтропии находится на нулевом минимуме, когда вероятность p=1 или p=0 С полной уверенностью (p(X=a)=1 или p(X=a)=0 соответственно, последний подразумевает p(X=b)=1).
конечно, определение энтропии может быть обобщено для дискретной случайной величины X с N результаты (не только два):
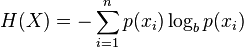
(the log в Формуле обычно принимается как логарифм к основанию 2)
вернемся к нашей задаче классификации имен, давайте рассмотрим пример. Представьте, что в какой-то момент в процессе построения дерева, мы рассматривали следующие разделения:
ends-vowel
[9m,5f] <--- the [..,..] notation represents the class
/ \ distribution of instances that reached a node
=1 =0
------- -------
[3m,4f] [6m,1f]
как вы можете видеть, до раскола у нас было 9 мужчин и 5 женщин, т. е. P(m)=9/14 и P(f)=5/14. Согласно определению энтропии:
Entropy_before = - (5/14)*log2(5/14) - (9/14)*log2(9/14) = 0.9403
затем мы сравним его с энтропией, вычисленной после рассмотрения расщепления, посмотрев на две дочерние ветви. В левой ветви ends-vowel=1 мы:
Entropy_left = - (3/7)*log2(3/7) - (4/7)*log2(4/7) = 0.9852
и правая ветвь ends-vowel=0 мы:
Entropy_right = - (6/7)*log2(6/7) - (1/7)*log2(1/7) = 0.5917
мы объединяем левую / правую энтропии, используя количество экземпляров вниз по каждой ветви как весовой коэффициент (7 экземпляров ушли влево, а 7 экземпляры пошли направо), и получить окончательную энтропию после расщепления:
Entropy_after = 7/14*Entropy_left + 7/14*Entropy_right = 0.7885
теперь, сравнивая энтропию до и после раскола, мы получаем меру информация набрать, или сколько информации мы получили, выполнив разделение с помощью этой конкретной функции:
Information_Gain = Entropy_before - Entropy_after = 0.1518
вы можете интерпретировать приведенный выше расчет следующим образом: выполнив разделение с помощью end-vowels особенность, мы смогли уменьшить неопределенность в результат прогноза под-дерева небольшим количеством 0.1518 (измеряется в bits as единиц информации).
в каждом узле дерева этот расчет выполняется для каждой функции, а функция с сбор информации выбирается для раскола в жадина манера (таким образом, благоприятствуя особенности, которые производят чисто разбивается с низкой неопределенностью / энтропией). Этот процесс применяется рекурсивно от корневого узла вниз и останавливается, когда листовой узел содержит экземпляры, имеющие один и тот же класс (не нужно разбивать его дальше).
обратите внимание, что я пропустил какой-нибудь подробности которые выходят за рамки этого поста, в том числе как обращаться числовые функции, отсутствующие значения, слишком хорошо!--37--> и подрезка деревья и т. д..
для начала, было бы лучше понять the measure of information.
как мы measure информация?
когда происходит что-то маловероятное, мы говорим, что это большая новость. Также, Когда мы говорим что-то предсказуемое, это не очень интересно. Итак, чтобы количественно оценить это interesting-ness функция должна удовлетворять
- если вероятность события равна 1 (предсказуема), то функция дает 0
- если вероятность события близка к 0, тогда функция должна давать высокое число
- если вероятность 0,5 события происходит, это дает
one bitинформации.
одной естественной мерой, удовлетворяющей ограничениям, является
I(X) = -log_2(p)
здесь p вероятность события X. И устройство находится в bit, тот же бит, который использует компьютер. 0 или 1.
Пример 1
ярмарка монетку :
сколько информации мы можем получить от одного подбрасывание монет?
ответ : -log(p) = -log(1/2) = 1 (bit)
Пример 2
если завтра на Землю упадет Метеор,p=2^{-22} тогда мы можем получить 22 бита информации.
если завтра взойдет солнце,p ~ 1 тогда это 0 бит информации.
энтропия
Итак, если мы возьмем ожидание на interesting-ness события Y, тогда это энтропия.
т. е. энтропия-это ожидаемое значение интересности событие.
H(Y) = E[ I(Y)]
более формально энтропия-это ожидаемое количество битов события.
пример
Y = 1: событие X происходит с вероятностью p
Y = 0: событие X не происходит с вероятностью 1-p
H(Y) = E[I(Y)] = p I(Y==1) + (1-p) I(Y==0)
= - p log p - (1-p) log (1-p)
база журналов 2 для всех журналов.
Я не могу дать вам графику, но, возможно, я могу дать четкое объяснение.
Предположим, у нас есть информационный канал, такой как свет, который мигает один раз в день красным или зеленым. Сколько информации он передает? Первое предположение-один бит в день. Но что, если мы добавим синий, чтобы у отправителя было три варианта? Мы хотели бы иметь меру информации, которая может обрабатывать вещи, отличные от степеней двух, но все же быть аддитивной (способ умножения числа из возможных сообщений двумя добавляет один бит). Мы могли бы сделать это, взяв журнал2(количество возможных сообщений), но оказывается, что есть более общий способ.
Предположим, мы вернулись к красному / зеленому, но красная лампочка перегорела (это общеизвестно), так что лампа всегда должна мигать зеленым. Канал теперь бесполезен,мы знаем, что следующая вспышка будет таким образом, вспышки не передают никакой информации, никаких новостей. Теперь мы ремонтируем лампочку, но накладываем правило, что красная лампочка не мигает два раза подряд. Когда лампа вспыхивает красным, мы знаем, что будет следующей вспышкой. Если вы попытаетесь отправить битовый поток по этому каналу, вы обнаружите, что вы должны кодировать его с большим количеством вспышек, чем у вас есть биты (на 50% больше, на самом деле). И если вы хотите описать последовательность вспышек, вы можете сделать это с меньшим количеством битов. То же самое относится, если каждая вспышка независима (без контекста), но зеленые вспышки более распространены, чем красные: чем больше искажена вероятность, тем меньше бит вы нужно описать последовательность, и чем меньше информации она содержит, вплоть до полностью зеленого, сгоревшего предела.
оказывается, есть способ измерить количество информации в сигнале, основанный на вероятности различных символов. Если вероятность получения символа xЯ это pЯ, тогда рассмотрим количество
-log pi
меньший pЯ, тем больше это значение. Если xЯ становится в два раза больше как маловероятно, это значение увеличивается на фиксированную сумму (log (2)). Это должно напоминать вам о добавлении одного бита в сообщение.
Если мы не знаем, каким будет символ (но мы знаем вероятности), то мы можем вычислить среднее значение этого значения, сколько мы получим, суммируя различные возможности:
I = -Σ pi log(pi)
это информационное содержание в одной вспышки.
Red bulb burnt out: pred = 0, pgreen=1, I = -(0 + 0) = 0 Red and green equiprobable: pred = 1/2, pgreen = 1/2, I = -(2 * 1/2 * log(1/2)) = log(2) Three colors, equiprobable: pi=1/3, I = -(3 * 1/3 * log(1/3)) = log(3) Green and red, green twice as likely: pred=1/3, pgreen=2/3, I = -(1/3 log(1/3) + 2/3 log(2/3)) = log(3) - 2/3 log(2)
это информационное содержание, или энтропия, сообщения. Она максимальна когда различные символы равновероятны. Если вы физик, вы используете естественный журнал, если вы компьютерщик, вы используете log2 и получаем биты.
Я действительно рекомендую вам прочитать о теории информации, байесовских методах и MaxEnt. Начать можно с этой (свободно доступной онлайн) книги Дэвида Маккея:
http://www.inference.phy.cam.ac.uk/mackay/itila/
эти методы вывода на самом деле гораздо более общие, чем просто интеллектуальный анализ текста, и я не могу придумать, как можно было бы научиться применять это к НЛП, не изучив некоторые общие основы, содержащиеся в этой книге или других вводных книг по машинному обучению и MaxEnt байесовские методы.
связь между энтропией и теорией вероятности с обработкой и хранением информации очень, очень глубока. Чтобы дать вкус этого, есть теорема из-за Шеннона, которая утверждает, что максимальный объем информации, который вы можете передать без ошибок через шумный канал связи, равен энтропии шумового процесса. Существует также теорема, которая связывает, сколько вы можете сжать кусок данных чтобы занять минимально возможную память в вашем компьютере до энтропии процесса, который генерирует данные.
Я не думаю, что действительно необходимо изучать все эти теоремы по теории коммуникации, но невозможно изучить это, не изучив основы о том, что такое энтропия, как она вычисляется, какова ее связь с информацией и выводом и т. д...
когда я реализовывал алгоритм вычисления энтропии изображения, я нашел эти ссылки, см. здесь и здесь.
это псевдо-код, который я использовал, вам нужно будет адаптировать его для работы с текстом, а не с изображениями, но принципы должны быть одинаковыми.
//Loop over image array elements and count occurrences of each possible
//pixel to pixel difference value. Store these values in prob_array
for j = 0, ysize-1 do $
for i = 0, xsize-2 do begin
diff = array(i+1,j) - array(i,j)
if diff lt (array_size+1)/2 and diff gt -(array_size+1)/2 then begin
prob_array(diff+(array_size-1)/2) = prob_array(diff+(array_size-1)/2) + 1
endif
endfor
//Convert values in prob_array to probabilities and compute entropy
n = total(prob_array)
entrop = 0
for i = 0, array_size-1 do begin
prob_array(i) = prob_array(i)/n
//Base 2 log of x is Ln(x)/Ln(2). Take Ln of array element
//here and divide final sum by Ln(2)
if prob_array(i) ne 0 then begin
entrop = entrop - prob_array(i)*alog(prob_array(i))
endif
endfor
entrop = entrop/alog(2)
Я получил этот код откуда-то, но я не могу откопать ссылку.
неофициально
энтропия наличие информации или знаний, отсутствие информации приведет к трудностям в предсказании будущего, которое является высокой энтропией (предсказание следующего слова в текстовом майнинге), а наличие информации/знаний поможет нам более реалистично предсказать будущее (низкая энтропия).
релевантная информация любого типа уменьшит энтропию и поможет нам предсказать более реалистичное будущее, эта информация может быть слово " мясо "присутствует в предложении или слово" мясо " отсутствует. Это называется Информация Набрать
формально
энтропия - отсутствие порядка predicability
когда вы читаете книгу о NLTK, было бы интересно прочитать о модуле классификатора MaxEnt http://www.nltk.org/api/nltk.classify.html#module-nltk.classify.maxent
для классификации интеллектуального анализа текста шаги могут быть: предварительная обработка (токенизация, пропаривание, выбор функций с получением информации ...), преобразование в числовое (частота или TF-IDF) (я думаю, что это ключевой шаг для понимания при использовании текста в качестве ввода в алгоритм, который только accept numeric), а затем классифицировать с помощью MaxEnt, конечно, это всего лишь пример.