Что такое хэш-функция в java?
У меня выезд этой страница Википедии на нем,но я все еще не понимаю. Может ли кто-нибудь помочь моему тупому уму понять концепции хэширования, хэш-таблицы/хэш-карты и хэш-функций? Некоторые примеры действительно помогут.
7 ответов
статья Википедии будет иметь много технической информации, но упрощенный взгляд на хеширование-это что-то вроде следующего.
представьте, что есть магическая функция, которая может дать число любому объекту. Учитывая один и тот же объект, он всегда возвращает одно и то же число.
сразу теперь у вас есть быстрый способ проверить, являются ли два объекта одинаковыми: спросите эту функцию для их чисел и сравните. Если они другие, то они не те тот же.
но что, если у них один и тот же номер? Могут ли два разных объекта иметь одинаковое число?
Да, это возможно в большинстве случае. Предположим, что функция может давать только числа между 1..10, например, и есть 100 различных объектов. Тогда, конечно, некоторые различные объекты должны иметь одинаковое число. Это то, что называется "столкновением". "Столкновение" делает наш быстрый тест на равенство не столь полезным, поэтому мы хотим максимально уменьшить его событие. Хорошая магическая функция-это та, которая попытается минимизировать количество "столкновений".
Так что еще можно сделать с этим номером? Ну, вы можете использовать его для индексации массива. Учитывая объект, вы можете поместить его в индекс, заданный числом из этой магической функции. Этот массив по существу является хэш-таблицей; эта магическая функция является хэш-функцией.
хэш-функция-это способ создания компактного представления произвольно большого объема данных. В java с помощью метода hashcode это означает, что каким-то образом описывается состояние вашего объекта (независимо от его размера) в int (4 байта). И обычно пишется довольно быстро, как описано ниже.
для упрощения в хеш-таблицах/всех HashMap хэш-код является своего рода дешевые равных. Возьмите два объекта a и b типа Foo, чтобы выяснить, если a.equals (b) занимает 500 мс, где как вычисление (эффективного) хэш-кода занимает всего 10 мс. Поэтому, если мы хотим знать, если a.equals (b) вместо того, чтобы делать это напрямую, сначала мы посмотрим на хэш-коды и спросим, делает ли a.hashCode () = = b.hashCode (). Заметьте, в нашем примере всего 20мс.
из-за определения API хэш-кода мы знаем, что если хэш-код a не равен b, то a.равенство (b) никогда не должно быть истинным. поэтому в нашем тесте выше, если мы видим, что хэш-коды неравны, нам никогда не нужно делать дольше .equals () тест, Вот почему вы всегда должны переопределить hashCode и equals вместе.
вы также можете увидеть ссылки на написание" хороших "или" хорошо распределенных " хэш-кодов. Это связано с тем, что обратное предыдущим утверждениям о hashcode и equals неверно. Более конкретно a.hashCode () = = b.hashCode () не обязательно означает a.равно (b) так что идея хорошая хэш-код-это уменьшить вероятность а.метод hashCode() == б.хэш-код (), когда.равна(б) ложно. Возможно, вы видели, что это называется столкновением хэш-функции.
вернуться к хэш-картам / таблицам. Они основаны на парах ключ / значение. Поэтому, когда вы добавляете или получаете значение, вы предоставляете ключ. Поэтому первое, что должна сделать карта, - это найти ключ, что означает найти что-то такое .equals () ключ, который вы предоставляете. Но как мы уже говорили выше .equals () может быть невероятно медленным, что означает, что сравнения могут быть значительно ускорены сначала проверьте хэш-коды. Поскольку, когда хэш-коды хорошо распределены, вы должны быстро узнать, когда x определенно != y.
теперь в дополнение к сопоставлению хэш-карт / таблиц фактически используют хэш-коды для организации их внутреннего хранения данных, однако я думаю, что это выходит за рамки того, что вы хотите понять на данный момент.
этой книга (и Поддержка видео лекции) обеспечивают некоторое большое объяснение алгоритмов и структур данных. Есть несколько лекций о хэш-функциях (1, 2). Я бы рекомендовал.
{kind=link}
кроме того, просто FYI, не совсем верно, как указано polygenelubricants в комментариях.hashCode(), вызывается экземпляр Object class возвращает адрес этого конкретного экземпляра в памяти.
хэш-таблица-это в основном способ хранить что-либо в массиве и извлекать его почти так же быстро, как искать что-то в массиве через индекс, не тратя слишком много места.
задача хэш-функции (в этом контексте) заключается в вычислении индекса массива, в котором будет храниться объект, на основе содержимого объекта. Это означает, что он всегда должен возвращать один и тот же результат для одного и того же объекта и должен возвращать разные результаты для разных объектов как можно больше. Когда два разных объекта имеют один и тот же хэш, это называется "столкновением", и вы должны специально рассматривать эти случаи, что делает все это медленнее.
отображение ключей к индексам хэш-таблицы называется хэш-функцией. Хэш-функция содержит две части
Карта Хэш-Кода: он преобразует ключи в целое число любого диапазона.
Сжатие Карте: он преобразует (приносит) эти целые числа в диапазон ключей hashtable.
взято из http://coder2design.com/hashing/
хэш-функция: если вы передаете один и тот же объект этой функции любое количество раз, будь то текст, двоичный или число, вы всегда получаете один и тот же вывод. Для целей хэш-таблицы используется целочисленная возвращающая хэш-функция.
выше функциональность вызывает хэширование.
хэш-таблица: чудо-структура данных информатики, которая возвращает результат поиска в постоянное время или O (1). Он основан на вышеупомянутой концепции хэширования. Таким образом, он имеет лучшее время доступа, чем linkedlist, бинарные деревья поиска и т. д.
Почему почти O (1): он использует массив в качестве своей базовой структуры внутри для хранения объектов и поскольку массивы имеют постоянное время доступа, следовательно, хэш-таблица тоже.
[основные внутренние]: Таким образом, он использует массив фиксированного размера внутри, и когда вы вставляете пару (ключ,значение), он вычисляет хэш ключа и использует это хэш-значение в качестве индекса для хранения пары (ключ, значение) в массиве. Далее, при поиске объекта с помощью того же ключа, он снова использует хэш-ключа в качестве индекса для поиска ключа в массиве. Теперь два объекта могут иметь одинаковое хэш-значение и, следовательно, при вставке этих объектов в хэш-таблицу произойдет столкновение. Существует два способа разрешения коллизий. Вы можете сослаться на это ссылке для достаточно подробного обсуждения этой темы.
хэш-функция: - хэш-функция принимает группу символов (называемую ключом) и сопоставляет ее со значением определенной длины (называемым хэш-значением или хэшем). Хэш-значение является репрезентативным для исходной строки символов, но обычно меньше оригинала. Хэширование выполняется для индексирования и поиска элементов в базах данных, поскольку легче найти более короткое хэш-значение, чем более длинную строку. Хэширование также используется в шифровании.Этот термин также известен как алгоритм хеширования или функция дайджеста сообщений.
HASH MAP: - HashMap-это класс коллекции, предназначенный для хранения элементов в виде пар ключ-значение. Карты предоставляют способ поиска одной вещи на основе ценности другой.
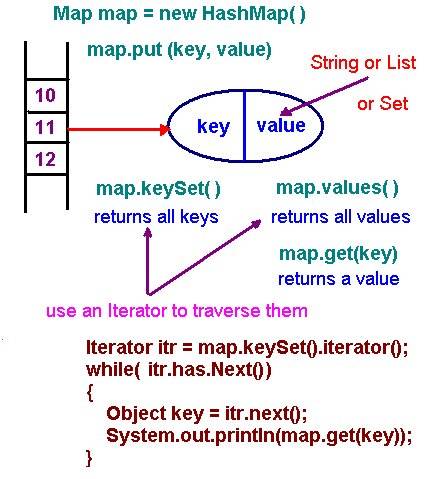
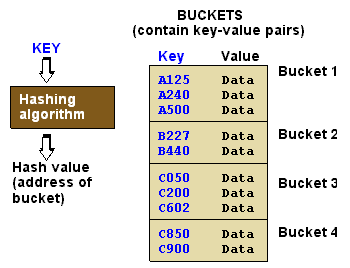
таблица поиска, которая предназначена для эффективного хранения несмежных ключей (номера счетов, номера деталей и т. д.), которые могут иметь большие пробелы в их буквенных или числовых последовательностей.
хэш-таблицы:- хэш-таблицы создаются с алгоритм, который хранит ключи в хэш-ведрах, которые содержат пары ключ-значение. Поскольку разные ключи могут хэшироваться в одном и том же ведре, цель разработки хэш-таблицы состоит в том, чтобы равномерно распределить пары ключ-значение с каждым ведром, содержащим как можно меньше пар ключ-значение. Когда элемент просматривается, его ключ хэшируется, чтобы найти соответствующее ведро, а затем ведро сравнивается, чтобы найти правильную пару ключ-значение.