Что такое модуль heapq Python?
пробовал "heapq" и пришел к выводу, что мои ожидания отличаются от того, что я вижу на экране. Мне нужно, чтобы кто-то объяснил, как это работает и где это может быть полезно.
из книги модуль Python недели в пункте 2.2 сортировка написано
Если вам нужно поддерживать отсортированный список при добавлении и удалении значений, проверить heapq. Используя функции в heapq для добавления или удаления элементы из списка, вы можете поддерживать порядок сортировки списка с помощью низко над головой.
вот что я делаю и вам.
import heapq
heap = []
for i in range(10):
heap.append(i)
heap
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
heapq.heapify(heap)
heapq.heappush(heap, 10)
heap
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
heapq.heappop(heap)
0
heap
[1, 3, 2, 7, 4, 5, 6, 10, 8, 9] <<< Why the list does not remain sorted?
heapq.heappushpop(heap, 11)
1
heap
[2, 3, 5, 7, 4, 11, 6, 10, 8, 9] <<< Why is 11 put between 4 and 6?
Итак, как вы видите, список "куча" не сортируется вообще, на самом деле, чем больше вы добавляете и удаляете элементы, тем более загроможденным он становится. Вытесненные ценности занимают необъяснимые позиции. Что происходит?
3 ответов
на heapq модуль поддерживает куча инвариант, что не то же самое, что поддерживать фактический объект списка в отсортированном порядке.
слово heapq документация:
кучи-это двоичные деревья, для которых каждый родительский узел имеет значение меньше или равно любому из его дочерних узлов. Эта реализация использует массивы, для которых
heap[k] <= heap[2*k+1]иheap[k] <= heap[2*k+2]для всехk, подсчет элементов от нуля. Для для сравнения, несуществующие элементы считаются бесконечными. Интересным свойством кучи является то, что ее наименьший элемент всегда является корнем,heap[0].
это означает, что очень эффективно найти наименьший элемент (просто возьмите heap[0]), что отлично подходит для очереди приоритетов. После этого следующие 2 значения будут больше (или равны), чем 1-й, а следующие 4 после этого будут больше, чем их "родительский" узел, тогда следующие 8 будут больше, так далее.
вы можете прочитать больше о теории за datastructure в раздел теории документации. Вы также можете посмотреть эта лекция из курса MIT OpenCourseWare введение в алгоритмы, которая объясняет алгоритм в общих чертах.
кучу можно превратить обратно в отсортированный список очень эффективно:
def heapsort(heap):
return [heapq.heappop(heap) for _ in range(len(heap))]
просто вытащив следующий элемент из кучи. Используя sorted(heap) должно быть быстрее тем не менее, как TimSort воспользуется частичным упорядочением, уже присутствующим в куче.
вы бы использовали кучу, если вас интересует только наименьшее значение или первое n наименьшие значения, особенно если вы заинтересованы в этих значениях на постоянной основе; добавление новых элементов и удаление наименьшего очень эффективно, более того, чем прибегать к списку каждый раз, когда вы добавили значение.
Ваша книга не так! как вы демонстрируете, куча не является отсортированным списком (хотя отсортированный список является кучей). Что такое куча? Процитировать руководство по разработке алгоритмов Skiena
кучи-простая и элегантная структура данных для эффективной поддержки операций очереди приоритетов insert и extract-min. Они работают, поддерживая частичный порядок на множестве элементов, который слабее отсортированного порядка (поэтому он может быть эффективным для поддержания), но сильнее, чем случайный порядок (поэтому минимальный элемент можно быстро идентифицировать).
по сравнению с отсортированным списком куча подчиняется более слабому условию кучи инвариант. Прежде чем определить его, сначала подумайте, почему расслабляющее состояние может быть полезно. Ответ-более слабое условие легче поддерживать. Вы можете сделать меньше с кучей, но вы можете сделать это быстрее.
куча имеет три операции:
- найти-минимум равен O (1)
- вставить O (log n)
- удалить-мин. O (log n)
Crucially Insert - Это O(log n), который бьет O (n) для отсортированного списка.
что такое инвариант кучи? "Бинарное дерево, где родители доминируют над своими детьми". То есть, "p ≤ c для всех детей c из p". Skiena иллюстрирует с изображениями и идет дальше продемонстрировать алгоритм для вводить элементы пока поддерживающ инвариантный. Если вы немного подумаете, то сможете изобрести их сами. (Подсказка: они известны как пузырь вверх и пузырь вниз)
хорошей новостью является то, что Python с батареями реализует все для вас, в heapq модуль. Он не определяет тип кучи (который, я думаю, было бы проще использовать), но предоставляет их в качестве вспомогательных функций в списке.
мораль: Если вы пишете алгоритм, используя отсортированный список, но только когда-либо проверяете и удаляете с одного конца, то вы можете сделать алгоритм более эффективным, используя кучу.
для задачи, в которой полезна структура данных кучи, прочитайте https://projecteuler.net/problem=500
существует некоторое недопонимание реализации структуры данных кучи. The heapq модуль на самом деле является вариант двоичные кучи реализация, где элементы кучи хранятся в списке, как описано здесь:https://en.wikipedia.org/wiki/Binary_heap#Heap_implementation
Цитирую Википедию:
кучи обычно реализуются с помощью массива. Любое двоичное дерево может храниться в массиве, но поскольку двоичная куча всегда полное двоичное дерево, его можно хранить компактно. Для указателей не требуется места; вместо этого Родительский и дочерний элементы каждого узла могут быть найдены арифметикой по индексам массива.
это изображение ниже должно помочь вам почувствовать разницу между представлением дерева и списка кучи и (обратите внимание, что это максимальная куча, которая является обратной обычной мин-куче!):
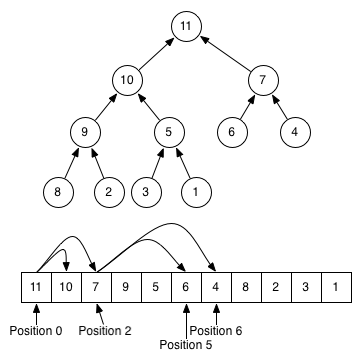
В общем случае структура данных кучи отличается от отсортированного списка тем, что он жертвует некоторой информацией о том, является ли какой-либо конкретный элемент больше или меньше любого другого. Куча только может сказать, что этот конкретный элемент меньше, чем он Родительский и больше, чем это дети. Чем меньше информации хранит структура данных, тем меньше времени/памяти требуется для ее изменения. Сравните сложность некоторых операций между кучей и отсортированным массивом:
Heap Sorted array
Average Worst case Average Worst case
Space O(n) O(n) O(n) O(n)
Search O(n) O(n) O(log n) O(log n)
Insert O(1) O(log n) O(n) O(n)
Delete O(log n) O(log n) O(n) O(n)