DBSCAN в scikit-узнайте о Python: сохраните точки кластера в массиве
пример демонстрация алгоритма кластеризации DBSCAN обучения Scikit я пытаюсь сохранить в массиве x, y каждого класса кластеризации
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
from sklearn.preprocessing import StandardScaler
from pylab import *
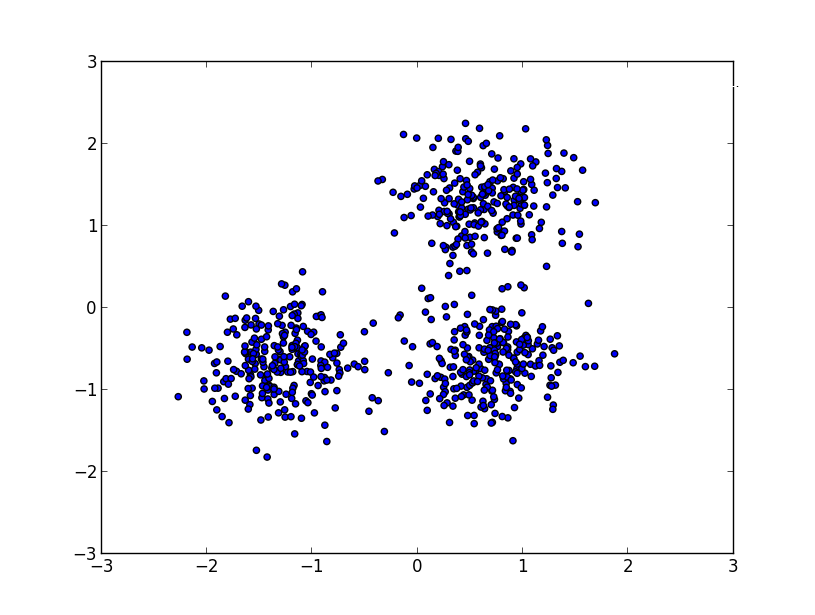
# Generate sample data
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4, random_state=0)
X = StandardScaler().fit_transform(X)
xx, yy = zip(*X)
scatter(xx,yy)
show()
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
core_samples = db.core_sample_indices_
labels = db.labels_
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
print n_clusters_
3
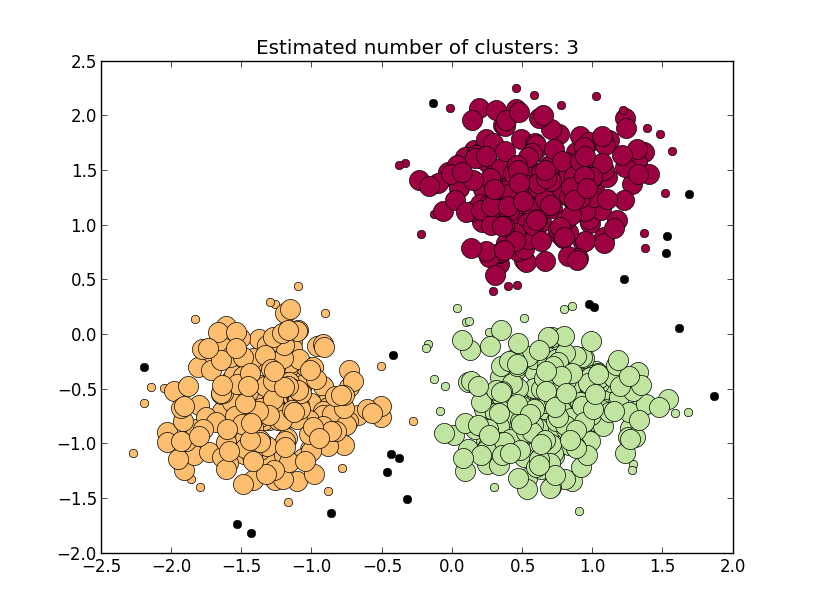
Я пытаюсь понять реализацию DBSCAN с помощью scikit-learn, но с этого момента у меня возникли проблемы. Количество кластеров равно 3 (n_clusters_), и я хочу сохранить x, y каждого кластера в массиве
2 ответов
первый кластер составляет X[labels == 0], etc.:
clusters = [X[labels == i] for i in xrange(n_clusters_)]
и выбивающиеся
outliers = X[labels == -1]
Что вы подразумеваете под "каждого кластера"?
в DBSCAN кластеры не представлены как центроиды, как в k-средних, поэтому нет очевидного представления кластера, кроме его членов. У вас уже есть положение X и y членов кластера, поскольку они являются входными данными.
поэтому я не уверен, в чем вопрос.