Диагностика runaway CPU в a.Net применение продукции
кто-нибудь знает инструмент, который может помочь мне выяснить почему мы видим runaway CPU в управляемом приложении?
Что я не ищут:
процесс Explorer, он имеет эту удивительную функцию, которая позволяет вам видеть CPU в потоке, но вы не получаете управляемые трассировки стека. Кроме того, он требует довольно опытного пользователя.
Windbg + SOS, он, вероятно, может быть раньше, чтобы понять, что происходит, хватая кучу свалок. Но это нетривиально автоматизировать и немного тяжеловато для этого.
полноценный профилировщик (например, dottrace или redgate), лицензирование является сложным, и инструмент является излишним, который требует достаточно тяжелой установки.
Я ищу:
- простой exe (без установщика), который я могу отправить клиенту. После того, как они запустить его в течение 10 минут, он генерирует файл, который они присылают мне. Файл содержит сведения о потоках, которые потребляли больше всего CPU и их трассировки стека в течение этого времени.
технически я знаю, что такой инструмент можно создать (используя ICorDebug), но не хочу инвестировать время, если такой инструмент уже существует.
Итак, кто-нибудь знает о чем-нибудь подобном?
10 ответов
основным решением
- схватила управлял трассировки стека каждого управляемого потока.
- схватила основная статистика потоков для каждого управляемого потока (режим пользователя и время ядра)
- подождите немного
- повторить (1-3)
- проанализируйте результаты и найдите потоки, потребляющие наибольшее количество использования ЦП, представьте пользователю следы стека этих потоков.
Управляемый Vs. Unmanged Следы Стека
существует большая разница между управляемыми и несвязанными трассировками стека. Трассировки управляемого стека содержат информацию о фактических вызовах .Net, а неуправляемые-список неуправляемых указателей функций. Поскольку .Net jitted, адрес неуправляемых указателей функций мало полезен при диагностике проблемы с управляемыми приложениями.
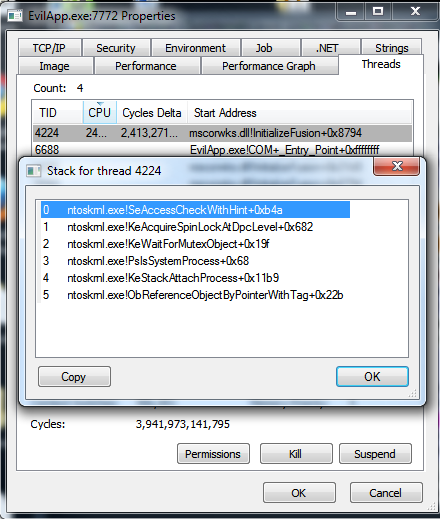
Как получить неуправляемую трассировку стека для произвольного .Net процесс?
здесь два варианта вы можете получить управляемые трассировки стека для управляемого приложения.
- использовать профилирование CLR (он же. ICORPROFILER API)
- используйте отладку CLR (aka. ICORDEBUG API)
что лучше в производство?
API отладки среды CLR имеют очень важное преимущество перед профилирующими, они позволяют подключаться к запуск процесса. Это может иметь решающее значение, когда диагностика проблем производительности в производстве. Довольно часто runaway CPU всплывает после нескольких дней использования приложения из-за какой-то неожиданной ветви выполнения кода. В этот момент времени перезапуск приложения (для того, чтобы профилировать его) не является опцией.
cpu-analyzer.exe
Итак, я написал небольшой инструмент, который не имеет установщика и выполняет основное решение выше, используя ICorDebug. Его на основе источник mdbg который все объединены в один exe.
требуется настраиваемое (по умолчанию 10) количество трассировок стека для всех управляемых потоков с настраиваемым интервалом (по умолчанию 1000 мс).
вот пример вывода:
C:\>cpu-analyzer.exe evilapp ------------------------------------ 4948 Kernel Time: 0 User Time: 89856576 EvilApp.Program.MisterEvil EvilApp.Program.b__0 System.Threading.ExecutionContext.Run System.Threading._ThreadPoolWaitCallback.PerformWaitCallbackInternal System.Threading._ThreadPoolWaitCallback.PerformWaitCallback ... more data omitted ...
не стесняйтесь, чтобы дать инструмент удар. Его можно скачать из моего блога.
редактировать
вот нить показывает, как я использую cpu-analyzer для диагностики такой проблемы в производственном приложении.
профилировщик, вероятно, правильный ответ здесь.
Если вы не хотите "полноценный профилировщик", как DotTrace, вы можете попробовать SlimTune. Он работает довольно хорошо и полностью свободен (и с открытым исходным кодом).
похоже, вам нужен настоящий профайлер, но я подумал, что просто выброшу это: PerfMon. Он поставляется с windows, вы можете настроить профиль perfmon, который вы можете отправить пользователю, они могут захватить и отправить вам журнал.
вот несколько ссылок, которые я держал вокруг каждый раз, когда мне нужно обновление perfmon: журнал TechNet с 2008 года и сообщение из расширенного блога отладки .NET.
Мне повезло с Red Gate муравьи профилировщик. Однако это требует установки. Я почти уверен, что у них нет удаленного выбора.
Я знаю, что вы конкретно сказали, что не хотите принимать сложные свалки и использовать WinDbg + Sos для их анализа.
однако в этом может не быть необходимости. Я бы предложил использовать WinDbg в любом случае, но вместо использования дампов просто присоединитесь к процессу, когда вы видите убегающие потоки. Тогда все, что вам нужно сделать, это запустить !команда беглецов. Это даст вам общее время работы для каждого потока. Беглые потоки будут в верхней части списка. Теперь все, что тебе нужно сделать бежит !clrstack для верхнего потока (или потоков, как это может быть).
Е. Г. если нить 4-это ваш главный подозреваемый, сделать ~4е!clrstack, чтобы получить управляемый стек для этого потока. Это должно сказать вам, что делает беглая нить.
Я согласен, что WinDbg - не самый простой инструмент для многих вещей, но это может оказаться довольно простым, поэтому я надеюсь, что вы простите меня за публикацию чего-то, чего вы на самом деле не делали.
Если WinDbg все еще не может быть и речи, не стесняйтесь комментировать.
используйте Sysinternals ProcDump, чтобы получить мини-дамп и windbg+sos для его анализа.
утилита ProcDump доступна здесь:http://technet.microsoft.com/en-us/sysinternals/dd996900.aspx
просто отправьте exe пользователю и скажите ему.ей бежать (например):
ProcDump MyProgram.exe -c 90 -s 10
это сбросит процесс, если он потребляет более 90% CPU в течение более 10 секунд
используйте управляемый отладчик. Помогал мне раньше. Всего несколько файлов. Вероятно, вы могли бы просто увидеть, что происходит (возможно, обработка исключений застряла в цикле).
Если вы управляете кодом вместо профилировщика, который стоит использовать, я обнаружил, что бросание сообщения журнала в ваш код чертовски полезно для обнаружения бесконечных циклов и общих многопоточных прогрессий.
Я.е
step 1 msg
step 2 msg
поток теперь 100% и нет шага 3 msg = ошибка.
Я думаю,вы должны посмотреть на использование памяти и диска. Если у машины заканчивается память и необходимо начать использовать виртуальную память (на диске), вы увидите всплеск активности процессора и диска. В таких условиях то, что выглядит как узкое место процессора, на самом деле является узким местом памяти.
чем хуже проблема, тем легче найти эта техника.
есть инструмент, который вы можете получить, называемый Stackshot, который может помочь в вашем случае. Посмотри здесь и здесь.