дисбаланс данных в SVM с использованием libSVM
Как установить параметры гаммы и стоимости в libSVM, когда я использую несбалансированный набор данных, состоящий из 75% "истинных" меток и 25% "ложных" меток? Я получаю постоянную ошибку, когда все предсказанные метки установлены на "True" из-за дисбаланса данных.
Если проблема не в libSVM, а в моем наборе данных, как мне справиться с этим дисбалансом с теоретической точки зрения машинного обучения? *Количество функций, которые я использую, составляет 4-10, и у меня есть небольшой набор 250 точек данных.
3 ответов
дисбаланс классов не имеет ничего общего с выбором C и гамма, для решения этой проблемы вы должны использовать схема взвешивания класса который доступен, например (построенные на libsvm)
выбор C и gamma выполняется с помощью поиска сетки с перекрестной проверкой. Вы должны попробовать широкий диапазон значений здесь, для C разумно выбрать значения между 1 и 10^15 а простой и хорошей эвристики из gamma значения диапазона должны вычислять попарные расстояния между всеми вашими точками данных и выбирать гамму в соответствии с процентилями этого распределения - подумайте о том, чтобы поместить в каждую точку гауссово распределение с дисперсией, равной 1/gamma - если выбрать такой gamma что это распределение перекрывает много точек, вы получите очень "гладкую" модель, в то время как использование небольшой дисперсии приводит к переоснащению.
несбалансированных наборов данных могут быть решены различными способами. Баланс классов не влияет на параметры ядра, такие как gamma для ядра RBF.
два самых популярных подхода:
-
использовать различные наказания классификации в классе, это в основном означает, что изменение
C. Как правило, наименьший класс взвешивается выше, общий подход -npos * wpos = nneg * wneg. LIBSVM позволяет сделать это, используя его-wXфлаги. - Подвыборка перепредставленного класса чтобы получить равное количество положительных и отрицательных сторон и продолжить обучение, как вы традиционно для сбалансированного набора. Обратите внимание, что вы в основном игнорируете большой кусок данных таким образом, что интуитивно является плохой идеей.
Я знаю, что это было предложено некоторое время назад, но я хотел бы ответить на него, так как вы можете найти мой ответ полезным.
Как уже упоминалось, вы можете рассмотреть возможность использования разных весов для классов меньшинств или использования различных штрафов за неправильную классификацию. Однако есть более умный способ справиться с несбалансированными наборами данных.
можно использовать SMOTE (Synthetic Minority Over-sampling Technique) алгоритм генерации синтезированных данных для класса меньшинства. Это простой алгоритм, который может справиться с некоторыми наборами данных дисбаланса довольно хорошо.
на каждой итерации алгоритма SMOTE рассматривает два случайных экземпляра класса меньшинства и добавляет искусственный пример того же класса где-то между ними. Алгоритм продолжает вводить набор данных с образцами, пока два класса не станут сбалансированными или некоторыми другими критерии (например, добавить определенное количество примеров). Ниже вы можете найти изображение, описывающее, что алгоритм делает для простого набора данных в 2D векторном пространстве.
связывание веса с классом меньшинства является частным случаем этого алгоритма. Когда вы связываете вес $w_i$ с экземпляром i, вы в основном добавляете дополнительные экземпляры $w_i - 1$ поверх экземпляра i!
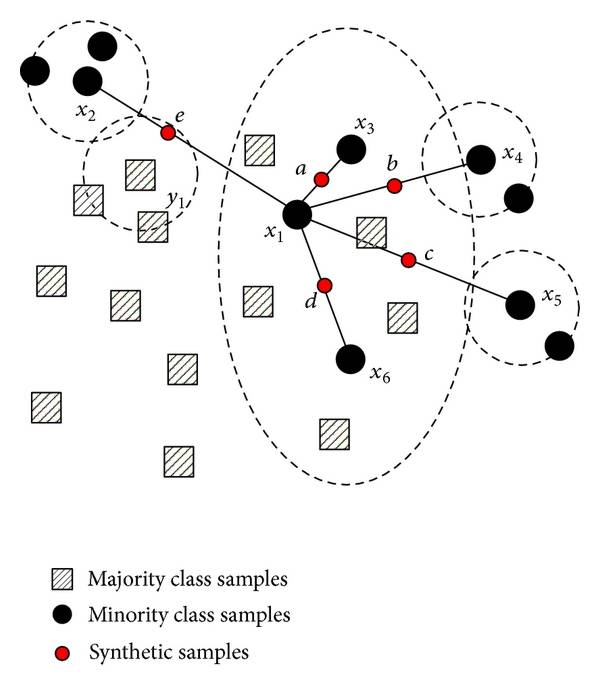
Что вам нужно сделать, это увеличить исходный набор данных с образцами, созданными этим алгоритмом, и обучить SVM с этим новым набором данных. Вы также можете найти много реализации в интернете на разных языках, таких как Python и Matlab.
есть и другие расширения этого алгоритма, я могу указать вам материалы, Если вы хотите.
чтобы проверить классификатор, вам нужно разделить набор данных на test и train, добавьте синтетические экземпляры в набор train (НЕ ДОБАВЛЯТЬ В ТЕСТ SET), тренируйте модель на наборе поезда, и в конце концов испытайте его на наборе теста. Если вы рассмотрите сгенерированные экземпляры при тестировании, вы получите предвзятую (и смехотворно более высокую) точность и отзыв.