Двоичная строка в Hex c++
при изменении двоичной строки на шестнадцатеричную я мог сделать это только до определенного размера на основе ответов, которые я нашел. Но я хочу изменить массивные двоичные строки в их полный шестнадцатеричный аналог более эффективным способом, чем это, который является единственным способом, с которым я столкнулся, что делает это полностью:
for(size_t i = 0; i < (binarySubVec.size() - 1); i++){
string binToHex, tmp = "0000";
for (size_t j = 0; j < binaryVecStr[i].size(); j += 4){
tmp = binaryVecStr[i].substr(j, 4);
if (!tmp.compare("0000")) binToHex += "0";
else if (!tmp.compare("0001")) binToHex += "1";
else if (!tmp.compare("0010")) binToHex += "2";
else if (!tmp.compare("0011")) binToHex += "3";
else if (!tmp.compare("0100")) binToHex += "4";
else if (!tmp.compare("0101")) binToHex += "5";
else if (!tmp.compare("0110")) binToHex += "6";
else if (!tmp.compare("0111")) binToHex += "7";
else if (!tmp.compare("1000")) binToHex += "8";
else if (!tmp.compare("1001")) binToHex += "9";
else if (!tmp.compare("1010")) binToHex += "A";
else if (!tmp.compare("1011")) binToHex += "B";
else if (!tmp.compare("1100")) binToHex += "C";
else if (!tmp.compare("1101")) binToHex += "D";
else if (!tmp.compare("1110")) binToHex += "E";
else if (!tmp.compare("1111")) binToHex += "F";
else continue;
}
hexOStr << binToHex;
hexOStr << " ";
}
его тщательный и абсолютный, но медленный.
есть ли более простой способ сделать это?
9 ответов
обновление добавлено сравнение и бенчмарки в конце
вот еще один дубль, основанный на идеальном хэше. Идеальный хэш был создан с помощью gperf (как описано здесь: можно ли сопоставить строку с int быстрее, чем с помощью hashmap?).
я дополнительно оптимизирован путем перемещения функции локальной статики из Пути и маркировки hexdigit() и hash() as constexpr. Это удаляет ненужные накладные расходы инициализации и дает компилятор полный зал для оптимизации/
я не ожидаю, что дела пойдут намного быстрее.
вы мог бы попробуйте прочитать, например, 1024 кусочка за раз, если это возможно, и дайте компилятору возможность векторизовать операции с помощью наборов инструкций AVX/SSE. (я не проверял сгенерированный код, чтобы увидеть, произойдет ли это.)
полный пример кода для перевода std::cin to std::cout в потоковом режиме есть:
#include <iostream>
int main()
{
char buffer[4096];
while (std::cin.read(buffer, sizeof(buffer)), std::cin.gcount())
{
size_t got = std::cin.gcount();
char* out = buffer;
for (auto it = buffer; it < buffer+got; it += 4)
*out++ = Perfect_Hash::hexchar(it);
std::cout.write(buffer, got/4);
}
}
здесь Perfect_Hash класс, слегка отредактированный и расширенный с помощью hexchar поиск. Обратите внимание, что он проверяет ввод в DEBUG строит с помощью assert:
#include <array>
#include <algorithm>
#include <cassert>
class Perfect_Hash {
/* C++ code produced by gperf version 3.0.4 */
/* Command-line: gperf -L C++ -7 -C -E -m 100 table */
/* Computed positions: -k'1-4' */
/* maximum key range = 16, duplicates = 0 */
private:
static constexpr unsigned char asso_values[] = {
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 15, 7, 3, 1, 0, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27,
27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27, 27};
template <typename It>
static constexpr unsigned int hash(It str)
{
return
asso_values[(unsigned char)str[3] + 2] + asso_values[(unsigned char)str[2] + 1] +
asso_values[(unsigned char)str[1] + 3] + asso_values[(unsigned char)str[0]];
}
static constexpr char hex_lut[] = "???????????fbead9c873625140";
public:
#ifdef DEBUG
template <typename It>
static char hexchar(It binary_nibble)
{
assert(Perfect_Hash::validate(binary_nibble)); // for DEBUG only
return hex_lut[hash(binary_nibble)]; // no validation!
}
#else
template <typename It>
static constexpr char hexchar(It binary_nibble)
{
return hex_lut[hash(binary_nibble)]; // no validation!
}
#endif
template <typename It>
static bool validate(It str)
{
static constexpr std::array<char, 4> vocab[] = {
{{'?', '?', '?', '?'}}, {{'?', '?', '?', '?'}}, {{'?', '?', '?', '?'}},
{{'?', '?', '?', '?'}}, {{'?', '?', '?', '?'}}, {{'?', '?', '?', '?'}},
{{'?', '?', '?', '?'}}, {{'?', '?', '?', '?'}}, {{'?', '?', '?', '?'}},
{{'?', '?', '?', '?'}}, {{'?', '?', '?', '?'}},
{{'1', '1', '1', '1'}}, {{'1', '0', '1', '1'}},
{{'1', '1', '1', '0'}}, {{'1', '0', '1', '0'}},
{{'1', '1', '0', '1'}}, {{'1', '0', '0', '1'}},
{{'1', '1', '0', '0'}}, {{'1', '0', '0', '0'}},
{{'0', '1', '1', '1'}}, {{'0', '0', '1', '1'}},
{{'0', '1', '1', '0'}}, {{'0', '0', '1', '0'}},
{{'0', '1', '0', '1'}}, {{'0', '0', '0', '1'}},
{{'0', '1', '0', '0'}}, {{'0', '0', '0', '0'}},
};
int key = hash(str);
if (key <= 26 && key >= 0)
return std::equal(str, str+4, vocab[key].begin());
else
return false;
}
};
constexpr unsigned char Perfect_Hash::asso_values[];
constexpr char Perfect_Hash::hex_lut[];
#include <iostream>
int main()
{
char buffer[4096];
while (std::cin.read(buffer, sizeof(buffer)), std::cin.gcount())
{
size_t got = std::cin.gcount();
char* out = buffer;
for (auto it = buffer; it < buffer+got; it += 4)
*out++ = Perfect_Hash::hexchar(it);
std::cout.write(buffer, got/4);
}
}
демонстрационный выход, например od -A none -t o /dev/urandom | tr -cd '01' | dd bs=1 count=4096 | ./test
придумал три разных подхода:
- наивный.cpp (нет хаков, нет библиотек); видео разборки on Godbolt
- дух.cpp (Trie);
Liveразборки на Pastebin- и ответ: идеальный.cpp хэш на основе; Живая разборка on Godbolt
чтобы сделать некоторые сравнения, я
- скомпилировал их все с тем же компилятором (GCC 4.9) и флагами (
-O3 -march=native -g0 -DNDEBUG)- оптимизированный вход / выход, чтобы он не читал 4 символа / писать одиночные символы
- создан большой входной файл (1 гигабайт)
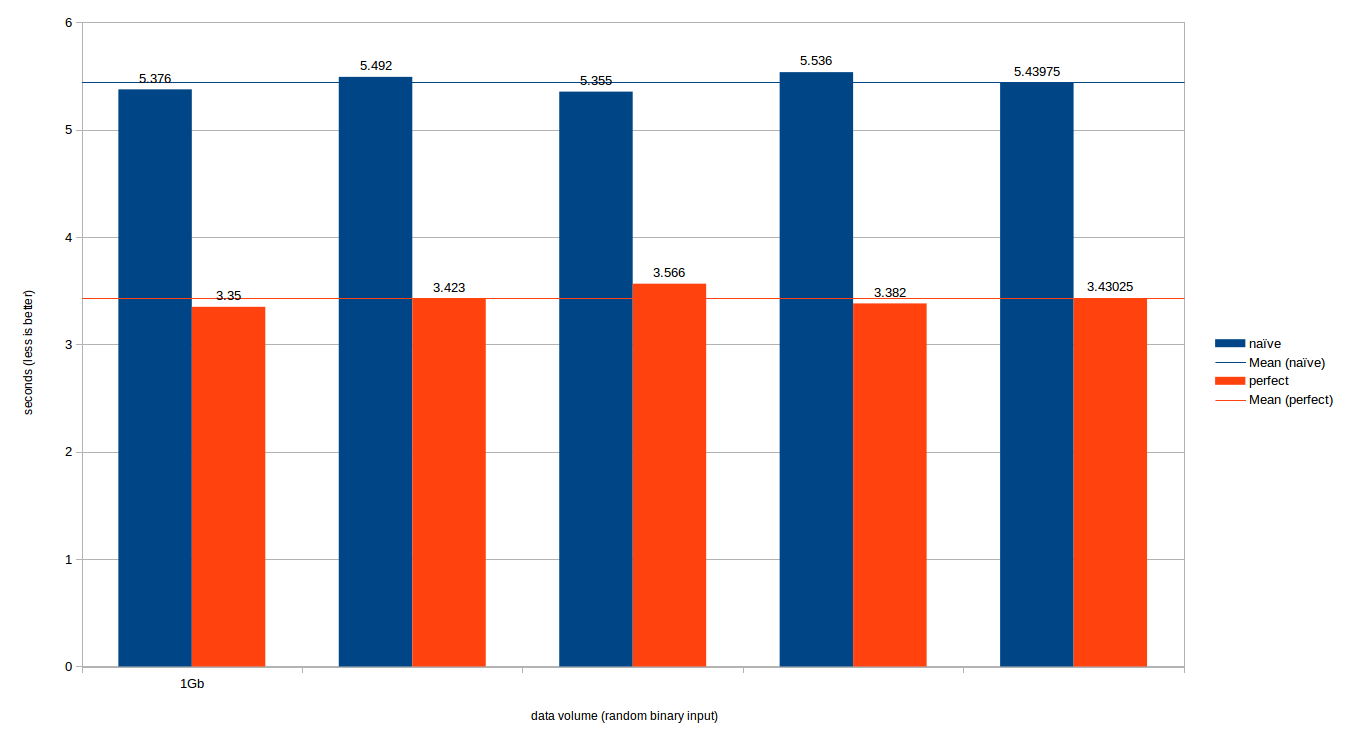
вот результаты:
- Удивительно, но
naiveподход с первого ответа делает довольно хорошо- Spirit делает здесь очень плохо; это Сети 3.4 MB / s, так что весь файл займет 294 секунды (!!!). Мы оставили это вне графика
- средняя пропускная способность составляет ~720 МБ / с для наивный.cpp и ~1.14 ГБ/с -идеальный.cpp
- это делает идеальный хэш-подход примерно на 50% быстрее, чем наивный подход.
*резюме я бы сказал, что наивный подход был достаточно хорош как я его разместил по прихоти 10 часов назад. Если вы действительно хотите высокую пропускную способность, идеальный хэш-хорошее начало, но рассмотрите ручную прокатку решения на основе SIMD
вот как я бы сделал это:
-
найти наименьшее положительное целое число
nтакие, что все эти целые числа имеют разные остатки по модулюn:0x30303030 0x30303031 0x30303130 0x30303131 0x30313030 0x30313031 0x30313130 0x30313131 0x31303030 0x31303031 0x31303130 0x31303131 0x31313030 0x31313031 0x31313130 0x31313131
это ASCII-представления "0000", "0001" и т. д. Я перечислил их в порядок, предполагая, что ваша машина является big-endian; если это little-endian, представление, например, "0001" будет 0x31303030, а не 0x30303031. Тебе нужно сделать это только один раз. n не будет очень большим - я ожидал бы, что он будет меньше 100.
- построить таблицу
char HexChar[n]СHexChar[0x30303030 % n] = '0', HexChar[0x30303031 % n] = '1'etc. (илиHexChar[0x31303030 % n] = '1'etc. если ваша машина маленькая-endian).
теперь преобразование молниеносно (я предполагаю sizeof (int) = 4):
unsigned int const* s = binaryVecStr[a].c_str();
for (size_t i = 0; i < binaryVecStr[a].size(); i += 4, s++)
hexOStr << HexChar[*s % n];
обновление 2 посмотреть здесь для моего идеального решения на основе хэша. Это решение было бы моим предпочтением, потому что
- он компилируется намного быстрее
- он имеет более предсказуемую среду выполнения (есть нулевые распределения происходит, так как все данные являются статическими)
редактировать действительно, теперь бенчмаркинг показал, что идеальное решение хэша примерно 340 x быстрее!--27--> чем подход Духа. смотрите здесь:
обновление
добавил решение на основе Trie.
таблица поиска здесь использует внутреннюю реализацию Trie Boost Spirit для быстрого поиска.
конечно, заменить out например, с вектором back_inserter или ostreambuf_iterator<char> в ваш поток строк, если хотите. Сейчас она не выделяет даже 4 символа (хотя, конечно, таблица поиска выделяется один раз).
вы также можете тривиально заменить входные итераторы тем, какой у вас есть диапазон ввода, без изменения строки остальной части кода.
#include <iostream>
#include <boost/spirit/include/qi.hpp>
#include <boost/spirit/include/phoenix.hpp>
namespace qi = boost::spirit::qi;
int main() {
std::ostreambuf_iterator<char> out(std::cout);
qi::symbols<char, char> lookup_table;
lookup_table.add
("0000", '0')
("0001", '1')
("0010", '2')
("0011", '3')
("0100", '4')
("0101", '5')
("0110", '6')
("0111", '7')
("1000", '8')
("1001", '9')
("1010", 'a')
("1011", 'b')
("1100", 'c')
("1101", 'd')
("1110", 'e')
("1111", 'f')
;
boost::spirit::istream_iterator bof(std::cin), eof;
if (qi::parse(bof, eof, +lookup_table [ *boost::phoenix::ref(out) = qi::_1 ]))
return 0;
else
return 255;
}
при тестировании с некоторыми случайными данными типа od -A none -t o /dev/urandom | tr -cd '01' | dd bs=1 count=4096 | ./test вы получаете
элементарно ответ:чтение ввода из потока и вывод одного символа каждые 4 байта.
вот так:
char nibble[4]; while (std::cin.read(nibble, 4)) { std::cout << "0123456789abcdef"[ (nibble[0]!='0')*8 + (nibble[1]!='0')*4 + (nibble[2]!='0')*2 + (nibble[3]!='0')*1 ]; }вы действительно можете сделать преобразование таблицей поиска. Не используйте карту, поскольку она основана на дереве, и в конечном итоге будет преследовать много указателей. Однако,
boost::flat_mapможет быть в порядке.
template <class RanIt, class OutIt>
void make_hex(RanIt b, RanIt e, OutIt o) {
static const char rets[] = "0123456789ABCDEF";
if ((e-b) %4 != 0)
throw std::runtime_error("Length must be a multiple of 4");
while (b != e) {
int index =
((*(b + 0) - '0') << 3) |
((*(b + 1) - '0') << 2) |
((*(b + 2) - '0') << 1) |
((*(b + 3) - '0') << 0);
*o++ = rets[index];
b += 4;
}
}
по крайней мере, навскидку, кажется, что это должно быть так же быстро, как и все, что может быть-мне кажется, что он близко подходит к минимуму обработки на каждом входе, необходимом для выхода.
чтобы максимизировать скорость, он минимизирует проверку ошибок на входе (и, возможно, ниже) голый минимальный. Вы, конечно, можете заверить, что каждый символ на входе был " 0 " или "1", Прежде чем в зависимости от результата вычитания. Кроме того, вы можете легко использовать (*(b + 0) != '0') << 3 для лечения 0 0 как и все остальное, как 1. Аналогично, вы можете использовать:(*(b + 0) == '1') << 3 и 1 обрабатывается как 1, а все остальное как 0.
код избегает зависимостей между 4 вычислениями, необходимыми для вычисления каждого index value, поэтому это должно быть возможно для интеллектуального компилятора делать эти вычисления параллельно.
поскольку он работает только с итераторами, он избегает создания дополнительных копий входных данных, как (например) почти ничего, используя substr может (особенно с реализацией std::string это не включает оптимизацию короткой строки).
в любом случае, использование этого будет выглядеть примерно так:
int main() {
char input[] = "0000000100100011010001010110011110001001101010111100110111101111";
make_hex(input, input+64, std::ostream_iterator<char>(std::cout));
}
поскольку он использует итераторы, он может так же легко (только для одного очевидного примера) принимать входные данные из в istreambuf_iterator для обработки данных непосредственно из файла. Это редко самый быстрый способ сделать, хотя-вы обычно получите лучшую скорость, используя istream::read читать большой кусок, и ostream::write написать большой кусок сразу. Однако это не должно повлиять на фактический код преобразования-вы просто передадите его указатели в свои входные и выходные буферы, и он будет использовать их в качестве итераторов.
Это, кажется, работает.
std::vector<char> binaryVecStr = { '0', '0', '0', '1', '1', '1', '1', '0' };
string binToHex;
binToHex.reserve(binaryVecStr.size()/4);
for (uint32_t * ptr = reinterpret_cast<uint32_t *>(binaryVecStr.data()); ptr < reinterpret_cast<uint32_t *>(binaryVecStr.data()) + binaryVecStr.size() / 4; ++ptr) {
switch (*ptr) {
case 0x30303030:
binToHex += "0";
break;
case 0x31303030:
binToHex += "1";
break;
case 0x30313030:
binToHex += "2";
break;
case 0x31313030:
binToHex += "3";
break;
case 0x30303130:
binToHex += "4";
break;
case 0x31303130:
binToHex += "5";
break;
case 0x30313130:
binToHex += "6";
break;
case 0x31313130:
binToHex += "7";
break;
case 0x30303031:
binToHex += "8";
break;
case 0x31303031:
binToHex += "9";
break;
case 0x30313031:
binToHex += "A";
break;
case 0x31313031:
binToHex += "B";
break;
case 0x30303131:
binToHex += "C";
break;
case 0x31303131:
binToHex += "D";
break;
case 0x30313131:
binToHex += "E";
break;
case 0x31313131:
binToHex += "F";
break;
default:
// invalid input
binToHex += "?";
}
}
std::cout << binToHex;
остерегайтесь, использует несколько assumtpions:
1) char имеет 8 бит (правда не на всех платформах)
2) он требует немного endian (это означает, что он работает по крайней мере на x86, x86_64)
предполагается, что binaryVecStr является std:: vector, но будет работать и со строкой. Он предполагает, что binaryVecStr.size() % 4 == 0
что-то вроде этого может быть
#include <iostream>
#include <string>
#include <iomanip>
#include <sstream>
int main()
{
std::cout << std::hex << std::stoll("100110110010100100111101010001001101100101010110000101111111111",NULL, 2) << std::endl;
std::stringstream ss;
ss << std::hex << std::stoll("100110110010100100111101010001001101100101010110000101111111111", NULL, 2);
std::cout << ss.str() << std::endl;
return 0;
}
Это самый быстрый, который я мог придумать:
#include <iostream>
int main(int argc, char** argv) {
char buffer[4096];
while (std::cin.read(buffer, sizeof(buffer)), std::cin.gcount() > 0) {
size_t got = std::cin.gcount();
char* out = buffer;
for (const char* it = buffer; it < buffer + got; it += 4) {
unsigned long r;
r = it[3];
r += it[2] * 2;
r += it[1] * 4;
r += it[0] * 8;
*out++ = "0123456789abcdef"[r - 15*'0'];
}
std::cout.write(buffer, got / 4);
}
}
это быстрее, чем что-либо еще в этом вопросе, согласно критериям @sehe.
что касается простого способа сделать это, я думаю, что это довольно аккуратно:
std::string bintxt_2_hextxt(const std::string &bin)
{
std::stringstream reader(bin);
std::stringstream result;
while (reader)
{
std::bitset<8> digit;
reader >> digit;
result << std::hex << digit.to_ulong();
}
return result.str();
}
Я не знаю, откуда ваши данные должны быть прочитаны, так что я использовал std::string в качестве входных данных, но если это из текстового файла или потока данных, это не должно быть головной болью для изменения reader быть std::ifstream.
остерегайтесь! Я не знаю, что может произойти, если символы потока не делятся на 8, а также я не тестировал производительность этого код.
видео
вы можете попробовать бинарное дерево решений:
string binToHex;
for (size_t i = 0; i < binaryVecStr[a].size(); i += 4) {
string tmp = binaryVecStr[a].substr(i, 4);
if (tmp[0] == '0') {
if (tmp[1] == '0') {
if (tmp[2] == '0') {
if tmp[3] == '0') {
binToHex += "0";
} else {
binToHex += "1";
}
} else {
if tmp[3] == '0') {
binToHex += "2";
} else {
binToHex += "3";
}
}
} else {
if (tmp[2] == '0') {
if tmp[3] == '0') {
binToHex += "4";
} else {
binToHex += "5";
}
} else {
if tmp[3] == '0') {
binToHex += "6";
} else {
binToHex += "7";
}
}
}
} else {
if (tmp[1] == '0') {
if (tmp[2] == '0') {
if tmp[3] == '0') {
binToHex += "8";
} else {
binToHex += "9";
}
} else {
if tmp[3] == '0') {
binToHex += "A";
} else {
binToHex += "B";
}
}
} else {
if (tmp[2] == '0') {
if tmp[3] == '0') {
binToHex += "C";
} else {
binToHex += "D";
}
} else {
if tmp[3] == '0') {
binToHex += "E";
} else {
binToHex += "F";
}
}
}
}
}
hexOStr << binToHex;
вы также можете рассмотреть более компактное представление из того же дерева решений, например
string binToHex;
for (size_t i = 0; i < binaryVecStr[a].size(); i += 4) {
string tmp = binaryVecStr[a].substr(i, 4);
binToHex += (tmp[0] == '0' ?
(tmp[1] == '0' ?
(tmp[2] == '0' ?
(tmp[3] == '0' ? "0" : "1") :
(tmp[3] == '0' ? "2" : "3")) :
(tmp[2] == '0' ?
(tmp[3] == '0' ? "4" : "5") :
(tmp[3] == '0' ? "6" : "7"))) :
(tmp[1] == '0' ?
(tmp[2] == '0' ?
(tmp[3] == '0' ? "8" : "9") :
(tmp[3] == '0' ? "A" : "B")) :
(tmp[2] == '0' ?
(tmp[3] == '0' ? "C" : "D") :
(tmp[3] == '0' ? "E" : "F"))));
}
hexOStr << binToHex;
обновление: в духе решений ASCII-to-integer:
unsigned int nibble = static_cast<unsigned int*>(buffer);
nibble &= 0x01010101; // 0x31313131 --> 0x01010101
nibble |= (nibble >> 15); // 0x01010101 --> 0x01010303
nibble |= (nibble >> 6); // 0x01010303 --> 0x0105070C
char* hexDigit = hexDigitTable[nibble & 15];
содержание hexDigitTable (типа char[16]) будет зависеть от того, насколько
вы находитесь на немного-с прямым или обратным порядком байтов машина.