Эффективность Java "двойная инициализация скобки"?
на скрытые возможности Java в верхнем ответе упоминается Инициализация Двойной Скобки С очень синтаксис Маня:
Set<String> flavors = new HashSet<String>() {{
add("vanilla");
add("strawberry");
add("chocolate");
add("butter pecan");
}};
это решение создает анонимный внутренний класс с инициализатором экземпляра, который "может использовать любой...] методы в содержащей области".
главный вопрос: это как неэффективное как это звучит? Должно ли его использование ограничиваться одноразовыми инициализациями? (И конечно выпендриваться!)
второй вопрос: новый хэш-набор должен быть "this", используемым в инициализаторе экземпляра ... кто-нибудь может пролить свет на механизм?
третий вопрос: это тоже идиома непонятных использовать в производственном коде?
резюме: очень, очень хорошие ответы, спасибо всем. На вопрос (3) люди чувствовали, что синтаксис должен быть ясным (хотя я бы рекомендовал случайный комментарий, особенно если ваш код будет передаваться разработчикам, которые могут быть не знакомы с ним).
по вопросу (1) сгенерированный код должен выполняться быстро. Экстра. файлы классов вызывают беспорядок файлов jar и немного замедляют запуск программы (благодаря @coobird для измерения этого). @Thilo указал, что сбор мусора может быть затронут, и стоимость памяти для дополнительных загруженных классов может быть фактором в некоторых случаях.
Вопрос (2) оказался для меня самым интересным. Если я понимаю ответы, то что происходящее в DBI заключается в том, что анонимный внутренний класс расширяет класс объекта, создаваемого оператором new, и, следовательно, имеет значение "this", ссылающееся на создаваемый экземпляр. Очень аккуратно.
в целом, DBI поражает меня как нечто интеллектуальное любопытство. Coobird и другие указывают, что вы можете достичь того же эффекта с массивами.asList, методы varargs, коллекции Google и предлагаемые литералы коллекции Java 7. Новые языки JVM, такие как Scala, JRuby и Groovy также предлагает краткие обозначения для построения списка и хорошо взаимодействует с Java. Учитывая, что DBI загромождает путь к классу, немного замедляет загрузку класса и делает код немного более неясным, я бы, вероятно, уклонялся от него. Тем не менее, я планирую повесить это на друга, который только что получил свой SCJP и любит добродушные поединки о семантике Java! ;-) Спасибо всем!
7/2017: Baeldung хорошее резюме двойной инициализации скобки и рассматривает это анти-паттерн.
12/2017: @Basil Bourque отмечает, что в новой Java 9 вы можете сказать:
Set<String> flavors = Set.of("vanilla", "strawberry", "chocolate", "butter pecan");
это наверняка путь. Если вы застряли с более ранней версией, взгляните на Коллекции Google ' ImmutableSet.
15 ответов
вот проблема, когда я слишком увлекаюсь анонимными внутренними классами:
2009/05/27 16:35 1,602 DemoApp2.class
2009/05/27 16:35 1,976 DemoApp2.class
2009/05/27 16:35 1,919 DemoApp2.class
2009/05/27 16:35 2,404 DemoApp2.class
2009/05/27 16:35 1,197 DemoApp2.class
/* snip */
2009/05/27 16:35 1,953 DemoApp2.class
2009/05/27 16:35 1,910 DemoApp2.class
2009/05/27 16:35 2,007 DemoApp2.class
2009/05/27 16:35 926 DemoApp2.class
2009/05/27 16:35 4,104 DemoApp2.class
2009/05/27 16:35 2,849 DemoApp2.class
2009/05/27 16:35 926 DemoApp2.class
2009/05/27 16:35 4,234 DemoApp2.class
2009/05/27 16:35 2,849 DemoApp2.class
/* snip */
2009/05/27 16:35 614 DemoApp2.class
2009/05/27 16:35 2,344 DemoApp2.class
2009/05/27 16:35 1,551 DemoApp2.class
2009/05/27 16:35 1,604 DemoApp2.class
2009/05/27 16:35 1,809 DemoApp2.class
2009/05/27 16:35 2,022 DemoApp2.class
это все классы, которые были созданы, когда я делал простое приложение, и использовали обильное количество анонимных внутренних классов-каждый класс будет скомпилирован в отдельный .
"инициализация двойной скобки", как уже упоминалось, является анонимным внутренним классом с блоком инициализации экземпляра, что означает создание нового класса для каждой "инициализации" все с целью обычно создания одного объекта.
учитывая, что виртуальной машине Java нужно будет прочитать все эти классы при их использовании, что может привести к некоторому времени в проверка байт-кода.
Джошуа Блоха коллекция литералов предложение на Проект Монету. было примерно так:
List<Integer> intList = [1, 2, 3, 4];
Set<String> strSet = {"Apple", "Banana", "Cactus"};
Map<String, Integer> truthMap = { "answer" : 42 };
к сожалению,не пробился ни в Java 7, ни в 8 и был отложен на неопределенный срок.
эксперимент
вот простой эксперимент, который я тестировал - сделайте 1000 ArrayListС ЭЛЕМЕНТАМИ "Hello" и "World!" добавил к ним через add метод, используя два метода:
Метод 1: Инициализация Двойной Скобки
List<String> l = new ArrayList<String>() {{
add("Hello");
add("World!");
}};
Способ 2: создать ArrayList и add
List<String> l = new ArrayList<String>();
l.add("Hello");
l.add("World!");
я создал простую программу для записи исходного файла Java для выполнения 1000 инициализаций с использованием двух методов:
одно свойство этого подхода, которое до сих пор не было указано, заключается в том, что, поскольку вы создаете внутренние классы, весь содержащий класс захватывается в его области. Это означает, что пока ваш набор жив, он сохранит указатель на содержащий экземпляр (this) и держите это от сбора мусора, что может быть проблемой.
это, и тот факт, что новый класс создается в первую очередь, хотя обычный HashSet будет работать просто отлично (или даже лучше), заставляет меня не хотеть использовать эту конструкцию (хотя я действительно жажду синтаксического сахара).
второй вопрос: новый хэш-набор должен быть "this", используемым в инициализаторе экземпляра ... кто-нибудь может пролить свет на механизм? Я наивно ожидал, что "это" будет относиться к объекту, инициализирующему "ароматы".
так работают внутренние классы. Они получают свои this, но у них также есть указатели на родительский экземпляр, так что вы также можно вызывать методы для содержащего объекта. В случае конфликта имен, внутренний класс (В вашем случае HashSet) имеет приоритет, но вы можете префикс "это" с именем класса, чтобы получить внешний метод, а также.
public class Test {
public void add(Object o) {
}
public Set<String> makeSet() {
return new HashSet<String>() {
{
add("hello"); // HashSet
Test.this.add("hello"); // outer instance
}
};
}
}
чтобы быть ясным в создаваемом анонимном подклассе, вы также можете определить методы там. Например, override HashSet.add()
public Set<String> makeSet() {
return new HashSet<String>() {
{
add("hello"); // not HashSet anymore ...
}
@Override
boolean add(String s){
}
};
}
каждый раз, когда кто-то использует двойную инициализацию скобки, котенок убивается.
помимо того, что синтаксис довольно необычный и не совсем идиоматический (вкус спорный, конечно), вы излишне создаете две значительные проблемы в своем приложении, о котором я только недавно написал в блоге более подробно здесь.
1. Вы создаете слишком много анонимных классов
каждый раз, когда вы используете двойные скобки инициализация производится новый класс. Е. Г. пример:
Map source = new HashMap(){{
put("firstName", "John");
put("lastName", "Smith");
put("organizations", new HashMap(){{
put("0", new HashMap(){{
put("id", "1234");
}});
put("abc", new HashMap(){{
put("id", "5678");
}});
}});
}};
... произведем следующие классы:
Test.class
Test.class
Test.class
Test.class
Test.class
это довольно много накладных расходов для вашего загрузчика классов-даром! Конечно, это не займет много времени инициализации, если вы сделаете это один раз. Но если вы сделаете это 20 ' 000 раз на протяжении всего вашего корпоративного приложения... вся эта куча памяти только для "синтаксического сахара"?
2. Вы потенциально создаете утечку памяти!
если вы берете приведенный выше код и возвращает эту карту из метода, вызывающие этот метод могут ничего не подозревать, держась за очень тяжелые ресурсы, которые не могут быть собраны мусора. Рассмотрим следующий пример:
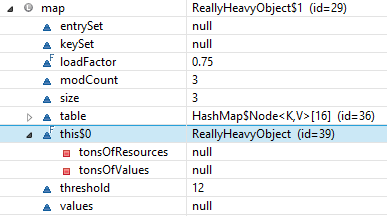
public class ReallyHeavyObject {
// Just to illustrate...
private int[] tonsOfValues;
private Resource[] tonsOfResources;
// This method almost does nothing
public Map quickHarmlessMethod() {
Map source = new HashMap(){{
put("firstName", "John");
put("lastName", "Smith");
put("organizations", new HashMap(){{
put("0", new HashMap(){{
put("id", "1234");
}});
put("abc", new HashMap(){{
put("id", "5678");
}});
}});
}};
return source;
}
}
возвращенный Map теперь будет содержать ссылку на экземпляр включения ReallyHeavyObject. Вы, вероятно, не хотите рисковать этим:
изображения от http://blog.jooq.org/2014/12/08/dont-be-clever-the-double-curly-braces-anti-pattern/
3. Вы можете притвориться, что Java имеет литералы карты
чтобы ответить на ваш фактический вопрос, люди использовали этот синтаксис, чтобы притвориться, что Java имеет что-то вроде литералов карты, подобных существующим литералам массива:
String[] array = { "John", "Doe" };
Map map = new HashMap() {{ put("John", "Doe"); }};
некоторые люди могут найти это синтаксически стимулирования.
взятие следующего тестового класса:
public class Test {
public void test() {
Set<String> flavors = new HashSet<String>() {{
add("vanilla");
add("strawberry");
add("chocolate");
add("butter pecan");
}};
}
}
а затем, распаковывая файл класса, я вижу:
public class Test {
public void test() {
java.util.Set flavors = new HashSet() {
final Test this;
{
this = Test.this;
super();
add("vanilla");
add("strawberry");
add("chocolate");
add("butter pecan");
}
};
}
}
мне это не кажется ужасно неэффективным. Если бы я беспокоился о производительности для чего-то подобного, я бы профилировал его. И на ваш вопрос №2 отвечает приведенный выше код: вы находитесь внутри неявного конструктора( и инициализатора экземпляра) для вашего внутреннего класса, поэтому "this " относится к этому внутреннему классу.
Да, этот синтаксис неясно, но комментарий может прояснить неясное использование синтаксиса. Чтобы уточнить синтаксис, большинство людей знакомы со статическим блоком инициализатора (статические инициализаторы JLS 8.7):
public class Sample1 {
private static final String someVar;
static {
String temp = null;
..... // block of code setting temp
someVar = temp;
}
}
вы также можете использовать аналогичный синтаксис (без слова"static") для использования конструктора (инициализаторы экземпляра JLS 8.6), хотя я никогда не видел, чтобы это использовалось в производственном коде. Об этом известно гораздо меньше.
public class Sample2 {
private final String someVar;
// This is an instance initializer
{
String temp = null;
..... // block of code setting temp
someVar = temp;
}
}
если у вас нет конструктора по умолчанию, то блок из код между { и } превращается компилятором в конструктор. Имея это в виду, распутайте код двойной скобки:
public void test() {
Set<String> flavors = new HashSet<String>() {
{
add("vanilla");
add("strawberry");
add("chocolate");
add("butter pecan");
}
};
}
блок кода между внутренними скобками превращается компилятором в конструктор. Самые внешние скобки ограничивают анонимный внутренний класс. Чтобы сделать этот последний шаг, чтобы сделать все не анонимным:
public void test() {
Set<String> flavors = new MyHashSet();
}
class MyHashSet extends HashSet<String>() {
public MyHashSet() {
add("vanilla");
add("strawberry");
add("chocolate");
add("butter pecan");
}
}
для целей инициализации я бы сказал, что нет никаких накладных расходов вообще (или так мало, что это можно пренебречь). Тем не менее, каждое использование flavors пойдет не против HashSet но вместо этого в отношении MyHashSet. Вероятно, есть небольшие (и, вполне возможно, незначительные) накладные расходы на это. Но опять же, прежде чем беспокоиться об этом, я хотел бы его профилировать.
опять же, на ваш вопрос №2, приведенный выше код является логическим и явным эквивалентом инициализации двойной скобки, и это делает очевидным, где"this " относится: к внутреннему классу, который простирается HashSet.
если у вас есть вопросы о деталях инициализаторов экземпляра, проверьте детали в JLS документация.
утечка склонен
я решил вмешаться. Влияние на производительность включает в себя: диск операции + распаковать (для jar), проверка класса, perm-Gen пространства (для Sun Hotspot JVM). Однако хуже всего то, что он подвержен утечке. Ты не можешь просто вернуться.
Set<String> getFlavors(){
return Collections.unmodifiableSet(flavors)
}
поэтому, если набор экранируется в любую другую часть, загруженную другим загрузчиком классов, и ссылка сохраняется там, все дерево классов+classloader будет утечка. Чтобы этого избежать, копия в HashMap необходимо, new LinkedHashSet(new ArrayList(){{add("xxx);add("yyy");}}). Уже не так мило.
Я сам не использую идиому, вместо этого это похоже на new LinkedHashSet(Arrays.asList("xxx","YYY"));
загрузка многих классов может добавить несколько миллисекунд к началу. Если запуск не так критичен, и вы смотрите на эффективность классов после запуска, нет никакой разницы.
package vanilla.java.perfeg.doublebracket;
import java.util.*;
/**
* @author plawrey
*/
public class DoubleBracketMain {
public static void main(String... args) {
final List<String> list1 = new ArrayList<String>() {
{
add("Hello");
add("World");
add("!!!");
}
};
List<String> list2 = new ArrayList<String>(list1);
Set<String> set1 = new LinkedHashSet<String>() {
{
addAll(list1);
}
};
Set<String> set2 = new LinkedHashSet<String>();
set2.addAll(list1);
Map<Integer, String> map1 = new LinkedHashMap<Integer, String>() {
{
put(1, "one");
put(2, "two");
put(3, "three");
}
};
Map<Integer, String> map2 = new LinkedHashMap<Integer, String>();
map2.putAll(map1);
for (int i = 0; i < 10; i++) {
long dbTimes = timeComparison(list1, list1)
+ timeComparison(set1, set1)
+ timeComparison(map1.keySet(), map1.keySet())
+ timeComparison(map1.values(), map1.values());
long times = timeComparison(list2, list2)
+ timeComparison(set2, set2)
+ timeComparison(map2.keySet(), map2.keySet())
+ timeComparison(map2.values(), map2.values());
if (i > 0)
System.out.printf("double braced collections took %,d ns and plain collections took %,d ns%n", dbTimes, times);
}
}
public static long timeComparison(Collection a, Collection b) {
long start = System.nanoTime();
int runs = 10000000;
for (int i = 0; i < runs; i++)
compareCollections(a, b);
long rate = (System.nanoTime() - start) / runs;
return rate;
}
public static void compareCollections(Collection a, Collection b) {
if (!a.equals(b) && a.hashCode() != b.hashCode() && !a.toString().equals(b.toString()))
throw new AssertionError();
}
}
печать
double braced collections took 36 ns and plain collections took 36 ns
double braced collections took 34 ns and plain collections took 36 ns
double braced collections took 36 ns and plain collections took 36 ns
double braced collections took 36 ns and plain collections took 36 ns
double braced collections took 36 ns and plain collections took 36 ns
double braced collections took 36 ns and plain collections took 36 ns
double braced collections took 36 ns and plain collections took 36 ns
double braced collections took 36 ns and plain collections took 36 ns
double braced collections took 36 ns and plain collections took 36 ns
для создания наборов вы можете использовать заводской метод varargs вместо инициализации двойной скобки:
public static Set<T> setOf(T ... elements) {
return new HashSet<T>(Arrays.asList(elements));
}
в библиотеке Google Collections есть много удобных методов, таких как этот, а также множество других полезных функций.
что касается неясности идиомы, я сталкиваюсь с ней и использую ее в производственном коде все время. Я бы больше беспокоился о программистах, которых смущает идиома, позволяющая писать производственный код.
эффективность в стороне, я редко нахожу себя желающим декларативного создания коллекции за пределами модульных тестов. Я считаю, что синтаксис двойной скобки очень удобочитаем.
другой способ достижения декларативного построения списков-использовать Arrays.asList(T ...) вот так:
List<String> aList = Arrays.asList("vanilla", "strawberry", "chocolate");
ограничение этого подхода, конечно, заключается в том, что вы не можете контролировать конкретный тип списка, который будет создан.
обычно в этом нет ничего особенно неэффективного. Обычно для JVM не имеет значения, что вы сделали подкласс и добавили к нему конструктор-это обычная, повседневная вещь, которую нужно делать на объектно-ориентированном языке. Я могу думать о довольно надуманных случаях, когда вы могли бы вызвать неэффективность, делая это (например, у вас есть неоднократно вызываемый метод, который в конечном итоге принимает смесь разных классов из-за этого подкласса, тогда как обычный класс, переданный в полностью предсказуемый - в последнем случае JIT-компилятор может сделать оптимизацию, которая невозможна в первом). Но на самом деле, я думаю, что случаи, когда это будет иметь значение, очень надуманны.
Я бы увидел проблему больше с точки зрения того, хотите ли вы "загромождать вещи" множеством анонимных классов. В качестве примерного руководства рассмотрите возможность использования идиомы не более, чем, скажем, анонимные классы для обработчиков событий.
In (2), вы находитесь внутри конструктора объект, поэтому "это" относится к объекту, который вы создаете. Это ничем не отличается от любого другого конструктора.
Что касается (3), это действительно зависит от того, кто поддерживает ваш код, я думаю. Если вы не знаете этого заранее, то эталоном, который я бы предложил использовать, является "вы видите это в исходном коде для JDK?"(в этом случае я не помню, чтобы видел много анонимных инициализаторов, и, конечно, не в тех случаях, когда это только содержание анонимного класса). В большинстве проекты среднего размера, я бы сказал, что вам действительно понадобятся ваши программисты, чтобы понять источник JDK в какой-то момент, поэтому любой синтаксис или идиома, используемая там, - "честная игра". Помимо этого, я бы сказал, обучите людей этому синтаксису, если у вас есть контроль над тем, кто поддерживает код, иначе комментируйте или избегайте.
Я исследовал это и решил сделать более глубокий тест, чем тот, который предоставлен действительным ответом.
вот код:https://gist.github.com/4368924
и это мой вывод
Я был удивлен, обнаружив, что в большинстве тестов запуска внутреннее инициирование было на самом деле быстрее (почти вдвое в некоторых случаях). При работе с большими числами преимущество исчезает.
интересно, случай, который создает 3 объекта в цикле, теряет свою выгоду раньше, чем в других случаях. Я не уверен, почему это происходит, и нужно провести больше тестов, чтобы прийти к каким-либо выводам. Создание конкретных реализаций может помочь избежать перезагрузки определения класса (если это то, что происходит)
однако ясно, что не так много накладных расходов он наблюдал в большинстве случаев для одного здания элемента, даже с большими числами.
одна установка назад было бы то, что каждая из инициаций двойной скобки создает новый файл класса, который добавляет целый дисковый блок к размеру нашего приложения (или около 1k при сжатии). Небольшой след, но если он используется во многих местах, он потенциально может оказать влияние. Используйте это 1000 раз, и вы потенциально добавляете весь MiB к вам applicaiton, который может касаться встроенной среды.
мой вывод? Это может быть нормально использовать, пока это не так злоупотребляли.
позвольте мне знать, что вы думаете :)
Я второй ответ Nat, за исключением того, что я бы использовал цикл вместо создания и немедленного выбрасывания неявного списка из asList (elements):
static public Set<T> setOf(T ... elements) {
Set set=new HashSet<T>(elements.size());
for(T elm: elements) { set.add(elm); }
return set;
}
хотя этот синтаксис может быть удобным, он также добавляет много этих ссылок$0, поскольку они становятся вложенными, и может быть трудно выполнить отладку в инициализаторы, если точки останова не установлены на каждом из них. По этой причине я рекомендую использовать это только для банальных сеттеров, особенно для констант, и мест, где анонимные подклассы не имеют значения (например, без сериализации).
Марио Глейхман описание как использовать общие функции Java 1.5 для имитации литералов списка Scala, хотя, к сожалению, вы заканчиваете с неизменяемые списки.
Он определяет этот класс:
package literal;
public class collection {
public static <T> List<T> List(T...elems){
return Arrays.asList( elems );
}
}
и использует его таким образом:
import static literal.collection.List;
import static system.io.*;
public class CollectionDemo {
public void demoList(){
List<String> slist = List( "a", "b", "c" );
List<Integer> iList = List( 1, 2, 3 );
for( String elem : List( "a", "java", "list" ) )
System.out.println( elem );
}
}
Google коллекции, теперь часть гуавы поддерживает аналогичную идею для построения списка. В интервью, Джаред Леви говорит:
[...] этот наиболее часто используемые функции, которые появляются почти в каждом классе Java, который я пишу, - это статические методы, которые уменьшают количество повторяющихся нажатий клавиш в коде Java. Это так удобно иметь возможность вводить команды, такие как:
Map<OneClassWithALongName, AnotherClassWithALongName> = Maps.newHashMap();
List<String> animals = Lists.immutableList("cat", "dog", "horse");
7/10/2014: если бы это было так же просто, как Python:
animals = ['cat', 'dog', 'horse']
инициализация двойной скобки-это ненужный хак, который может привести к утечкам памяти и другим проблемам
нет законных оснований использовать этот "трюк". Гуава обеспечивает хороший immutable коллекции которые включают в себя как статические фабрики, так и строители, что позволяет заполнить вашу коллекцию, где она объявлена в чистом, читаемом и безопасное синтаксис.
примером в вопросе становится:
Set<String> flavors = ImmutableSet.of(
"vanilla", "strawberry", "chocolate", "butter pecan");
не только это короче и легче читать, но это позволяет избежать многочисленных проблем с двойным шаблоном, описанным в другие ответы. Конечно, он выполняет аналогично непосредственно построенному HashMap, но это опасно и чревато ошибками, и есть лучшие варианты.
всякий раз, когда вы обнаружите, что рассматриваете двойную инициализацию, вы должны пересмотреть свой API или ввести новые чтобы правильно решить проблему, а не воспользоваться синтаксическими трюки.
Ошибки теперь флаги этот анти-паттерн.
этой
add()для каждого члена. Если вы можете найти более эффективный способ поместить элементы в хэш-набор, используйте его. Обратите внимание, что внутренний класс, скорее всего, будет генерировать мусор, если вы чувствительны к этому.мне кажется, что контекст-это объект, возвращаемый
new, который являетсяHashSet.Если вам нужно спросить... Более вероятно: будут ли люди, которые придут после вас, знать это или нет? Это легко понять и объяснить? Если вы можете ответить "да" на оба, не стесняйтесь использовать его.