Хотите построить фрейм данных Pandas как несколько гистограмм с осью X масштаба log10
у меня есть данные с плавающей запятой в панды фрейма данных. Каждый столбец представляет переменную (у них есть имена строк), а каждая строка-набор значений (строки имеют целочисленные имена, которые не важны).
>>> print data
0 kppawr23 kppaspyd
1 3.312387 13.266040
2 2.775202 0.100000
3 100.000000 100.000000
4 100.000000 39.437420
5 17.017150 33.019040
...
Я хочу построить гистограмму для каждого столбца. Лучший результат, которого я достиг, - это метод hist dataframe:
data.hist(bins=20)
но я хочу, чтобы ось x каждой гистограммы была в масштабе log10. И бункеры тоже должны быть в масштабе log10, но это легко достаточно с bins=np.logspace (-2,2,20).
обходным путем может быть преобразование данных log10 перед построением графика, но подходы, которые я пробовал,
data.apply(math.log10)
и
data.apply(lambda x: math.log10(x))
дайте мне ошибку с плавающей запятой.
"cannot convert the series to {0}".format(str(converter)))
TypeError: ("cannot convert the series to <type 'float'>", u'occurred at index kppawr23')
1 ответов
вы могли бы использовать
ax.set_xscale('log')
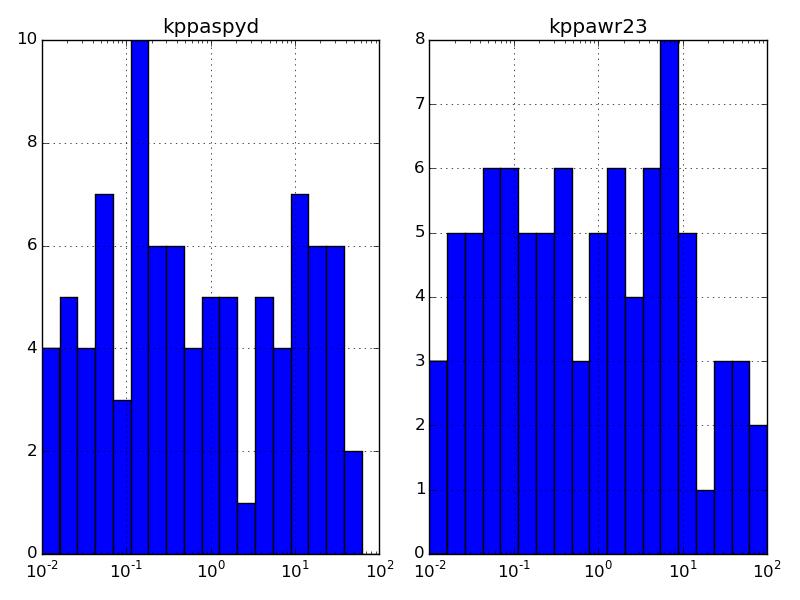
data.hist() возвращает массив осей. Вам нужно позвонить
ax.set_xscale('log') для каждой оси, ax сделать каждый из логарифмически
чешуйчатый.
например,
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
np.random.seed(2015)
N = 100
arr = np.random.random((N,2)) * np.logspace(-2,2,N)[:, np.newaxis]
data = pd.DataFrame(arr, columns=['kppawr23', 'kppaspyd'])
bins = np.logspace(-2,2,20)
axs = data.hist(bins=bins)
for ax in axs.ravel():
ax.set_xscale('log')
plt.gcf().tight_layout()
plt.show()
доходность
кстати, чтобы взять журнал каждого значения в фрейме данных,data, вы могли бы использовать
logdata = np.log10(data)
потому что NumPy ufuncs (например,np.log10) может применяться к pandas DataFrames, потому что они работают поэлементно на все значения в таблице данных.
data.apply(math.log10) не работает, потому что apply пытается передать весь столбец (ряд) значений math.log10. math.log10 ожидает только скалярное значение.
data.apply(lambda x: math.log10(x)) не удается по той же причине, что data.apply(math.log10) делает. Более того, если data.apply(func) и data.apply(lambda x: func(x)) были оба жизнеспособных варианта, первый должен быть предпочтительным, так как лямбда-функция просто сделает вызов tad замедлившийся.
вы могли бы использовать data.apply(np.log10), снова с NumPy ufunc np.log10 может применяться к серии, но нет причин беспокоиться об этом, когда np.log10(data) строительство.
вы также можете использовать data.applymap(math.log10) С applymap вызовы
math.log10 для каждого значения в data один-на-времени. Но это будет намного медленнее
чем вызов эквивалентной функции NumPy,np.log10 на всю
Фрейм данных. Тем не менее, стоит знать о applymap в случае, если вам нужно позвонить
некоторые пользовательские функции который не является ufunc.