Инструмент Diff, который игнорирует новые строки [закрыт]
мне часто нужно сравнивать процедуры SQL, чтобы определить, что изменилось в новейшей версии. Проблема в том, что у каждого есть свой собственный стиль форматирования, и SQL (обычно) не заботится о том, где помещаются их новые строки (например, где все предложения на одной строке против новой строки перед каждым и).
это делает его очень трудным (особенно для длинных процедур) увидеть фактические разницы. Я не могу найти бесплатную утилиту diff/merge, которая позволит мне игнорировать newlines (т. е. рассматривать как пробелы). До сих пор я пробовал WinMerge и вне сравнения без успеха. Кто-нибудь знает инструмент diff (идеально свободный), который видел бы эти два примера как идентичные?
Ex. 1:
the quick
brown
Ex. 2:
the
quick
brown
спасибо заранее.
12 ответов
Что я сделал в моем собственном подобном случае является использование sql prettifier который автоматически организует два набора полуразличных SQL очень похожим образом. затем я вставляю и сравниваю результаты с WinMerge.
это двухэтапный процесс, но он гораздо более удобен, чем многие другие варианты, особенно когда задействовано много строк кода.
ссылка на веб-Sql Pretty printer это прилично.
Мне очень нравится в SourceGear DiffMerge!
Он работает на всех платформах и имеет встроенные правил, но позволяет создавать и добавлять свои собственные. Это означает, что вы можете игнорировать то, что хотите, когда хотите.
бонус, это бесплатно!
сравниваем++ является опцией, вы можете попробовать "игнорировать изменения стиля кода" в меню "smart". Он поддерживает структурированное сравнение для многих языков, таких как C/C++, JavaScript, C#, Java ...
вы можете использовать dtp (проект инструмента данных) Eclipse IDE.
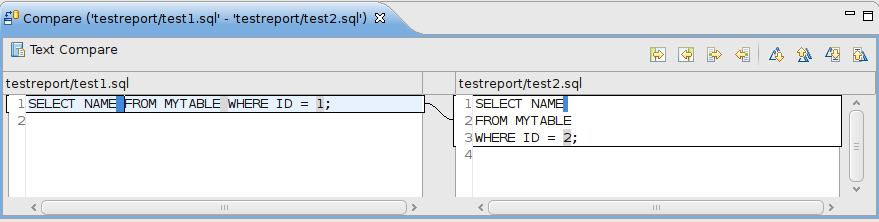
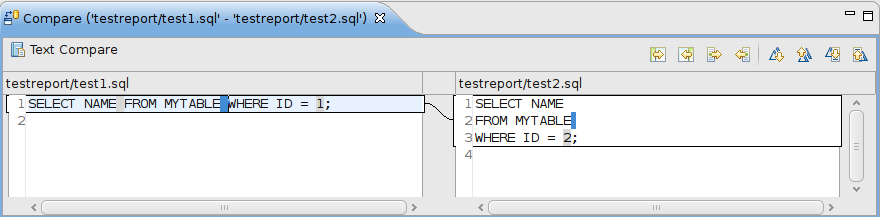
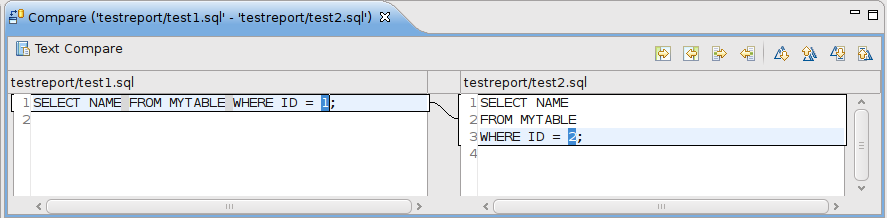
чтобы показать это, я создал два почти одинаковых файла SQL и позволил eclipse показать мне различия. После нажатия кнопки "Показать далее"я сделал скриншот.
Как вы можете видеть, он по-прежнему выделяет новые строки, Но, кстати, вы можете сразу увидеть, что они не содержат существенных изменений в SQL. Легко определить, где я изменил идентификатор с 1 на 2.
здесь результат.
независимо от вашего определения "бесплатно" (пиво против Речи / libre),форматер T-SQL бедняги также доступно для этого, либо с WinMerge (с помощью плагина winmerge), либо вне сравнения и других инструментов сравнения, которые позволяют предварительно форматировать командную строку с помощью массового форматирования командной строки.
Если вы предпочитаете взять его за вихрь, не загружая ничего, он доступен для немедленного использования в интернете (например, его не-libre аналоги T-SQL Tidy, Мгновенный форматер SQL и т. д.):
Я люблю Araxis слияния. Не бесплатно, но оно того стоит. он может, среди прочего, игнорировать любые пробелы, если вы хотите.
Если вы на Windows,WinMerge это довольно ловко. В Linux (и, возможно, OS X) есть объединить.
оба бесплатны и работают довольно хорошо. Не такой крутой, как Араксис, но мы не хотим, чтобы ты пускал слюни на свой стол.
оба являются универсальными инструментами diff с такими функциями, как игнорирование пробела. Я не совсем уверен, что они игнорируют пустые строки, но велики шансы, что они могут.
наши SD Smart Differencer сравнивает две исходные программы в соответствии с их точным грамматическим синтаксисом и структурой, а не в соответствии с необработанным текстом. Он делает это путем синтаксического анализа (SQL) source способ компилятора и сравнение соответствующих структур данных компилятора (например, абстрактных синтаксических деревьев). Следовательно, SmartDifference не заботится о новых строках, пробелах или промежуточных комментариях.
Он сообщает о различиях, а не с точки зрения разрывов строк, но скорее в терминах структур языка программирования (переменных, выражений, операторов, блоков, функций,...) и в терминах, близких к намерениям программиста (удалить, вставить, переместить, скопировать, переименовать), а не line-insert или line delete.
SQL (как и многие другие имена компьютерных языков) - это имя семейства компьютерных языков, которые похожи по синтаксису, но отличаются в деталях. Так что для умных Differencer, , который диалект SQL, вы используете вопросы. У нас есть SQL передние концы (поэтому SmartDifferncers) для PLSQL и SQL2011. Насколько вы в SQL находится в пределах любого из этих, умных Differencer может работать на вас; по мере вы использовать дополнительные вкусности сервера SQL или Postgres, в SmartDifferencer в настоящее время не могу вам помочь. [Мы разрабатываем Парсеры языка как часть нашего бизнеса, поэтому я ожидаю, что это вопрос задержки, а не никогда].
в то время как ОП спросил о SQL в деталях, его главный вопрос-язык агностический. Есть SmartDifferencers уже для многих других широко используемых языков, кроме SQL тоже: C, C++, C#, Java,...
вы пробовали KDiff? Я уверен, что вы можете игнорировать пробелы с ним, и если он недостаточно мощный для вас, он позволяет запускать препроцессор над файлом. Лучше всего это бесплатно и открытым исходным кодом.
команда Phpstorm's diff tool "игнорировать пробел: все" делает это идеально, как вы хотите. И он интегрировал поддержку для много VCS как SVN, git, etc. А также интегрированная поддержка SQL!
не бесплатно, но время тоже не бесплатно. Хотите потратить время на трудный путь? Идти вперед.
Я до сих пор не могу поверить, что это 2014, и это не была стандартная функция всех инструментов diff!!
кстати, я считаю, что инструмент diff WebStorm также будет работать.
вы можете использовать инструмент командной строки wdiff игнорировать переносы строк. wdiff является инструментом GNU для сравнения файлов на основе слово в слово. Он может игнорировать новые строки с помощью .
предположим, я помещу ваши 2 примера файлов в ex1.txt и ex2.формат txt. Тогда мы можем бежать:
$> wdiff -n ex1.txt ex2.txt
the
quick
brown
вывод на самом деле является содержимым первого файла. Обратите внимание, что нет знаков + или -, что означает, что файлы имеют одинаковые строки.
если бы я добавил "лиса" до конца ex1.txt, тогда выход будет выглядеть так:
the
quick
brown [-fox-]
если видим общие слова все еще беспокоит вас, вы можете добавить -3 или --no-common. Вот пример снова, где я добавил " fox " в первый файл:
$> wdiff -n -3 /tmp/ex1.txt /tmp/ex2.txt
======================================================================
[-fox-]
======================================================================