IP-фрагментация и повторная сборка
в настоящее время я просматриваю свои сетевые слайды и задавался вопросом, Может ли кто-нибудь помочь мне с концепцией фрагментации и сборки.
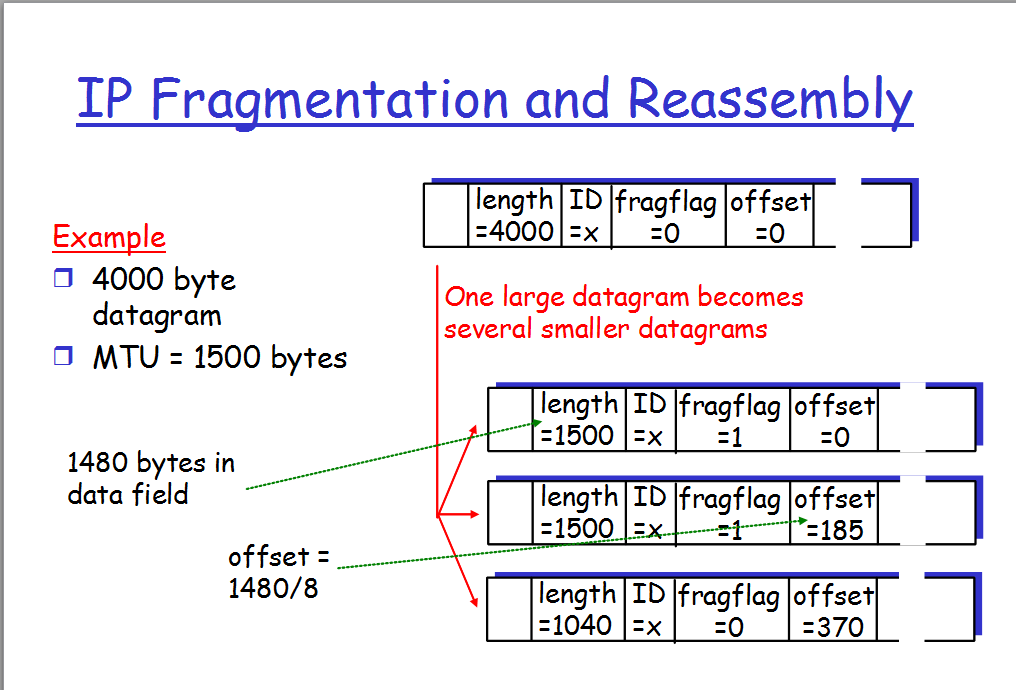
Я понимаю, как это работает, а именно, как дейтаграммы разбиваются на более мелкие куски, потому что сетевые ссылки имеют MTU. Однако пример на картинке сбивает меня с толку.
Итак, первые два раздела показывают длину 1500, потому что это МГУ, но не должно ли это означать, что последний должен иметь 1000 (в общей сложности 4000 байт), а не 1040? Откуда взялись эти дополнительные 40 байт? Я предполагаю, что, поскольку предыдущие два фрагмента имели заголовок 20 байт, эти дополнительные 40 байтов данных должны были куда-то идти, поэтому он прибудет в последний фрагмент?
Fragflag по существу означает, что есть еще один фрагмент, поэтому все они будут иметь Фрагфлаг 1, за исключением последнего фрагмента, который будет равен нулю. Однако я не понимаю, что такое offset или как это рассчитанный. Почему первое смещение равно нулю? Почему мы разделили байты в поле данных (1480) на 8, чтобы получить второе смещение? Откуда эта 8 взялось? Кроме того, я предполагаю, что каждое смещение фрагментов будет просто увеличиваться на это значение?
например, первый фрагмент будет иметь смещение 0, второй 185, третий 370 и четвертый 555? (370+185)
Спасибо за любую помощь!
4 ответов
в каждом пакете есть 20-байтовый заголовок. Таким образом, исходный пакет содержит 3,980 байт данных. Фрагменты содержат 1480, 1480, и 1020 байт данных. 1480 + 1480 + 1020 = 3980
каждый бит в заголовке дорого. Деление смещения на 8 позволяет ему вписываться в 13 бит вместо 16. Это означает, что каждый пакет, кроме последнего, должен содержать несколько байтов данных, кратных 8, что не является проблемой.
фрагментация и сборка были исключительно объяснены в RFC 791. Пройдите через спецификация интернет-протокола RFC. RFC имеет различные разделы, объясняющие фрагментацию и сборку образца. Все ваши сомнения и вопросы принимаются в нем.
Ans 1: Что касается длины пакета: исходный пакет содержит 4000 байт. Этот пакет является полностью IP-пакетом и, следовательно, содержит IP-заголовок. Таким образом, длина полезной нагрузки на самом деле 4000 - (длина заголовка IP i. e. 20 ).
Фактическая Длина Полезной Нагрузки = 4000 - 20 = 3980
теперь пакет фрагментирован из-за того, что длина больше MTU ( 1500 байт).
таким образом, 1-й пакет содержит 1500 байт, который включает IP-заголовок + часть полезной нагрузки.
1500 = 20 (IP-заголовок) + 1480 (полезная нагрузка данных )
аналогично для другого пакета.
третий пакет должен содержать оставшиеся данные ( 3980 - 1480 -1480 ) = 1020
таким образом, длина пакета составляет 20 (IP-заголовок) + 1020 ( полезная нагрузка) = 1040
Ans 2: смещение-это адрес или локатор, откуда данные начинаются со ссылки на исходную полезную нагрузку данных. Для IP полезная нагрузка данных содержит все данные, которые находятся после заголовка IP и заголовка опций. Таким образом, система / маршрутизатор принимает полезную нагрузку и делит ее на меньшие части и отслеживает смещение со ссылкой к исходному пакету, чтобы можно было выполнить сборку.
Как указано в RFC Страница 12.
"поле смещения фрагмента сообщает получателю положение фрагмента в исходной датаграмме. Смещение и длина фрагмента определяют часть исходной датаграммы покрытый этим фрагментом. Флаг more-fragments указывает (путем сброса) последний фрагмент. Эти поля предоставляют достаточную информацию для повторной сборки датаграмм. "
смещение фрагмента измеряется в единицах по 8 байт каждый. Он имеет 13-битное поле в заголовке IP. Как сказано в RFC Страница 17
"это поле указывает, где в дейтаграмме находится этот фрагмент.Смещение фрагмента измеряется в единицах 8 октетов (64 бита). Первый фрагмент имеет смещение нуль."
таким образом, как вы спросили в вопросе, откуда взялся этот 8, его стандарт, который был определен для спецификации протокола IP, где 8 октеты берутся как одно значение. Это также помогает нам передавать большие пакеты через этот.
страница 28 RFC пишет: * Фрагменты подсчитываются в единицах 8 октетов. Стратегия фрагментации разработана таким образом, что нефрагментированная дейтаграмма имеет всю нулевую информацию о фрагментации (MF = 0, fragment offset = 0). Если дейтаграмма интернета фрагментирована, ее часть данных должна быть разбит на 8 октетных границах. Этот формат позволяет 2 * * 13 = 8192 фрагментов по 8 октетов каждый для всего 65,536 октеты. Заметим, что это согласуется с поле общая длина дейтаграммы (конечно, заголовок подсчитывается в поле общая длина и не во фрагментах).*
размер смещения составляет 13 бит в IP-заголовке, но нам нужно 16 бит, а в худшем случае. Поэтому мы используем коэффициент масштабирования 8, т. е. (2^16/2^13).
Это не дополнительные биты, а общая длина последнего фрагмента. поскольку 1500-MTU, это означает, что в одном фрагменте может быть 1500 байт данных, включая заголовок. Заголовок добавляется к каждому фрагменту. это означает, что во фрагменте мы способны отправлять 1500-20 =1480 байт данных. дана датаграмма 4000B .датаграмма ничего, кроме инкапсуляции пакетов данных на сетевом уровне.поэтому итоговые данные мы должны отправить 4000-20=3980 . затем он фрагментируется на 3 части (ceil (3980/1480)) каждый из длины 1480,1480,1020 соответственно . следовательно, когда заголовок 20B добавляется к последнему фрагменту, его длина становится 1020+20=1040 .