Использование сводной таблицы с итогами столбцов и строк в sql server 2008
у меня есть таблица со следующими столбцами
defect_id, developer_name, status, summary, root_cause,
Secondary_RC, description, Comments, environment_name
столбец root_cause имеет Enviro, Requi, Dev, TSc, TD, Unkn как свои значения и
имя_окружения колонны и QA1, QA2, QA3
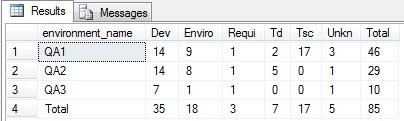
мне нужно подготовить отчет в следующем формате
Enviro Requi Dev TSc TD Unkn Total
QA1 9 1 14 17 2 3 46
QA2 8 1 14 0 5 1 29
QA3 1 1 7 0 0 1 10
Total 18 3 35 17 7 5 85
Я должен подготовить доклад до
Enviro Requi Dev TSc TD Unkn
QA1 9 1 14 17 2 3
QA2 8 1 14 0 5 1
QA3 1 1 7 0 0 1
я использовал приведенный ниже запрос, чтобы получить выше результат
select *
from
(
select environment_name as " ", value
from test1
unpivot
(
value
for col in (root_cause)
) unp
) src
pivot
(
count(value)
for value in ([Enviro] , [Requi] , [Dev] , [Tsc], [TD] , [Unkn])
) piv
может ли кто-нибудь помочь получить итоги для столбцов и строк?
3 ответов
к этому могут быть различные подходы. Вы можете рассчитать все итоги после поворота, или вы можете сначала получить итоги,а затем повернуть все результаты. Также возможно иметь своего рода середину: получить один вид итогов (например, по строкам), pivot, а затем получить другой вид, хотя это может быть переусердствованием.
первый из упомянутых подходов, получение всех итогов после поворота, может быть сделано очень простым способом, и единственное, что потенциально новым для вас в приведенной ниже реализации может быть GROUP BY ROLLUP():
SELECT
[ ] = ISNULL(environment_name, 'Total'),
[Enviro] = SUM([Enviro]),
[Requi] = SUM([Requi]),
[Dev] = SUM([Dev]),
[Tsc] = SUM([Tsc]),
[TD] = SUM([TD]),
[Unkn] = SUM([Unkn]),
Total = SUM([Enviro] + [Requi] + [Dev] + [Tsc] + [TD] + [Unkn])
FROM (
SELECT environment_name, root_cause
FROM test1
) s
PIVOT (
COUNT(root_cause)
FOR root_cause IN ([Enviro], [Requi], [Dev], [Tsc], [TD], [Unkn])
) p
GROUP BY
ROLLUP(environment_name)
;
в основном GROUP BY ROLLUP() часть производит в общей сумме строка для вас. Группировка сначала выполняется с помощью environment_name, затем добавляется общая строка.
чтобы сделать прямо противоположное, т. е. получить итоги до поворота, вы можете использовать GROUP BY CUBE() такой:
SELECT
[ ] = environment_name,
[Enviro] = ISNULL([Enviro], 0),
[Requi] = ISNULL([Requi] , 0),
[Dev] = ISNULL([Dev] , 0),
[Tsc] = ISNULL([Tsc] , 0),
[TD] = ISNULL([TD] , 0),
[Unkn] = ISNULL([Unkn] , 0),
Total = ISNULL(Total , 0)
FROM (
SELECT
environment_name = ISNULL(environment_name, 'Total'),
root_cause = ISNULL(root_cause, 'Total'),
cnt = COUNT(*)
FROM test1
WHERE root_cause IS NOT NULL
GROUP BY
CUBE(environment_name, root_cause)
) s
PIVOT (
SUM(cnt)
FOR root_cause IN ([Enviro], [Requi], [Dev], [Tsc], [TD], [Unkn], Total)
) p
;
оба метода могут быть протестированы и воспроизведены в SQL Скрипка:
Примечание. Я опустил шаг unpivoting в обоих предложениях, потому что unpivoting одного столбца казался явно избыточным. Однако, если есть еще что-то, настройка любого из запросов должна быть легкой.
вы можете найти всего за root_cause и environment_name используя ROLLUP.
-
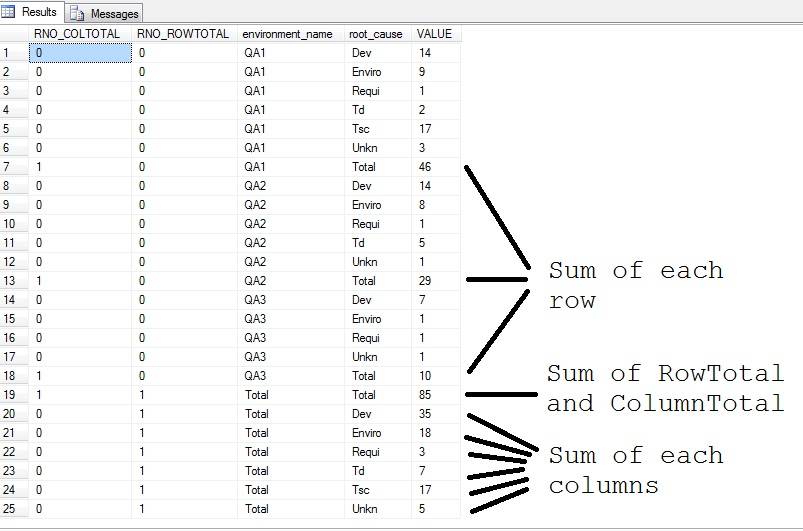
RNO_COLTOTAL- логика разместитьTotalв последнем столбце, так как столбцыTsc,Unknбудет перекрывать колонкиTotalпри повороте, так как его порядок в алфавитном порядке. -
RNO_ROWTOTAL- логика разместитьTotalв последней строке с значение, начиная сU,W,X,Y,Zможет перекрывать значениеTotal, С момента его заказа по алфавиту. -
SUM(VALUE)- можно определить, какую агрегатную функцию мы можем использовать сROLLUP.
запрос 1
SELECT CASE WHEN root_cause IS NULL THEN 1 ELSE 0 END RNO_COLTOTAL,
CASE WHEN environment_name IS NULL THEN 1 ELSE 0 END RNO_ROWTOTAL,
ISNULL(environment_name,'Total')environment_name,
ISNULL(root_cause,'Total')root_cause,
SUM(VALUE) VALUE
INTO #NEWTABLE
FROM
(
-- Find the count for environment_name,root_cause
SELECT DISTINCT *,COUNT(*) OVER(PARTITION BY environment_name,root_cause)VALUE
FROM #TEMP
)TAB
GROUP BY root_cause,environment_name
WITH CUBE
мы получим следующую логику, когда CUBE используется
мы объявляем переменные для поворота.
-
@cols- значения столбцов для поворота. -
@NulltoZeroCols- заменить значения null на нуль.
запрос 2
DECLARE @cols NVARCHAR (MAX)
SELECT @cols = COALESCE (@cols + ',[' + root_cause + ']',
'[' + root_cause + ']')
FROM (SELECT DISTINCT RNO_COLTOTAL,root_cause FROM #NEWTABLE) PV
ORDER BY RNO_COLTOTAL,root_cause
DECLARE @NulltoZeroCols NVARCHAR (MAX)
SET @NullToZeroCols = SUBSTRING((SELECT ',ISNULL(['+root_cause+'],0) AS ['+root_cause+']'
FROM(SELECT DISTINCT RNO_COLTOTAL,root_cause FROM #NEWTABLE GROUP BY RNO_COLTOTAL,root_cause)TAB
ORDER BY RNO_COLTOTAL FOR XML PATH('')),2,8000)
Теперь поверните его динамически
DECLARE @query NVARCHAR(MAX)
SET @query = 'SELECT environment_name,'+ @NulltoZeroCols +' FROM
(
SELECT RNO_ROWTOTAL,environment_name,root_cause,VALUE
FROM #NEWTABLE
) x
PIVOT
(
MIN(VALUE)
FOR [root_cause] IN (' + @cols + ')
) p
ORDER BY RNO_ROWTOTAL,environment_name;'
EXEC SP_EXECUTESQL @query
результат
Я думаю, вам нужно рассчитать общую сумму отдельно. Используя этот простой запрос для total (извините, пришлось дать псевдоним для вашего столбца""):
select environment_name as en,
count (*) AS Total
FROM test1
WHERE value in ('Enviro', 'Requi', 'Dev', 'Tsc', 'TD', 'Unkn')
GROUP BY environment_name
вы можете легко объединить оба запроса вместе, чтобы получить нужный отчет:
SELECT * FROM
(select *
from
(
select environment_name as en, value
from test1
unpivot
(
value
for col in (root_cause)
) unp
) src
pivot
(
count(value)
for value in ([Enviro] , [Requi] , [Dev] , [Tsc], [TD] , [Unkn])
) piv
) AS a
INNER JOIN
( select environment_name as en,
count (*) AS Total
FROM test1
WHERE value in ('Enviro', 'Requi', 'Dev', 'Tsc', 'TD', 'Unkn')
GROUP BY environment_name
) AS b ON a.en = b.en
UNION ALL
SELECT * FROM
(select *
from
(
select 'Total' as en, value
from test1
unpivot
(
value
for col in (root_cause)
) unp
) src
pivot
(
count(value)
for value in ([Enviro] , [Requi] , [Dev] , [Tsc], [TD] , [Unkn])
) piv
) AS a
INNER JOIN
( select 'Total' as en,
count (*) AS Total
FROM test1
WHERE value in ('Enviro', 'Requi', 'Dev', 'Tsc', 'TD', 'Unkn')
) AS b
Я не тестировал его, но считаю, что он будет работать