Исправление особенно неясной утечки пространства Haskell
Итак, выжав последний бит производительности из некоторого Haskell, который я использую, чтобы разбить данные твита на n-граммы, я столкнулся с проблемой утечки пространства. Когда я профилирую, GC использует около 60-70% процесса, и есть значительные части памяти, предназначенные для перетаскивания. Надеюсь, какой-нибудь гуру Хаскелла сможет подсказать, когда я ошибаюсь.
{-# LANGUAGE OverloadedStrings, BangPatterns #-}
import Data.Maybe
import qualified Data.ByteString.Char8 as B
import qualified Data.HashMap.Strict as H
import Text.Regex.Posix
import Data.List
import qualified Data.Char as C
isClassChar a = C.isAlphaNum a || a == ' ' || a == ''' ||
a == '-' || a == '#' || a == '@' || a == '%'
cullWord :: B.ByteString -> B.ByteString
cullWord w = B.map C.toLower $ B.filter isClassChar w
procTextN :: Int -> B.ByteString -> [([B.ByteString],Int)]
procTextN n t = H.toList $ foldl' ngram H.empty lines
where !lines = B.lines $ cullWord t
ngram tr line = snd $ foldl' breakdown (base,tr) (B.split ' ' line)
base = replicate (n-1) ""
breakdown :: ([B.ByteString], H.HashMap [B.ByteString] Int) -> B.ByteString -> ([B.ByteString],H.HashMap [B.ByteString] Int)
breakdown (st@(s:ss),tree) word =
newStack `seq` expandedWord `seq` (newStack,expandedWord)
where newStack = ss ++ [word]
expandedWord = updateWord (st ++ [word]) tree
updateWord :: [B.ByteString] -> H.HashMap [B.ByteString] Int -> H.HashMap [B.ByteString] Int
updateWord w h = H.insertWith (+) w 1 h
main = do
test2 <- B.readFile "canewobble"
print $ filter ((a,b) -> b > 100) $
sortBy ((a,b) (c,d) -> compare d b) $ procTextN 3 test2
1 ответов
одна небольшая оптимизация заключается в фильтрации данных (используя HashMap.filter) до сортировки. Это помогло мне сбрить 2s от окончательного времени исполнения. Еще одна вещь, которую я сделал, - это использовать последовательности (Data.Sequence) вместо списков (без заметной разницы: - (). Моя версия может быть найдена здесь.
глядя на профиль кучи, я не думаю, что в вашей программе есть утечка пространства:
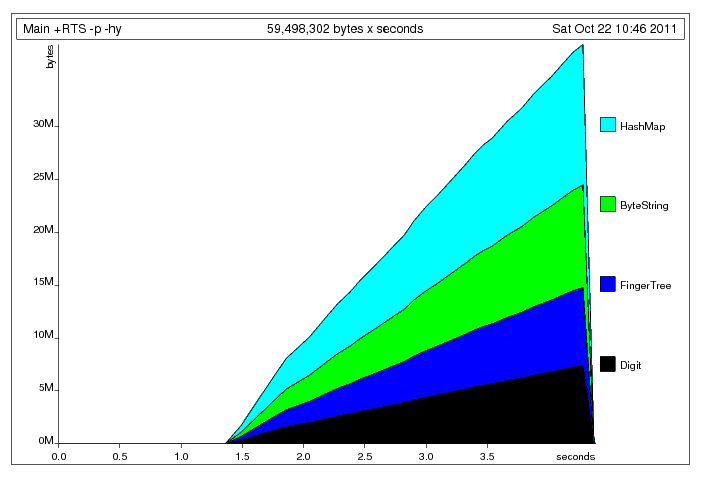
вы просто создаете довольно большую хэш-таблицу (377141 пары ключ-значение) в памяти, а затем отбросить его после некоторой обработки. Согласно почта Йохана хэш-таблица такого размера занимает прибл. 5*N + 4*(N-1) слова = 3394265 * 4 байта ~= 13 MiB, что согласуется с тем, что показывает профиль кучи. Остальное пространство занимают ключи и значения. На моей машине время, проведенное в GC, составляет около 40%, что не звучит необоснованно, учитывая, что вы постоянно обновляете хэш-таблицу и временные "стеки", не делая ничего вычислительного данные. Поскольку единственная операция, для которой вам нужна хэш-таблица, - это insertWith, возможно, лучше использовать изменяемая структура данных?
обновление: я переписал вашу программу, используя изменяемую хэш-таблицу. интересно, что разница в скорости невелика, но использование памяти немного лучше:
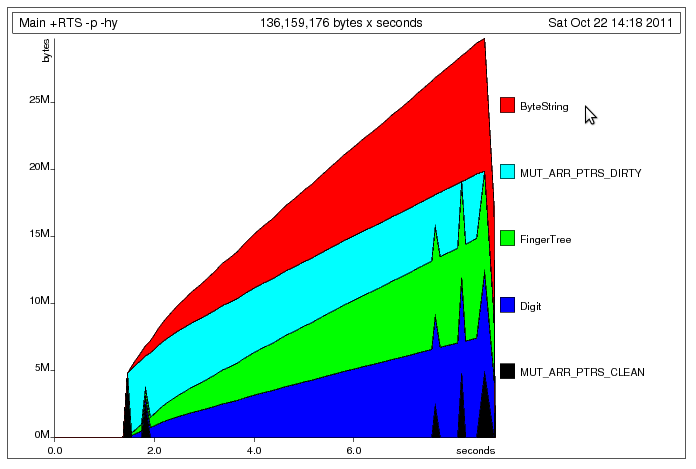
как вы можете видеть, размер блока, выделенного для хэш-таблицы, остается постоянным на протяжении исполнение.