Java: случайное целое число с неравномерным распределением
как я могу создать случайное целое число n в Java, между 1 и k с "линейным нисходящим распределением", т. е. 1 скорее всего, 2 менее вероятно, 3 менее вероятно, ..., k наименее вероятно, и вероятности нисходят линейно, вот так:
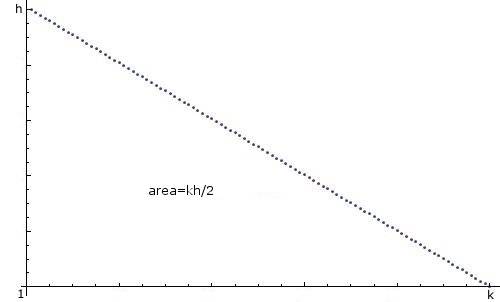
Я знаю, что уже есть dosens потоков по этой теме, и я извиняюсь за создание нового, но я не могу, похоже, быть в состоянии создать то, что мне нужно от их. Я знаю, что использование import java.util.*; код
Random r=new Random();
int n=r.nextInt(k)+1;
создает случайное целое число между 1 и k, распределены равномерно.
обобщение: любые подсказки для создания произвольно распределенного целого числа, т. е. f(n)=some function, P(n)=f(n)/(f(1)+...+f(k))), также было бы оценено, например:
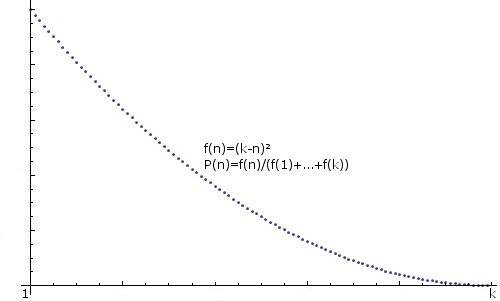 .
.
10 ответов
Это должно дать вам то, что вам нужно:
public static int getLinnearRandomNumber(int maxSize){
//Get a linearly multiplied random number
int randomMultiplier = maxSize * (maxSize + 1) / 2;
Random r=new Random();
int randomInt = r.nextInt(randomMultiplier);
//Linearly iterate through the possible values to find the correct one
int linearRandomNumber = 0;
for(int i=maxSize; randomInt >= 0; i--){
randomInt -= i;
linearRandomNumber++;
}
return linearRandomNumber;
}
кроме того, вот общее решение для положительных функций (отрицательные функции действительно не имеют смысла) в диапазоне от начального индекса до stopIndex:
public static int getYourPositiveFunctionRandomNumber(int startIndex, int stopIndex) {
//Generate a random number whose value ranges from 0.0 to the sum of the values of yourFunction for all the possible integer return values from startIndex to stopIndex.
double randomMultiplier = 0;
for (int i = startIndex; i <= stopIndex; i++) {
randomMultiplier += yourFunction(i);//yourFunction(startIndex) + yourFunction(startIndex + 1) + .. yourFunction(stopIndex -1) + yourFunction(stopIndex)
}
Random r = new Random();
double randomDouble = r.nextDouble() * randomMultiplier;
//For each possible integer return value, subtract yourFunction value for that possible return value till you get below 0. Once you get below 0, return the current value.
int yourFunctionRandomNumber = startIndex;
randomDouble = randomDouble - yourFunction(yourFunctionRandomNumber);
while (randomDouble >= 0) {
yourFunctionRandomNumber++;
randomDouble = randomDouble - yourFunction(yourFunctionRandomNumber);
}
return yourFunctionRandomNumber;
}
Примечание: для функций, которые могут возвращать отрицательные значения, один из методов может заключаться в том, чтобы взять абсолютное значение этой функции и применить его к вышеуказанному решению для каждого вызова yourFunction.
поэтому нам нужно следующее распределение, от наименее вероятного до наиболее вероятного:
*
**
***
****
*****
etc.
давайте попробуем сопоставить равномерно распределенную целочисленную случайную величину с этим распределением:
1
2 3
4 5 6
7 8 9 10
11 12 13 14 15
etc.
таким образом, если мы генерируем равномерно распределенное случайное число от 1 до, скажем, 15 в этом случае для K = 5, нам просто нужно выяснить, какое ведро ему подходит. Самое сложное-как это сделать.
Примечание. что числа справа-это треугольные числа! Это означает, что для случайно сгенерированных X С 1 to T_n, нам просто нужно найти N такое, что T_(n-1) < X <= T_n. К счастью, есть хорошо определенная формула, чтобы найти "треугольный корень" данного числа, который мы можем использовать в качестве ядра нашего отображения от равномерного распределения до ведра:
// Assume k is given, via parameter or otherwise
int k;
// Assume also that r has already been initialized as a valid Random instance
Random r = new Random();
// First, generate a number from 1 to T_k
int triangularK = k * (k + 1) / 2;
int x = r.nextInt(triangularK) + 1;
// Next, figure out which bucket x fits into, bounded by
// triangular numbers by taking the triangular root
// We're dealing strictly with positive integers, so we can
// safely ignore the - part of the +/- in the triangular root equation
double triangularRoot = (Math.sqrt(8 * x + 1) - 1) / 2;
int bucket = (int) Math.ceil(triangularRoot);
// Buckets start at 1 as the least likely; we want k to be the least likely
int n = k - bucket + 1;
n теперь должен иметь указанное распределение.
есть много способов сделать это, но, вероятно, самый простой-просто создать
два случайные целые числа, один между 0 и k, назовем его x, между 0 и h, назовем его y. Если y > mx + b (m и b выбрал правильно...) тогда
k-x, else x.
редактировать: отвечая на комментарии здесь, чтобы у меня было немного больше места.
в основном мое решение использует симметрию в ваш оригинальный дистрибутив, где p(x) является линейной функцией x. Я ответил перед вашим редактированием об обобщении, и это решение не работает в общем случае (потому что в общем случае такой симметрии нет).
я представил себе проблему так:
- вы два правый треугольник, каждый
k x h, С общей гипотенузой. Составная форма являетсяk x hпрямоугольник. - генерация случайной точки что выпадает на каждую точку внутри прямоугольника с равной вероятностью.
- половину времени он будет падать в одном треугольнике, половину времени в другом.
- предположим, что точка падает в нижний треугольник.
- треугольник в основном описывает P. M. F., а "высота" треугольника над каждым X-значением описывает вероятность того, что точка будет иметь такое x-значение. (Помните, что мы имеем дело только с точками в нижнем треугольнике.) Так по выходу х-значение.
- предположим, что точка падает в верхнем треугольнике.
- инвертировать координаты и обрабатывать его, как указано выше, с помощью нижнего треугольника.
Вам также придется позаботиться о крайних случаях (я не беспокоился). Например. Теперь я вижу, что ваш дистрибутив начинается с 1, а не 0, поэтому там есть off-by-one, но это легко исправить.
позвольте мне попробовать еще один ответ, вдохновленный rlibby. Это конкретное распределение также является распределением меньше из двух значений выбирается равномерно и случайным образом из того же диапазона.
нет необходимости моделировать это с помощью массивов и т. д., Если ваше распределение таково, что вы можете вычислить его кумулятивную функцию распределения (cdf). Выше у вас есть функция распределения вероятности (pdf). h фактически определяется, так как площадь под кривой должна быть 1. Для простоты математики позвольте мне также предположить,что вы выбираете число в [0, k).
pdf здесь f (x) = (2/k) * (1 - x/k), если я правильно вас понял. Cdf является неотъемлемой частью pdf. Вот, это F(x) = (2/k) * (x - x^2 / 2k). (Вы можете повторить эту логику для любой функции pdf, если она интегрируема.)
тогда вам нужно вычислить обратную функцию cdf, F^-1 (x), и если бы я не был ленивым, я бы сделал это за вас.
но хорошая новость заключается в следующем: как только у вас есть F^-1(x), все, что вы делаете, это применяете его к распределению случайных значений равномерно в [0,1] и применяете к нему функцию. Ява.утиль.Random Может обеспечить это с некоторой осторожностью. Это ваше случайно выбранное значение из вашего распределение.
это называется треугольным распределением, хотя ваш вырожденный случай с режимом, равным минимальному значению. Википедия имеет уравнения для создания одной заданной равномерно распределенной (0,1) переменной.
первое решение, которое приходит на ум,-использовать блокируемый массив. Каждый индекс будет указывать диапазон значений в зависимости от того, насколько" вероятным " вы хотите его видеть. В этом случае вы будете использовать более широкий диапазон для 1, менее широкий для 2 и так далее, пока не достигнете небольшого значения (скажем, 1) для k.
int [] indexBound = new int[k];
int prevBound =0;
for(int i=0;i<k;i++){
indexBound[i] = prevBound+prob(i);
prevBound=indexBound[i];
}
int r = new Random().nextInt(prevBound);
for(int i=0;i<k;i++){
if(r > indexBound[i];
return i;
}
теперь проблема заключается в поиске случайного числа, а затем сопоставлении этого числа с его ведром. вы можете сделать это для любого распределения при условии, что вы можете дискретизировать ширину каждого интервал. Дайте мне знать, если я что-то упускаю при объяснении алгоритма или его правильности. Излишне говорить, что это необходимо оптимизировать.
что-то вроде этого....
class DiscreteDistribution
{
// cumulative distribution
final private double[] cdf;
final private int k;
public DiscreteDistribution(Function<Integer, Double> pdf, int k)
{
this.k = k;
this.cdf = new double[k];
double S = 0;
for (int i = 0; i < k; ++i)
{
double p = pdf.apply(i+1);
S += p;
this.cdf[i] = S;
}
for (int i = 0; i < k; ++i)
{
this.cdf[i] /= S;
}
}
/**
* transform a cumulative distribution between 0 (inclusive) and 1 (exclusive)
* to an integer between 1 and k.
*/
public int transform(double q)
{
// exercise for the reader:
// binary search on cdf for the lowest index i where q < cdf[i]
// return this number + 1 (to get into a 1-based index.
// If q >= 1, return k.
}
}
кумулятивная функция распределения x^2 для треугольного распределения [0,1] с режимом (наибольшая взвешенная вероятность) 1, как показано здесь.
поэтому, все, что нам нужно сделать, чтобы преобразовать равномерное распределение (например, в Java Random::nextDouble) в удобное треугольное распределение, взвешенное в направлении 1: Просто возьмите квадратный корень Math.sqrt(rand.nextDouble()), который затем можно умножить на любой желаемый диапазон.
для примера:
int a = 1; // lower bound, inclusive
int b = k; // upper bound, exclusive
double weightedRand = Math.sqrt(rand.nextDouble()); // use triangular distribution
weightedRand = 1.0 - weightedRand; // invert the distribution (greater density at bottom)
int result = (int) Math.floor((b-a) * weightedRand);
result += a; // offset by lower bound
if(result >= b) result = a; // handle the edge case
самое простое, что нужно сделать, чтобы создать список или массив всех возможных значений в их весах.
int k = /* possible values */
int[] results = new int[k*(k+1)/2];
for(int i=1,r=0;i<=k;i++)
for(int j=0;j<=k-i;j++)
results[r++] = i;
// k=4 => { 1,1,1,1,2,2,2,3,3,4 }
// to get a value with a given distribution.
int n = results[random.nextInt(results.length)];
это лучше всего работает для относительно небольших значений k.т. е. k
для больших чисел вы можете использовать подход ведра
int k =
int[] buckets = new int[k+1];
for(int i=1;i<k;i++)
buckets[i] = buckets[i-1] + k - i + 1;
int r = random.nextInt(buckets[buckets.length-1]);
int n = Arrays.binarySearch(buckets, r);
n = n < 0 ? -n : n + 1;
стоимость двоичного поиска довольно мала, но не так эффективна, как прямой поиск (для небольшого массива)
для arbitary distrubution вы можете использовать double[] для cumlative дистрибутив и использовать бинарный поиск, чтобы найти значение.