JPA EntityManager: зачем использовать persist () над merge ()?
EntityManager.merge() можно вставлять новые объекты и обновлять существующие.
почему нужно использовать persist() (который может создавать только новые объекты)?
15 ответов
в любом случае добавит сущность в PersistenceContext, разница заключается в том, что вы делаете с сущностью после этого.
Persist принимает экземпляр сущности, добавляет его в контекст и делает этот экземпляр управляемым (т. е. будущие обновления сущности будут отслеживаться).
Merge создает новый экземпляр вашей сущности, копирует состояние из предоставленной сущности и делает новую копию управляемой. Экземпляр передать не удалось (любые изменения не будет будьте частью транзакции-если вы снова не вызовете merge).
возможно, пример кода поможет.
MyEntity e = new MyEntity();
// scenario 1
// tran starts
em.persist(e);
e.setSomeField(someValue);
// tran ends, and the row for someField is updated in the database
// scenario 2
// tran starts
e = new MyEntity();
em.merge(e);
e.setSomeField(anotherValue);
// tran ends but the row for someField is not updated in the database
// (you made the changes *after* merging)
// scenario 3
// tran starts
e = new MyEntity();
MyEntity e2 = em.merge(e);
e2.setSomeField(anotherValue);
// tran ends and the row for someField is updated
// (the changes were made to e2, not e)
Сценарий 1 и 3 примерно эквивалентны, но есть некоторые ситуации, когда вы хотите использовать сценарий 2.
Persist и merge предназначены для двух разных целей (они вообще не являются альтернативами).
(отредактировано для расширения информации о различиях)
сохраняются:
- вставьте новый регистр в базу данных
- прикрепите объект к диспетчеру сущностей.
слияние:
- найдите прикрепленный объект с тем же идентификатором и обновите его.
- если существует обновление и возврат уже прикрепленного объект.
- если не существует, вставьте новый регистр в базу данных.
эффективность persist ():
- это может быть более эффективным для вставки нового регистра в базу данных, чем merge().
- он не дублирует исходный объект.
persist () семантика:
- он гарантирует, что вы вставляете, а не обновляете ошибка.
пример:
{
AnyEntity newEntity;
AnyEntity nonAttachedEntity;
AnyEntity attachedEntity;
// Create a new entity and persist it
newEntity = new AnyEntity();
em.persist(newEntity);
// Save 1 to the database at next flush
newEntity.setValue(1);
// Create a new entity with the same Id than the persisted one.
AnyEntity nonAttachedEntity = new AnyEntity();
nonAttachedEntity.setId(newEntity.getId());
// Save 2 to the database at next flush instead of 1!!!
nonAttachedEntity.setValue(2);
attachedEntity = em.merge(nonAttachedEntity);
// This condition returns true
// merge has found the already attached object (newEntity) and returns it.
if(attachedEntity==newEntity) {
System.out.print("They are the same object!");
}
// Set 3 to value
attachedEntity.setValue(3);
// Really, now both are the same object. Prints 3
System.out.println(newEntity.getValue());
// Modify the un attached object has no effect to the entity manager
// nor to the other objects
nonAttachedEntity.setValue(42);
}
таким образом, существует только 1 прикрепленный объект для любого регистра в диспетчере сущностей.
merge () для сущности с идентификатором-это что-то вроде:
AnyEntity myMerge(AnyEntity entityToSave) {
AnyEntity attached = em.find(AnyEntity.class, entityToSave.getId());
if(attached==null) {
attached = new AnyEntity();
em.persist(attached);
}
BeanUtils.copyProperties(attached, entityToSave);
return attached;
}
хотя при подключении к MySQL merge () может быть столь же эффективным, как persist (), используя вызов для вставки с опцией обновления дубликатов ключей, JPA-очень высокоуровневое программирование, и вы не можете предположить, что это будет иметь место везде.
если вы используете назначенный генератор,использование merge вместо persist может вызвать избыточную инструкцию SQL, что влияет на производительность.
и вызов слияния для управляемых сущностей также является ошибкой, так как управляемые объекты автоматически управляются Hibernate и их состояние синхронизируется с записью базы данных грязный механизм проверки на промывка контекста сохранения.
чтобы понять, как все это работает, вы должны сначала знать, что Hibernate сдвигает мышление разработчика с операторов SQL на сущность состояния.
после того, как объект активно управляется Hibernate, все изменения будут автоматически распространяться на базу данных.
мониторы Hibernate в настоящее время подключены к объектам. Но чтобы объект стал управляемым, он должен находиться в правильном состоянии объекта.
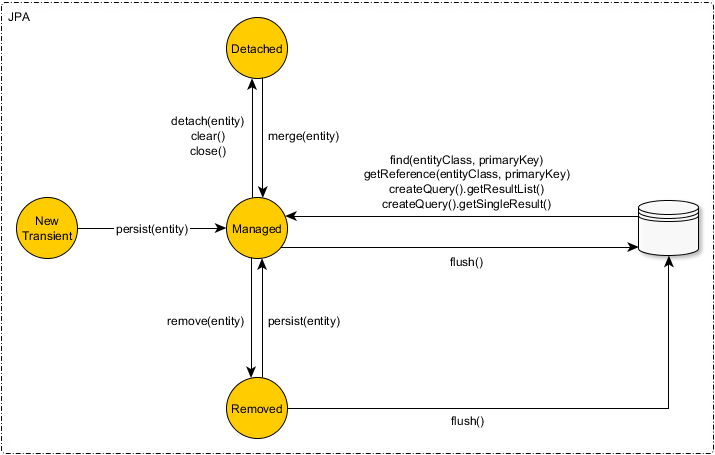
во-первых, мы должны определите все состояния сущности:
-
Новый (Транзиторная)
недавно созданный объект, который никогда не был связан с Hibernate
Session(a.к. аPersistence Context) и не сопоставляется ни с одной строкой таблицы базы данных, считается, что она находится в новом (переходном) состоянии.чтобы стать упорными, нам нужно либо явно вызвать
EntityManager#persistметод или использовать транзитивный механизм персистентности. -
постоянные (Удалось)
постоянный объект был связан со строкой таблицы базы данных, и он управляется текущим запущенным контекстом персистентности. Любое изменение, внесенное в такой объект, будет обнаружено и распространено в базу данных (во время сеанса flush-time). С Hibernate нам больше не нужно выполнять инструкции INSERT/UPDATE/DELETE. Hibernate использует транзакционная запись стиль работы и изменения синхронизированы на самом последнем ответственном момент, во время текущего
Sessionфлеш-времени. -
отдельно стоящее
после закрытия текущего контекста персистентности все ранее управляемые сущности отсоединяются. Последовательные изменения больше не будут отслеживаться, и автоматическая синхронизация базы данных не произойдет.
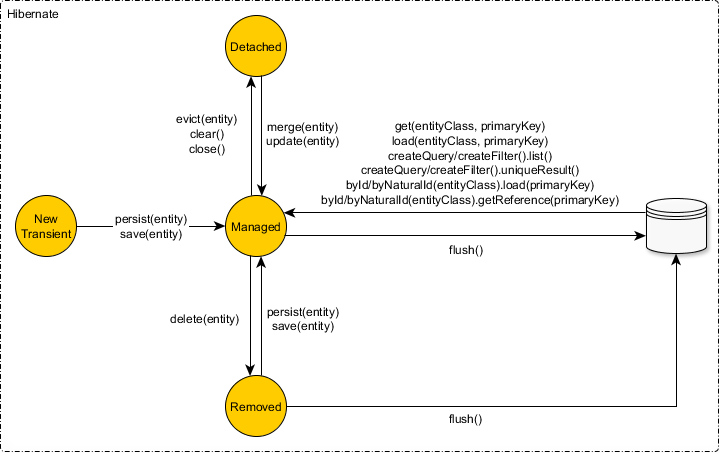
чтобы связать отдельный объект с активным сеансом гибернации, можно выбрать один из следующих вариантов опции:
-
установка
Hibernate (но не JPA 2.1) поддерживает повторное подключение через метод#update сеанса. Сеанс гибернации может связать только один объект сущности для данной строки базы данных. Это связано с тем, что контекст сохранения действует как кэш в памяти (кэш первого уровня), и только одно значение (сущность) связано с данным ключом (тип сущности и идентификатор базы данных). Сущность может быть повторно присоединена, только если нет другого объекта JVM (соответствует той же строке базы данных), уже связанной с текущим сеансом гибернации.
слияние
слияние будет копировать состояние обособленной сущности (источник) в экземпляр управляемой сущности (назначение). Если слияние сущности не имеет эквивалента в текущем сеансе, он будет извлечен из базы данных. Экземпляр отсоединенного объекта будет оставаться отсоединенным даже после слияния операция.
-
-
удалены
хотя JPA требует, чтобы удалялись только управляемые сущности, Hibernate также может удалять отдельные сущности (но только через вызов метода#delete сеанса). Удаленная сущность запланирована только для удаления, и фактическая инструкция удаления базы данных будет выполнена во время сеанса flush-time.
чтобы лучше понять переходы состояния JPA, вы можете визуализировать следующее диаграмма:
или если вы используете конкретный API Hibernate:
я заметил, что когда я использовал em.merge Я получил SELECT заявление для каждого INSERT, даже когда не было поля, которое JPA генерировало для меня-поле первичного ключа было UUID, который я установил сам. Я переключился на em.persist(myEntityObject) и просто INSERT заявления потом.
спецификация JPA говорит следующее о persist().
если X это отдельный объект,
EntityExistsExceptionможет быть брошен, когда сохраняются вызывается операция илиEntityExistsExceptionили ещеPersistenceExceptionможет быть брошен на флеш или время фиксации.
используя persist() будет подходящим, когда объект не нужно быть обособленным объектом. Возможно, вы предпочтете, чтобы код бросил PersistenceException Так что не быстрый.
хотя спецификация непонятно, persist() может установить @GeneratedValue @Id для объекта. merge() однако должен иметь объект с @Id уже сформирован.
некоторые дополнительные сведения о слиянии, которые помогут вам использовать merge over persist:
возвращение управляемого экземпляра, отличного от исходного объекта, является важной частью слияния процесс. Если экземпляр сущности с тем же идентификатором уже существует в контексте сохранения, поставщик перезапишет свое состояние состоянием объединяемого объекта, но управляемого версия, которая уже существовала, должна быть возвращена клиенту, чтобы она могла быть используемый. Если поставщик не обновите экземпляр Employee в контексте сохранения, любые ссылки на этот экземпляр станут не согласуется с новым государством, в котором происходит слияние.
когда merge() вызывается на новом объекте, он ведет себя аналогично операции persist (). Он добавляет сущность в контексте сохранения, но вместо добавления исходного экземпляра сущности она создает новый вместо этого скопируйте этот экземпляр и управляйте им. Копия, созданная слиянием() операция сохраняется как будто метод persist() был вызван на нем.
при наличии связей операция merge() попытается обновить управляемый объект чтобы указать на управляемые версии сущностей, на которые ссылается отдельная сущность. Если сущность имеет связь с объектом, не имеющим постоянного идентификатора, результатом операции слияния является не определено. Некоторые поставщики могут разрешить управляемой копии указывать на непостоянный объект, поскольку другие могут немедленно сделать исключение. Операция merge() может быть необязательной каскадируется в этих случаях, чтобы предотвратить возникновение исключения. Мы покроем каскадное слияние() операция далее в этом разделе. Если объединяемая сущность указывает на удаленную сущность, Исключение IllegalArgumentException будет брошен.
отношения ленивой загрузки являются частным случаем в операции слияния. Если ленивый-загрузка связь не была запущена на объекте раньше он стал отстраненным, что отношения будут игнорируется при объединении сущности. Если связь была запущена во время управления, а затем установлена в значение null во время отсоединения сущности, управляемая версия сущности также будет очищена во время слияния."
вся вышеуказанная информация была взята из" Pro JPA 2 Mastering the Java™ Persistence API " Майком Китом и Мерриком Шникариолом. Глава 6. Отделение и слияние секций. Эта книга фактически вторая книга, посвященная JPA авторами. Эта новая книга содержит много новой информации, затем бывшей. Я действительно рекомендовал прочитать эту книгу для тех, кто будет серьезно связан с JPA. Я извиняюсь за anonimously публикации моего первого ответа.
есть еще некоторые различия между merge и persist (Я перечислю снова те, которые уже размещены здесь):
D1. merge не делает переданную сущность управляемой, а возвращает другой экземпляр, который управляется. persist С другой стороны сделает переданный объект управляемым:
//MERGE: passedEntity remains unmanaged, but newEntity will be managed
Entity newEntity = em.merge(passedEntity);
//PERSIST: passedEntity will be managed after this
em.persist(passedEntity);
D2. Если вы удалите объект, а затем решите сохранить его обратно, вы можете сделать это только с помощью persist (), потому что merge бросит IllegalArgumentException.
D3. Если вы решили позаботиться вручную о своих идентификаторах (e.g с помощью UUIDs), то a merge
операция вызовет последующее SELECT запросы, чтобы искать существующие объекты с этим идентификатором, в то время как persist может не нужны эти запросы.
D4. Бывают случаи, когда вы просто не доверяете код, который вызывает ваш код, и для того, чтобы убедиться, что данные не обновляются, а вставляется, вы должны использовать persist.
я получал исключения lazyLoading на моем объекте, потому что я пытался получить доступ к ленивой загруженной коллекции, которая была в сеансе.
то, что я бы сделал, было в отдельном запросе, получить сущность из сеанса, а затем попытаться получить доступ к коллекции на моей странице jsp, которая была проблематичной.
чтобы облегчить это, я обновил тот же объект в своем контроллере и передал его моему jsp, хотя я представляю, когда я повторно сохранен в сеансе, что он также будет доступен, хотя SessionScope и не кинуть LazyLoadingException модификация Пример 2:
следующее сработало для меня:
// scenario 2 MY WAY
// tran starts
e = new MyEntity();
e = em.merge(e); // re-assign to the same entity "e"
//access e from jsp and it will work dandy!!
проходя через ответы, есть некоторые детали, отсутствующие в отношении "каскада" и генерации идентификаторов. вопрос
также, стоит отметить, что вы можете иметь отдельные Cascade аннотации для слияния и сохранения:Cascade.MERGE и Cascade.PERSIST которое будет обработано согласно используемому методу.
спецификация-ваш друг;)
Сценарий X:
таблица: Spitter (One), таблица: Spittles (Many) (Spittles является владельцем отношения с FK:spitter_id)
этот сценарий приводит к экономии: плевательница и обе плевки, как будто принадлежат одному и тому же Плевательнице.
Spitter spitter=new Spitter();
Spittle spittle3=new Spittle();
spitter.setUsername("George");
spitter.setPassword("test1234");
spittle3.setSpittle("I love java 2");
spittle3.setSpitter(spitter);
dao.addSpittle(spittle3); // <--persist
Spittle spittle=new Spittle();
spittle.setSpittle("I love java");
spittle.setSpitter(spitter);
dao.saveSpittle(spittle); //<-- merge!!
Сценарий Y:
это сохранит плевок, сохранит 2 плевка, но они не будут ссылаться на тот же плевок!
Spitter spitter=new Spitter();
Spittle spittle3=new Spittle();
spitter.setUsername("George");
spitter.setPassword("test1234");
spittle3.setSpittle("I love java 2");
spittle3.setSpitter(spitter);
dao.save(spittle3); // <--merge!!
Spittle spittle=new Spittle();
spittle.setSpittle("I love java");
spittle.setSpitter(spitter);
dao.saveSpittle(spittle); //<-- merge!!
Я нашел это объяснение из документов Hibernate просветляющим, потому что они содержат прецедент:
использование и семантика merge () кажется запутанным для новых пользователей. Во-первых, пока вы не пытаетесь использовать состояние объекта, загруженное в одном менеджере сущностей в другом новом менеджере сущностей, вы должны не нужно использовать merge () вообще. Некоторые целые приложения никогда не будут использовать этот метод.
обычно merge () используется в следующем сценарий:
- приложение загружает объект в первом entity manager
- объект передается на уровень представления
- внесены некоторые изменения в объект
- объект передается обратно на уровень бизнес-логики
- приложение сохраняет эти изменения, вызывая merge () во втором entity manager
вот точная семантика merge():
- если существует управляемый экземпляр с тем же идентификатором, который в настоящее время связан с контекстом сохраняемости, скопируйте состояние данного объекта в управляемый экземпляр
- если управляемый экземпляр в настоящее время не связан с контекстом персистентности, попробуйте загрузить его из базы данных или создать новый управляемый экземпляр
- возвращается управляемый экземпляр
- данный экземпляр не ассоциируется с контекстом персистентности он остается отделенным и обычно отбрасывается
от: http://docs.jboss.org/hibernate/entitymanager/3.6/reference/en/html/objectstate.html
JPA бесспорно является большим упрощением в области предпринимательства приложения, построенные на платформе Java. Как разработчик, который должен был справляюсь со сложностями старой сущности бобов в J2EE я вижу включение JPA среди спецификаций Java EE как большой скачок вперед. Однако, углубляясь в детали JPA, я нахожу то, что не так просто. В этой статье я имею дело с сравнением методы слияния и сохранения EntityManager, перекрытие поведение может вызвать замешательство не только новичка. Кроме Того, Я предложите обобщение, которое рассматривает оба метода как частные случаи a более общий метод комбинирования.
сохранение лица
в отличие от метода слияния метод persist довольно прост и интуитивно понятен. Наиболее распространенный сценарий использования метода persist можно суммировать следующим образом:
"вновь созданный экземпляр сущности класс передается методу persist. После возвращения этого метода объект управляется и планируется для вставки в базу данных. Это может произойти во время или до фиксации транзакции или при вызове метода flush. Если сущность ссылается на другую сущность через связь, отмеченную стратегией PERSIST cascade, эта процедура применяется и к ней."

спецификация идет больше в детали, однако, вспоминая их не важно, поскольку эти детали охватывают только более или менее экзотические ситуации.
объединение лиц
по сравнению с persist описание поведения слияния не так просто. Нет основного сценария, как в случае persist, и программист должен помнить все сценарии, чтобы написать правильный код. Мне кажется, что дизайнеры JPA хотели иметь какой-то метод, основной задачей которого была бы обработка отдельных объектов (как в отличие от метода persist, который в первую очередь имеет дело с вновь созданными сущностями.) Основная задача метода merge-передать состояние из неуправляемой сущности (переданной в качестве аргумента) в управляемый аналог в контексте персистентности. Однако эта задача разделяется на несколько сценариев, которые ухудшают разборчивость поведения общего метода.
вместо повторения абзацев из спецификации JPA я подготовил блок-схему, которая схематически отображает поведение метода merge:

Итак, когда я должен использовать persist и когда merge?
остаются
- вы хотите, чтобы метод всегда создавал новый объект и никогда не обновлял объект. В противном случае метод создает исключение вследствие нарушения уникальности первичного ключа.
- пакетные процессы, обработка сущностей с учетом состояния (см. шлюз узор.)
- оптимизация производительности
слияние
- требуется, чтобы метод вставлял или обновлял объект в базе данных.
- вы хотите обрабатывать объекты без гражданства (объекты передачи данных в службах)
- вы хотите вставить новый объект, который может иметь ссылку на другой объект, который может быть, но еще не создан (отношение должно быть помечено слиянием). Например, вставка новая фотография со ссылкой на новый или уже существующий альбом.
возможно, вы пришли сюда за советом о том, когда использовать остаются и когда использовать слияние. Я думаю, что это зависит от ситуации: насколько вероятно, что вам нужно создать новую запись и насколько трудно получить сохраненные данные.
предположим, вы можете использовать естественный ключ/идентификатор.
-
данные должны быть сохранены, но время от времени запись существует и требуется обновление. В этом случае вы можете попробовать persist и если он создает EntityExistsException, вы просматриваете его и объединяете данные:
попробуйте { entityManager.persist (entity) }
catch (исключение EntityExistsException) {/*извлечение и слияние*/}
-
сохраненные данные должны быть обновлены, но время от времени нет записи для данных еще. В этом случае вы просматриваете его и сохраняете, если объект отсутствует:
entity = entityManager.найти(ключ);
if (сущность == null) {entityManager.persist (entity);}
else {/*merge*/}
Если у вас нет естественного ключа/идентификатора, вам будет сложнее выяснить, существует ли сущность или нет, или как ее искать.
слияния можно рассматривать двумя способами:
- если изменения обычно небольшие, примените их к управляемой сущности.
- если изменения являются общими, скопируйте идентификатор из сохраненной сущности, как а также неизмененные данные. Затем вызовите EntityManager:: merge() для замены старого содержимого.
persist (entity) должен использоваться с совершенно новыми сущностями, чтобы добавить их в БД (если сущность уже существует в БД, будет entityexistsexception throw).
merge (entity) следует использовать, чтобы вернуть сущность в контекст сохранения, если сущность была отсоединена и изменена.
вероятно, persist генерирует инструкцию INSERT sql и инструкцию merge UPDATE sql (но я не уверен).
еще одно наблюдение:
merge() будет заботиться только о автоматически сгенерированном id (проверено на IDENTITY и SEQUENCE), Если запись с таким идентификатором уже существует в таблице. В таком случае ...--0--> попытается обновить рекорд.
Если, однако, идентификатор отсутствует или не соответствует существующим записям, merge() полностью проигнорирует его и попросит db выделить новый. Это иногда источник многих ошибок. Не используйте merge() чтобы принудительно ввести id для нового запись.
persist() С другой стороны никогда не позволит вам даже передать ему идентификатор. Он немедленно провалится. В моем случае это:
вызвано: org.зимовать.PersistentObjectException: отдельный объект прошло упорствовать
hibernate-JPA javadoc имеет подсказку:
закидываем: javax.стойкость.EntityExistsException - если сущность уже существует. (Если предприятие уже существует, EntityExistsException может быть вызвано, когда операция persist вызывается или EntityExistsException или другое исключение PersistenceException может быть брошен на флеш или фиксации времени.)