Как асинхронно копировать память с хоста на устройство с помощью потоков thrust и CUDA
Я хотел бы скопировать память с хоста на устройство, используя тягу, как в
thrust::host_vector<float> h_vec(1 << 28);
thrust::device_vector<float> d_vec(1 << 28);
thrust::copy(h_vec.begin(), h_vec.end(), d_vec.begin());
использование потоков CUDA аналогично тому, как вы копируете память с устройства на устройство с помощью потоков:
cudaStream_t s;
cudaStreamCreate(&s);
thrust::device_vector<float> d_vec1(1 << 28), d_vec2(1 << 28);
thrust::copy(thrust::cuda::par.on(s), d_vec1.begin(), d_vec1.end(), d_vec2.begin());
cudaStreamSynchronize(s);
cudaStreamDestroy(s);
проблема в том, что я не могу установить политику выполнения в CUDA, чтобы указать поток при копировании с хоста на устройство, потому что в этом случае тяга будет предполагать, что оба вектора хранятся на устройстве. Есть ли способ обойти это проблема? Я использую последнюю версию тяги от github(в версии говорится 1.8.H-файл).
2 ответов
как указано в комментариях, я не думаю, что это будет возможно напрямую с thrust::copy. Однако мы можем использовать cudaMemcpyAsync в приложении тяги для достижения цели асинхронных копий и перекрытия копии с вычислением.
вот пример:
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
#include <thrust/system/cuda/experimental/pinned_allocator.h>
#include <thrust/system/cuda/execution_policy.h>
#include <thrust/fill.h>
#include <thrust/sequence.h>
#include <thrust/for_each.h>
#include <iostream>
// DSIZE determines duration of H2D and D2H transfers
#define DSIZE (1048576*8)
// SSIZE,LSIZE determine duration of kernel launched by thrust
#define SSIZE (1024*512)
#define LSIZE 1
// KSIZE determines size of thrust kernels (number of threads per block)
#define KSIZE 64
#define TV1 1
#define TV2 2
typedef int mytype;
typedef thrust::host_vector<mytype, thrust::cuda::experimental::pinned_allocator<mytype> > pinnedVector;
struct sum_functor
{
mytype *dptr;
sum_functor(mytype* _dptr) : dptr(_dptr) {};
__host__ __device__ void operator()(mytype &data) const
{
mytype result = data;
for (int j = 0; j < LSIZE; j++)
for (int i = 0; i < SSIZE; i++)
result += dptr[i];
data = result;
}
};
int main(){
pinnedVector hi1(DSIZE);
pinnedVector hi2(DSIZE);
pinnedVector ho1(DSIZE);
pinnedVector ho2(DSIZE);
thrust::device_vector<mytype> di1(DSIZE);
thrust::device_vector<mytype> di2(DSIZE);
thrust::device_vector<mytype> do1(DSIZE);
thrust::device_vector<mytype> do2(DSIZE);
thrust::device_vector<mytype> dc1(KSIZE);
thrust::device_vector<mytype> dc2(KSIZE);
thrust::fill(hi1.begin(), hi1.end(), TV1);
thrust::fill(hi2.begin(), hi2.end(), TV2);
thrust::sequence(do1.begin(), do1.end());
thrust::sequence(do2.begin(), do2.end());
cudaStream_t s1, s2;
cudaStreamCreate(&s1); cudaStreamCreate(&s2);
cudaMemcpyAsync(thrust::raw_pointer_cast(di1.data()), thrust::raw_pointer_cast(hi1.data()), di1.size()*sizeof(mytype), cudaMemcpyHostToDevice, s1);
cudaMemcpyAsync(thrust::raw_pointer_cast(di2.data()), thrust::raw_pointer_cast(hi2.data()), di2.size()*sizeof(mytype), cudaMemcpyHostToDevice, s2);
thrust::for_each(thrust::cuda::par.on(s1), do1.begin(), do1.begin()+KSIZE, sum_functor(thrust::raw_pointer_cast(di1.data())));
thrust::for_each(thrust::cuda::par.on(s2), do2.begin(), do2.begin()+KSIZE, sum_functor(thrust::raw_pointer_cast(di2.data())));
cudaMemcpyAsync(thrust::raw_pointer_cast(ho1.data()), thrust::raw_pointer_cast(do1.data()), do1.size()*sizeof(mytype), cudaMemcpyDeviceToHost, s1);
cudaMemcpyAsync(thrust::raw_pointer_cast(ho2.data()), thrust::raw_pointer_cast(do2.data()), do2.size()*sizeof(mytype), cudaMemcpyDeviceToHost, s2);
cudaDeviceSynchronize();
for (int i=0; i < KSIZE; i++){
if (ho1[i] != ((LSIZE*SSIZE*TV1) + i)) { std::cout << "mismatch on stream 1 at " << i << " was: " << ho1[i] << " should be: " << ((DSIZE*TV1)+i) << std::endl; return 1;}
if (ho2[i] != ((LSIZE*SSIZE*TV2) + i)) { std::cout << "mismatch on stream 2 at " << i << " was: " << ho2[i] << " should be: " << ((DSIZE*TV2)+i) << std::endl; return 1;}
}
std::cout << "Success!" << std::endl;
return 0;
}
для моего тестового случая я использовал RHEL5.5, Quadro5000, и cuda 6.5 RC. Этот пример предназначен для создания очень маленьких ядер (только один threadblock, пока KSIZE маленький, скажем, 32 или 64), так что ядра, которые толкают, создают из thrust::for_each могут работать одновременно.
когда я профилирую этот код, я вижу:
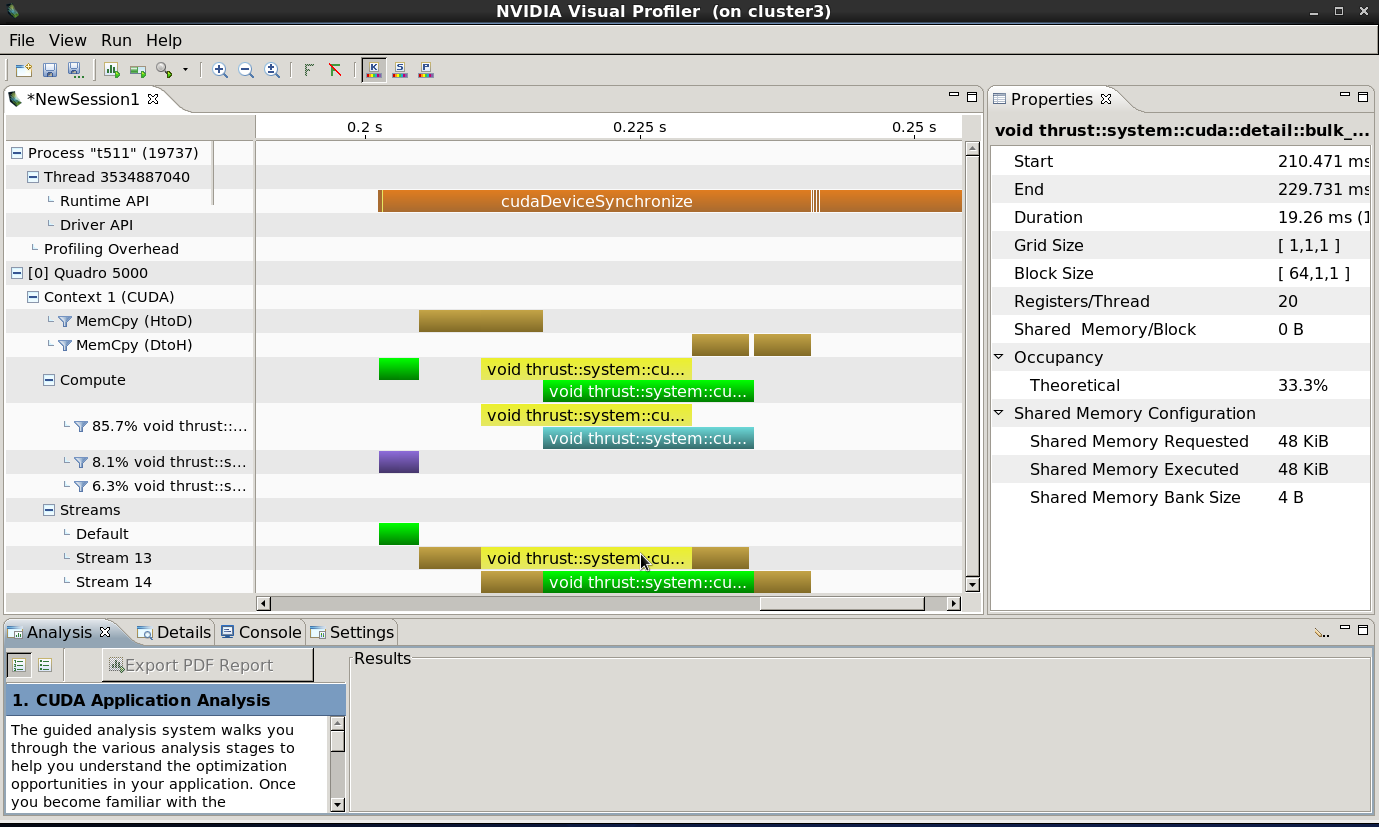
это указывает на то, что мы достигаем надлежащего перекрытия как между ядрами тяги, так и между операциями копирования и ядрами тяги, а также асинхронного копирования данных по завершении ядер. Обратите внимание, что cudaDeviceSynchronize() операция "заполняет" временную шкалу, указывая, что все асинхронные операции (копирование данных, функции тяги) были выданы асинхронно, и управление возвращено в основной поток до выполнения любой из операций. Все это ожидается, правильное поведение для полного параллелизма между хостом, GPU и операциями копирования данных.
вот работающий пример использования thrust::cuda::experimental::pinned_allocator<T>:
// Compile with:
// nvcc --std=c++11 mem_async.cu -o mem_async
#include <cuda.h>
#include <cuda_runtime.h>
#include <cufft.h>
#include <thrust/device_vector.h>
#include <thrust/host_vector.h>
#include <thrust/fill.h>
#include <thrust/system/cuda/experimental/pinned_allocator.h>
#define LEN 1024
int main(int argc, char *argv[]) {
thrust::host_vector<float, thrust::cuda::experimental::pinned_allocator<float>> h_vec(LEN);
thrust::device_vector<float> d_vec(LEN);
thrust::fill(d_vec.begin(), d_vec.end(), -1.0);
cudaMemcpyAsync(thrust::raw_pointer_cast(h_vec.data()),
thrust::raw_pointer_cast(d_vec.data()),
d_vec.size()*sizeof(float),
cudaMemcpyDeviceToHost);
// Comment out this line to see what happens.
cudaDeviceSynchronize();
std::cout << h_vec[0] << std::endl;
}
прокомментируйте шаг синхронизации, и вы должны получить 0 печать на консоль из-за асинхронной передачи памяти.