Как использовать аудио примеры данных из Java Sound?
этот вопрос обычно задается как часть другого вопроса, но оказывается, что ответ длинный. Я решил ответить на него здесь, чтобы я мог связаться с ним в другом месте.
хотя я не знаю, как Java может производить аудио образцы для нас в это время, если это изменится в будущем, это может быть место для него. Я знаю это JavaFX есть некоторые вещи, как это, например AudioSpectrumListener, но все еще не способ доступа к образцам непосредственно.
Я использую javax.sound.sampled для воспроизведения и/или записи, но я хотел бы сделать что-то со звуком.
возможно, я хотел бы отобразить его визуально или каким-то образом обработать.
как получить доступ к аудио-образцам данных, чтобы сделать это со звуком Java?
Читайте также:
- Java Sound Tutorials (должностное лицо)
- Звуковые Ресурсы Java (неофициальный)
2 ответов
ну, самый простой ответ заключается в том, что на данный момент Java не может производить образцы данных для программиста.
эта цитата из официального учебника:
существует два способа применения обработки сигналов:
вы можете использовать любую обработку, поддерживаемую микшером или его линиями компонентов, запросив
Controlобъекты, а затем установка элементов управления по желанию пользователя. Типичные элементы управления, поддерживаемые смесители и линии включают усиление, панорамирование и элементы управления реверберацией.если вид обработки вам не обеспечен смесителем или своими линиями, то ваша программа может работать сразу на аудио байтах, манипулируя ими как пожелано.
на этой странице более подробно обсуждается первая техника, потому что нет специального API для второй техники.
воспроизведение с javax.sound.sampled в основном действует как мост между файлом и аудио устройств. Байты считываются из файла и отправил.
не предполагайте, что байты являются значимыми звуковыми образцами! Если у вас нет 8-битного файла AIFF, это не так. (С другой стороны, если образцы are определенно 8-битная подпись, вы can выполнять арифметические действия с ними. Использование 8-бит-один из способов избежать описанной здесь сложности, если вы просто играете вокруг.)
поэтому вместо этого я перечислю типы AudioFormat.Encoding и описано, как расшифровать их самостоятельно. Этот ответ будет не покройте, как их кодировать, но он включен в полный пример кода внизу. Кодирование-это в основном процесс декодирования в обратном порядке.
это длинный ответ, но я хотел дать подробный обзор.
Немного О Цифровом Аудио
вообще когда цифровой звук объясняется, мы имеем в виду Линейная Импульсно-Кодовая Модуляция (как LPCM).
непрерывная звуковая волна отбирается через регулярные промежутки времени, а амплитуды квантованы до целых чисел некоторого масштаба.
здесь показана синусоидальная волна, дискретизированная и квантованная до 4-бит:
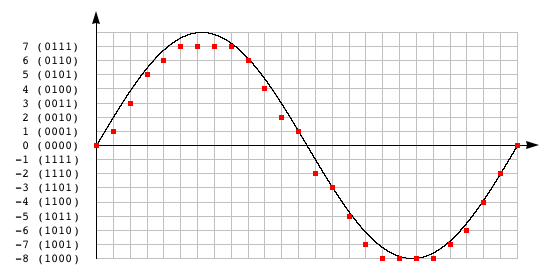
(обратите внимание, что самое положительное значение в два!--87--> представление на 1 меньше, чем самое отрицательное значение. Это незначительная деталь, о которой нужно знать. Например, если вы отсекаете аудио и забываете об этом, положительные клипы переполняются.)
когда у нас есть аудио на компьютере, у нас есть массив из этих образцов. Образец массива-это то, что мы хотим превратить byte массив для.
чтобы декодировать образцы PCM, мы не заботимся о частоте дискретизации или количестве каналов, поэтому я не буду много говорить о них здесь. Каналы обычно чередуются, так что если бы у нас была массив из них, они будут храниться следующим образом:
Index 0: Sample 0 (Left Channel)
Index 1: Sample 0 (Right Channel)
Index 2: Sample 1 (Left Channel)
Index 3: Sample 1 (Right Channel)
Index 4: Sample 2 (Left Channel)
Index 5: Sample 2 (Right Channel)
...
другими словами, для стерео образцы в массиве просто чередуются между левым и правым.
Предположения
все примеры кода будут предполагать следующие объявления:
-
byte[] bytes;наbyteмассив, чтение изAudioInputStream. -
float[] samples;пример вывода массива, который мы собираемся заполнить. -
float sample;в образец, над которым мы сейчас работаем. -
long temp;промежуточное значение, используемое для общих манипуляций. -
int i;должности вbyteмассив, в котором начинаются данные текущего образца.
мы нормализуем все образцы в нашем float[] массив в диапазон -1f <= sample <= 1f. Все аудио с плавающей запятой, которое я видел, идет этим путем, и это довольно удобно.
если наш источник звука еще не пришел, как это (как для например, целочисленные выборки), мы можем нормализовать их сами, используя следующее:
sample = sample / fullScale(bitsPerSample);
здесь fullScale is 2bitsPerSample - 1, то есть Math.pow(2, bitsPerSample-1).
как заставить byte массив в значимые данные?
The byte массив содержит образцы кадров, разделенные и все в строке. Это на самом деле очень прямолинейно, за исключением того, что называется endianness, который является заказ из bytes в каждом пакете образца.
вот такая схема. Этот образец (упакованный в byte array) содержит десятичное значение 9999:
24-bit sample as big-endian: bytes[i] bytes[i + 1] bytes[i + 2] ┌──────┐ ┌──────┐ ┌──────┐ 00000000 00100111 00001111 24-bit sample as little-endian: bytes[i] bytes[i + 1] bytes[i + 2] ┌──────┐ ┌──────┐ ┌──────┐ 00001111 00100111 00000000
они содержат те же двоичные значения; однако byte заказы отменяются.
- в big-endian, тем более значительным
bytes приходят перед менее значительнымbytes. - в прямой, менее существенных
bytes приходят перед более значительнымbytes.
WAV и файлы хранятся в прямом порядке байтов и файлы AIFF хранятся в порядке big-endian. Endianness можно получить от AudioFormat.isBigEndian.
объединить bytes и положить их в наш long temp переменная, то:
- побитовое и каждое
byteС маской0xFF(т. е.0b1111_1111), чтобы избежать признак-расширение когдаbyteis автоматически повышается. (char,byteиshortзваниеintкогда на них выполняется арифметика.) См. также что значитvalue & 0xffделать на Java? - бит shift каждый
byteв положение. - побитовое или
bytes вместе.
вот 24-битный пример:
long temp;
if (isBigEndian) {
temp = (
((bytes[i ] & 0xffL) << 16)
| ((bytes[i + 1] & 0xffL) << 8)
| (bytes[i + 2] & 0xffL)
);
} else {
temp = (
(bytes[i ] & 0xffL)
| ((bytes[i + 1] & 0xffL) << 8)
| ((bytes[i + 2] & 0xffL) << 16)
);
}
обратите внимание, что порядок сдвига отменяется на основе endianness.
это также может быть обобщен на цикл, который можно увидеть в полном коде в нижней части этого ответа. (См. unpackAnyBit и packAnyBit методы.)
теперь у нас есть byteы соединяются вместе, мы можем сделать еще несколько шагов, чтобы превратить их в образец. Следующие шаги зависят от фактического кодирования.
как расшифровать Encoding.PCM_SIGNED?
знак дополнения двух должен быть расширен. Это означает, что если самый значительный бит (MSB) установлен в 1, мы заполняем все биты над ним с 1s. Арифметический сдвиг вправо (>>) сделаем начинку, для нас автоматически, если знаковый бит установлен, поэтому я обычно делаю это так:
int bitsToExtend = Long.SIZE - bitsPerSample;
float sample = (temp << bitsToExtend) >> bitsToExtend.
(где Long.SIZE - это 64. Если наши temp переменная не long, мы бы использовали что-то другое. Если мы использовали, например,int temp вместо этого мы бы использовали 32.)
чтобы понять, как это работает, вот диаграмма расширения знака 8-бит до 16-бит:
11111111 is the byte value -1, but the upper bits of the short are 0. Shift the byte's MSB in to the MSB position of the short. 0000 0000 1111 1111 << 8 ─────────────────── 1111 1111 0000 0000 Shift it back and the right-shift fills all the upper bits with 1s. We now have the short value of -1. 1111 1111 0000 0000 >> 8 ─────────────────── 1111 1111 1111 1111
положительные значения (которые имели 0 в MSB) остаются неизменными. Это хорошее свойство арифметического сдвига вправо.
затем нормализуйте образец, как описано в Предположения.
возможно, Вам не нужно писать явное расширение знака, если ваш код прост
Java делает знак-расширение автоматически при преобразовании из одного интегрального типа в более крупный тип, например byte до int. Если ты ... --112-->знаю что ваш формат ввода и вывода всегда подписанный, вы можете использовать автоматическое расширение знака при объединении байтов на предыдущем шаге.
Напомним, из раздела выше (как принудить массив байтов к значимым данным?), которые мы использовали b & 0xFF предотвратить знак-расширение от происходить. Если вы просто удалите & 0xFF от высочайших byte, знак-расширение произойдет автоматически.
например, следующие декоды signed, big-endian, 16-bit образцы:
for (int i = 0; i < bytes.length; i++) {
int sample = (bytes[i] << 8) // high byte is sign-extended
| (bytes[i + 1] & 0xFF); // low byte is not
// ...
}
как расшифровать Encoding.PCM_UNSIGNED?
мы превращаем его в подписанный номер. Неподписанные образцы просто смещаются так, что, например:
- значение без знака 0 соответствует самому отрицательному значению со знаком.
- значение без знака 2bitsPerSample - 1 соответствует знаковому значению 0.
- значение без знака 2bitsPerSample соответствует самому положительному знаковое значение.
Итак, это оказывается довольно просто. Просто вычесть смещение:
float sample = temp - fullScale(bitsPerSample);
затем нормализуйте образец, как описано в Предположения.
как расшифровать Encoding.PCM_FLOAT?
это новое с Java 7.
на практике PCM с плавающей запятой обычно является 32-разрядным или 64-разрядным IEEE и уже нормализован до диапазона ±1.0. Образцы можно получить с методы утилиты Float#intBitsToFloat и Double#longBitsToDouble.
// IEEE 32-bit
float sample = Float.intBitsToFloat((int) temp);
// IEEE 64-bit
double sampleAsDouble = Double.longBitsToDouble(temp);
float sample = (float) sampleAsDouble; // or just use double for arithmetic
как расшифровать Encoding.ULAW и Encoding.ALAW?
это компандирования кодеки сжатия, которые более распространены в телефонах и тому подобное. Они поддерживаются javax.sound.sampled я предполагаю, потому что они используют формат Au Солнца. (Однако это не ограничивается только этим типом контейнера. Например, WAV может содержать эти кодирования.)
вы можете концептуализировать закон и μ-law как будто они формат с плавающей запятой. Это форматы PCM, но диапазон значений нелинейный.
есть два способа их расшифровать. Я покажу путь, который использует математическую формулу. Вы также можете декодировать их, манипулируя двоичным файлом напрямую, который является описано в этом блоге но это больше похоже на эзотерику.
для обоих, сжатые данные 8-разрядные. Стандартно a-закон 13-бит при декодировании и μ-закон 14-бит при декодировании; однако применение формулы дает диапазон ±1.0.
прежде чем вы сможете применить формулу, есть три вещи, чтобы сделать:
- некоторые из битов стандартно инвертированы для хранения из-за причин, связанных с целостностью данных.
- они хранятся как знак и величину (а не дополнение).
- формула также ожидает диапазон
±1.0, так что 8-битное значение должно быть уменьшено.
для μ-закон все биты инвертируются, так:
temp ^= 0xffL; // 0xff == 0b1111_1111
(обратите внимание, что мы не можем использовать ~, потому что мы не хотим инвертировать высокие биты long.)
для A-закона, другое инвертируется, так:
temp ^= 0x55L; // 0x55 == 0b0101_0101
(XOR можно использовать для инверсии. См.Как установить, очистить и переключить a немного?)
чтобы преобразовать из знака и величины в дополнение к двум, мы:
- проверьте, установлен ли бит знака.
- если это так, очистите бит знака и отрицайте число.
// 0x80 == 0b1000_0000
if ((temp & 0x80L) != 0) {
temp ^= 0x80L;
temp = -temp;
}
затем масштабируйте кодированные числа так же, как описано в Предположения:
sample = temp / fullScale(8);
теперь мы можем применить расширение.
формула μ-закона переведена на Java затем:
sample = (float) (
signum(sample)
*
(1.0 / 255.0)
*
(pow(256.0, abs(sample)) - 1.0)
);
формула A-law, переведенная на Java, тогда:
float signum = signum(sample);
sample = abs(sample);
if (sample < (1.0 / (1.0 + log(87.7)))) {
sample = (float) (
sample * ((1.0 + log(87.7)) / 87.7)
);
} else {
sample = (float) (
exp((sample * (1.0 + log(87.7))) - 1.0) / 87.7
);
}
sample = signum * sample;
вот полный пример кода SimpleAudioConversion класса.
package mcve.audio;
import javax.sound.sampled.AudioFormat;
import javax.sound.sampled.AudioFormat.Encoding;
import static java.lang.Math.*;
/**
* <p>Performs simple audio format conversion.</p>
*
* <p>Example usage:</p>
*
* <pre>{@code AudioInputStream ais = ... ;
* SourceDataLine line = ... ;
* AudioFormat fmt = ... ;
*
* // do setup
*
* for (int blen = 0; (blen = ais.read(bytes)) > -1;) {
* int slen;
* slen = SimpleAudioConversion.decode(bytes, samples, blen, fmt);
*
* // do something with samples
*
* blen = SimpleAudioConversion.encode(samples, bytes, slen, fmt);
* line.write(bytes, 0, blen);
* }}</pre>
*
* @author Radiodef
* @see <a href="http://stackoverflow.com/a/26824664/2891664">Overview on Stack Overflow</a>
*/
public final class SimpleAudioConversion {
private SimpleAudioConversion() {}
/**
* Converts from a byte array to an audio sample float array.
*
* @param bytes the byte array, filled by the AudioInputStream
* @param samples an array to fill up with audio samples
* @param blen the return value of AudioInputStream.read
* @param fmt the source AudioFormat
*
* @return the number of valid audio samples converted
*
* @throws NullPointerException if bytes, samples or fmt is null
* @throws ArrayIndexOutOfBoundsException
* if bytes.length is less than blen or
* if samples.length is less than blen / bytesPerSample(fmt.getSampleSizeInBits())
*/
public static int decode(byte[] bytes,
float[] samples,
int blen,
AudioFormat fmt) {
int bitsPerSample = fmt.getSampleSizeInBits();
int bytesPerSample = bytesPerSample(bitsPerSample);
boolean isBigEndian = fmt.isBigEndian();
Encoding encoding = fmt.getEncoding();
double fullScale = fullScale(bitsPerSample);
int i = 0;
int s = 0;
while (i < blen) {
long temp = unpackBits(bytes, i, isBigEndian, bytesPerSample);
float sample = 0f;
if (encoding == Encoding.PCM_SIGNED) {
temp = extendSign(temp, bitsPerSample);
sample = (float) (temp / fullScale);
} else if (encoding == Encoding.PCM_UNSIGNED) {
temp = unsignedToSigned(temp, bitsPerSample);
sample = (float) (temp / fullScale);
} else if (encoding == Encoding.PCM_FLOAT) {
if (bitsPerSample == 32) {
sample = Float.intBitsToFloat((int) temp);
} else if (bitsPerSample == 64) {
sample = (float) Double.longBitsToDouble(temp);
}
} else if (encoding == Encoding.ULAW) {
sample = bitsToMuLaw(temp);
} else if (encoding == Encoding.ALAW) {
sample = bitsToALaw(temp);
}
samples[s] = sample;
i += bytesPerSample;
s++;
}
return s;
}
/**
* Converts from an audio sample float array to a byte array.
*
* @param samples an array of audio samples to encode
* @param bytes an array to fill up with bytes
* @param slen the return value of the decode method
* @param fmt the destination AudioFormat
*
* @return the number of valid bytes converted
*
* @throws NullPointerException if samples, bytes or fmt is null
* @throws ArrayIndexOutOfBoundsException
* if samples.length is less than slen or
* if bytes.length is less than slen * bytesPerSample(fmt.getSampleSizeInBits())
*/
public static int encode(float[] samples,
byte[] bytes,
int slen,
AudioFormat fmt) {
int bitsPerSample = fmt.getSampleSizeInBits();
int bytesPerSample = bytesPerSample(bitsPerSample);
boolean isBigEndian = fmt.isBigEndian();
Encoding encoding = fmt.getEncoding();
double fullScale = fullScale(bitsPerSample);
int i = 0;
int s = 0;
while (s < slen) {
float sample = samples[s];
long temp = 0L;
if (encoding == Encoding.PCM_SIGNED) {
temp = (long) (sample * fullScale);
} else if (encoding == Encoding.PCM_UNSIGNED) {
temp = (long) (sample * fullScale);
temp = signedToUnsigned(temp, bitsPerSample);
} else if (encoding == Encoding.PCM_FLOAT) {
if (bitsPerSample == 32) {
temp = Float.floatToRawIntBits(sample);
} else if (bitsPerSample == 64) {
temp = Double.doubleToRawLongBits(sample);
}
} else if (encoding == Encoding.ULAW) {
temp = muLawToBits(sample);
} else if (encoding == Encoding.ALAW) {
temp = aLawToBits(sample);
}
packBits(bytes, i, temp, isBigEndian, bytesPerSample);
i += bytesPerSample;
s++;
}
return i;
}
/**
* Computes the block-aligned bytes per sample of the audio format,
* using Math.ceil(bitsPerSample / 8.0).
* <p>
* Round towards the ceiling because formats that allow bit depths
* in non-integral multiples of 8 typically pad up to the nearest
* integral multiple of 8. So for example, a 31-bit AIFF file will
* actually store 32-bit blocks.
*
* @param bitsPerSample the return value of AudioFormat.getSampleSizeInBits
* @return The block-aligned bytes per sample of the audio format.
*/
public static int bytesPerSample(int bitsPerSample) {
return (int) ceil(bitsPerSample / 8.0); // optimization: ((bitsPerSample + 7) >>> 3)
}
/**
* Computes the largest magnitude representable by the audio format,
* using Math.pow(2.0, bitsPerSample - 1). Note that for two's complement
* audio, the largest positive value is one less than the return value of
* this method.
* <p>
* The result is returned as a double because in the case that
* bitsPerSample is 64, a long would overflow.
*
* @param bitsPerSample the return value of AudioFormat.getBitsPerSample
* @return the largest magnitude representable by the audio format
*/
public static double fullScale(int bitsPerSample) {
return pow(2.0, bitsPerSample - 1); // optimization: (1L << (bitsPerSample - 1))
}
private static long unpackBits(byte[] bytes,
int i,
boolean isBigEndian,
int bytesPerSample) {
switch (bytesPerSample) {
case 1: return unpack8Bit(bytes, i);
case 2: return unpack16Bit(bytes, i, isBigEndian);
case 3: return unpack24Bit(bytes, i, isBigEndian);
default: return unpackAnyBit(bytes, i, isBigEndian, bytesPerSample);
}
}
private static long unpack8Bit(byte[] bytes, int i) {
return bytes[i] & 0xffL;
}
private static long unpack16Bit(byte[] bytes,
int i,
boolean isBigEndian) {
if (isBigEndian) {
return (
((bytes[i ] & 0xffL) << 8)
| (bytes[i + 1] & 0xffL)
);
} else {
return (
(bytes[i ] & 0xffL)
| ((bytes[i + 1] & 0xffL) << 8)
);
}
}
private static long unpack24Bit(byte[] bytes,
int i,
boolean isBigEndian) {
if (isBigEndian) {
return (
((bytes[i ] & 0xffL) << 16)
| ((bytes[i + 1] & 0xffL) << 8)
| (bytes[i + 2] & 0xffL)
);
} else {
return (
(bytes[i ] & 0xffL)
| ((bytes[i + 1] & 0xffL) << 8)
| ((bytes[i + 2] & 0xffL) << 16)
);
}
}
private static long unpackAnyBit(byte[] bytes,
int i,
boolean isBigEndian,
int bytesPerSample) {
long temp = 0;
if (isBigEndian) {
for (int b = 0; b < bytesPerSample; b++) {
temp |= (bytes[i + b] & 0xffL) << (
8 * (bytesPerSample - b - 1)
);
}
} else {
for (int b = 0; b < bytesPerSample; b++) {
temp |= (bytes[i + b] & 0xffL) << (8 * b);
}
}
return temp;
}
private static void packBits(byte[] bytes,
int i,
long temp,
boolean isBigEndian,
int bytesPerSample) {
switch (bytesPerSample) {
case 1: pack8Bit(bytes, i, temp);
break;
case 2: pack16Bit(bytes, i, temp, isBigEndian);
break;
case 3: pack24Bit(bytes, i, temp, isBigEndian);
break;
default: packAnyBit(bytes, i, temp, isBigEndian, bytesPerSample);
break;
}
}
private static void pack8Bit(byte[] bytes, int i, long temp) {
bytes[i] = (byte) (temp & 0xffL);
}
private static void pack16Bit(byte[] bytes,
int i,
long temp,
boolean isBigEndian) {
if (isBigEndian) {
bytes[i ] = (byte) ((temp >>> 8) & 0xffL);
bytes[i + 1] = (byte) ( temp & 0xffL);
} else {
bytes[i ] = (byte) ( temp & 0xffL);
bytes[i + 1] = (byte) ((temp >>> 8) & 0xffL);
}
}
private static void pack24Bit(byte[] bytes,
int i,
long temp,
boolean isBigEndian) {
if (isBigEndian) {
bytes[i ] = (byte) ((temp >>> 16) & 0xffL);
bytes[i + 1] = (byte) ((temp >>> 8) & 0xffL);
bytes[i + 2] = (byte) ( temp & 0xffL);
} else {
bytes[i ] = (byte) ( temp & 0xffL);
bytes[i + 1] = (byte) ((temp >>> 8) & 0xffL);
bytes[i + 2] = (byte) ((temp >>> 16) & 0xffL);
}
}
private static void packAnyBit(byte[] bytes,
int i,
long temp,
boolean isBigEndian,
int bytesPerSample) {
if (isBigEndian) {
for (int b = 0; b < bytesPerSample; b++) {
bytes[i + b] = (byte) (
(temp >>> (8 * (bytesPerSample - b - 1))) & 0xffL
);
}
} else {
for (int b = 0; b < bytesPerSample; b++) {
bytes[i + b] = (byte) ((temp >>> (8 * b)) & 0xffL);
}
}
}
private static long extendSign(long temp, int bitsPerSample) {
int bitsToExtend = Long.SIZE - bitsPerSample;
return (temp << bitsToExtend) >> bitsToExtend;
}
private static long unsignedToSigned(long temp, int bitsPerSample) {
return temp - (long) fullScale(bitsPerSample);
}
private static long signedToUnsigned(long temp, int bitsPerSample) {
return temp + (long) fullScale(bitsPerSample);
}
// mu-law constant
private static final double MU = 255.0;
// A-law constant
private static final double A = 87.7;
// natural logarithm of A
private static final double LN_A = log(A);
private static float bitsToMuLaw(long temp) {
temp ^= 0xffL;
if ((temp & 0x80L) != 0) {
temp = -(temp ^ 0x80L);
}
float sample = (float) (temp / fullScale(8));
return (float) (
signum(sample)
*
(1.0 / MU)
*
(pow(1.0 + MU, abs(sample)) - 1.0)
);
}
private static long muLawToBits(float sample) {
double sign = signum(sample);
sample = abs(sample);
sample = (float) (
sign * (log(1.0 + (MU * sample)) / log(1.0 + MU))
);
long temp = (long) (sample * fullScale(8));
if (temp < 0) {
temp = -temp ^ 0x80L;
}
return temp ^ 0xffL;
}
private static float bitsToALaw(long temp) {
temp ^= 0x55L;
if ((temp & 0x80L) != 0) {
temp = -(temp ^ 0x80L);
}
float sample = (float) (temp / fullScale(8));
float sign = signum(sample);
sample = abs(sample);
if (sample < (1.0 / (1.0 + LN_A))) {
sample = (float) (sample * ((1.0 + LN_A) / A));
} else {
sample = (float) (exp((sample * (1.0 + LN_A)) - 1.0) / A);
}
return sign * sample;
}
private static long aLawToBits(float sample) {
double sign = signum(sample);
sample = abs(sample);
if (sample < (1.0 / A)) {
sample = (float) ((A * sample) / (1.0 + LN_A));
} else {
sample = (float) ((1.0 + log(A * sample)) / (1.0 + LN_A));
}
sample *= sign;
long temp = (long) (sample * fullScale(8));
if (temp < 0) {
temp = -temp ^ 0x80L;
}
return temp ^ 0x55L;
}
}
вот как вы получаете фактические данные выборки из текущего воспроизводимого звука. The другой отличный ответ расскажет вам, что означают данные. Не пробовали его на другой ОС, чем моя машина Windows 10 YMMV. Для меня это тянет текущее системное записывающее устройство по умолчанию. В Windows установите его в "Stereo Mix" вместо "микрофона", чтобы получить воспроизводимый звук. Возможно, вам придется переключить "Показать отключенные устройства", чтобы увидеть"Stereo Mix".
import javax.sound.sampled.*;
public class SampleAudio {
private static long extendSign(long temp, int bitsPerSample) {
int extensionBits = 64 - bitsPerSample;
return (temp << extensionBits) >> extensionBits;
}
public static void main(String[] args) throws LineUnavailableException {
float sampleRate = 8000;
int sampleSizeBits = 16;
int numChannels = 1; // Mono
AudioFormat format = new AudioFormat(sampleRate, sampleSizeBits, numChannels, true, true);
TargetDataLine tdl = AudioSystem.getTargetDataLine(format);
tdl.open(format);
tdl.start();
if (!tdl.isOpen()) {
System.exit(1);
}
byte[] data = new byte[(int)sampleRate*10];
int read = tdl.read(data, 0, (int)sampleRate*10);
if (read > 0) {
for (int i = 0; i < read-1; i = i + 2) {
long val = ((data[i] & 0xffL) << 8L) | (data[i + 1] & 0xffL);
long valf = extendSign(val, 16);
System.out.println(i + "\t" + valf);
}
}
tdl.close();
}
}