Как использовать OpenNLP с Java?
Я хочу отправить английское предложение и сделать некоторую обработку. Я хотел бы использовать openNLP. У меня он установлен
когда я выполняю команду
I:WorkshopProgrammingnlpopennlp-tools-1.5.0-binopennlp-tools-1.5.0>java -jar opennlp-tools-1.5.0.jar POSTagger modelsen-pos-maxent.bin < Text.txt
Он дает вывод POSTagging ввода в тексте.txt
Loading POS Tagger model ... done (4.009s)
My_PRP$ name_NN is_VBZ Shabab_NNP i_FW am_VBP 22_CD years_NNS old._.
Average: 66.7 sent/s
Total: 1 sent
Runtime: 0.015s
надеюсь, он установлен правильно?
теперь, как мне сделать это POStagging изнутри приложения java? Я добавил openNLPtools, jwnl, maxent jar в проект, но как вызвать POStagging?
3 ответов
вот некоторые (старые) примеры кода, которые я собрал вместе, с модернизированным кодом:
package opennlp;
import opennlp.tools.cmdline.PerformanceMonitor;
import opennlp.tools.cmdline.postag.POSModelLoader;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
import opennlp.tools.util.ObjectStream;
import opennlp.tools.util.PlainTextByLineStream;
import java.io.File;
import java.io.IOException;
import java.io.StringReader;
public class OpenNlpTest {
public static void main(String[] args) throws IOException {
POSModel model = new POSModelLoader().load(new File("en-pos-maxent.bin"));
PerformanceMonitor perfMon = new PerformanceMonitor(System.err, "sent");
POSTaggerME tagger = new POSTaggerME(model);
String input = "Can anyone help me dig through OpenNLP's horrible documentation?";
ObjectStream<String> lineStream =
new PlainTextByLineStream(new StringReader(input));
perfMon.start();
String line;
while ((line = lineStream.read()) != null) {
String whitespaceTokenizerLine[] = WhitespaceTokenizer.INSTANCE.tokenize(line);
String[] tags = tagger.tag(whitespaceTokenizerLine);
POSSample sample = new POSSample(whitespaceTokenizerLine, tags);
System.out.println(sample.toString());
perfMon.incrementCounter();
}
perfMon.stopAndPrintFinalResult();
}
}
выход:
Loading POS Tagger model ... done (2.045s)
Can_MD anyone_NN help_VB me_PRP dig_VB through_IN OpenNLP's_NNP horrible_JJ documentation?_NN
Average: 76.9 sent/s
Total: 1 sent
Runtime: 0.013s
это в основном работает из класса POSTaggerTool, включенного в состав OpenNLP. The sample.getTags() это String массив, который имеет сами типы тегов.
для этого требуется прямой доступ к файлам данных обучения, что действительно, действительно хромает.
обновленная кодовая база для этого немного отличается (и, вероятно более полезный.)
во-первых, Maven POM:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.javachannel</groupId>
<artifactId>opennlp-example</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.opennlp</groupId>
<artifactId>opennlp-tools</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>[6.8.21,)</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
и вот код, написанный как тест, поэтому расположен в ./src/test/java/org/javachannel/opennlp/example:
package org.javachannel.opennlp.example;
import opennlp.tools.cmdline.PerformanceMonitor;
import opennlp.tools.postag.POSModel;
import opennlp.tools.postag.POSSample;
import opennlp.tools.postag.POSTaggerME;
import opennlp.tools.tokenize.WhitespaceTokenizer;
import org.testng.annotations.DataProvider;
import org.testng.annotations.Test;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URL;
import java.nio.channels.Channels;
import java.nio.channels.ReadableByteChannel;
import java.util.stream.Stream;
public class POSTest {
private void download(String url, File destination) throws IOException {
URL website = new URL(url);
ReadableByteChannel rbc = Channels.newChannel(website.openStream());
FileOutputStream fos = new FileOutputStream(destination);
fos.getChannel().transferFrom(rbc, 0, Long.MAX_VALUE);
}
@DataProvider
Object[][] getCorpusData() {
return new Object[][][]{{{
"Can anyone help me dig through OpenNLP's horrible documentation?"
}}};
}
@Test(dataProvider = "getCorpusData")
public void showPOS(Object[] input) throws IOException {
File modelFile = new File("en-pos-maxent.bin");
if (!modelFile.exists()) {
System.out.println("Downloading model.");
download("http://opennlp.sourceforge.net/models-1.5/en-pos-maxent.bin", modelFile);
}
POSModel model = new POSModel(modelFile);
PerformanceMonitor perfMon = new PerformanceMonitor(System.err, "sent");
POSTaggerME tagger = new POSTaggerME(model);
perfMon.start();
Stream.of(input).map(line -> {
String whitespaceTokenizerLine[] = WhitespaceTokenizer.INSTANCE.tokenize(line.toString());
String[] tags = tagger.tag(whitespaceTokenizerLine);
POSSample sample = new POSSample(whitespaceTokenizerLine, tags);
perfMon.incrementCounter();
return sample.toString();
}).forEach(System.out::println);
perfMon.stopAndPrintFinalResult();
}
}
этот код на самом деле не тест что угодно - это дымовой тест, если что - нибудь-но он должен служить отправной точкой. Еще одна (потенциально) хорошая вещь заключается в том, что она загружает модель для вас, если у вас ее еще нет.
URL http://bulba.sdsu.edu/jeanette/thesis/PennTags.html больше не работает. Я нашел ниже на 14-м слайде в http://www.slideshare.net/gagan1667/opennlp-demo
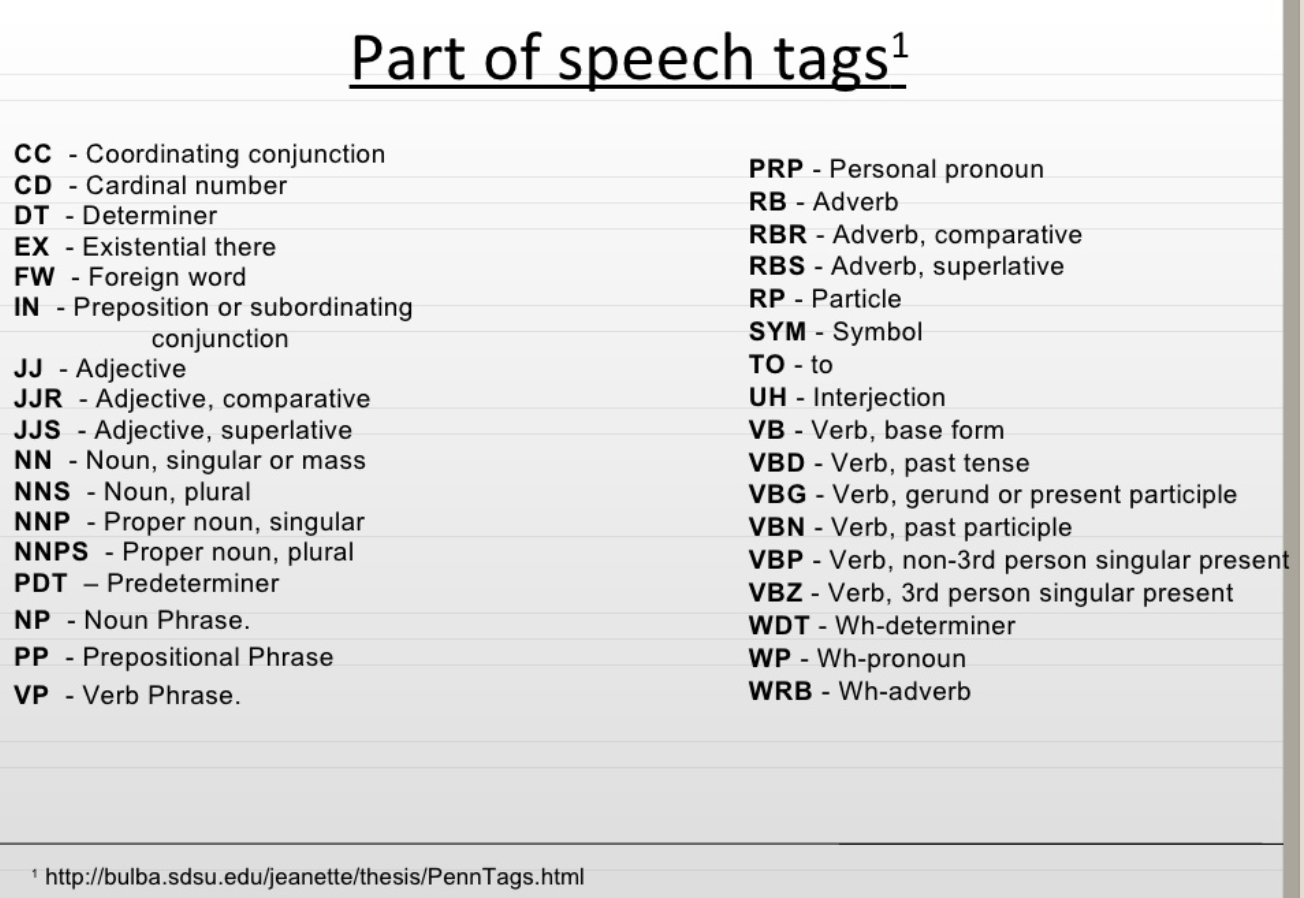
приведенный выше ответ дает возможность использовать существующие модели из OpenNLP, но если вам нужно обучить свою собственную модель, возможно, ниже может помочь:
вот подробный учебник с полным кодом:
https://dataturks.com/blog/opennlp-pos-tagger-training-java-example.php
в зависимости от домена можно создать набор данных автоматически или вручную. Создание такого набора данных вручную может быть очень болезненным, такие инструменты, как POS tagger может помочь сделать процесс намного проще.
подготовка данных в формате
обучение данные передаются в виде текстового файла, где каждая строка-один элемент данных. Каждое слово в строке должно быть помечено в формате "word_LABEL", Слово и имя метки разделены подчеркиванием"_".
anki_Brand overdrive_Brand
just_ModelName dance_ModelName 2018_ModelName
aoc_Brand 27"_ScreenSize monitor_Category
horizon_ModelName zero_ModelName dawn_ModelName
cm_Unknown 700_Unknown modem_Category
computer_Category
модель
важным классом здесь является POSModel, который содержит фактическую модель. Мы используем класс POSTaggerME для создания модели. Ниже приведен код для построения модели из файла данных обучения
public POSModel train(String filepath) {
POSModel model = null;
TrainingParameters parameters = TrainingParameters.defaultParams();
parameters.put(TrainingParameters.ITERATIONS_PARAM, "100");
try {
try (InputStream dataIn = new FileInputStream(filepath)) {
ObjectStream<String> lineStream = new PlainTextByLineStream(new InputStreamFactory() {
@Override
public InputStream createInputStream() throws IOException {
return dataIn;
}
}, StandardCharsets.UTF_8);
ObjectStream<POSSample> sampleStream = new WordTagSampleStream(lineStream);
model = POSTaggerME.train("en", sampleStream, parameters, new POSTaggerFactory());
return model;
}
}
catch (Exception e) {
e.printStackTrace();
}
return null;
}
используйте модель для тегирования.
наконец, мы можем увидеть, как модель может использоваться для тегов невидимых запросов:
public void doTagging(POSModel model, String input) {
input = input.trim();
POSTaggerME tagger = new POSTaggerME(model);
Sequence[] sequences = tagger.topKSequences(input.split(" "));
for (Sequence s : sequences) {
List<String> tags = s.getOutcomes();
System.out.println(Arrays.asList(input.split(" ")) +" =>" + tags);
}
}