Как Java HashMap обрабатывает различные объекты с одним и тем же хэш-кодом?
как я понимаю, я думаю:
- совершенно законно, чтобы два объекта имели один и тот же хэш-код.
- если два объекта равны (используя метод equals ()), то они имеют один и тот же хэш-код.
- если два объекта не равны, то они не могут иметь одинаковый хэш-код
Я прав?
Теперь, если я прав, у меня есть следующий вопрос:
The HashMap внутренне использует хэш-код объекта. Так что если два объекты могут иметь один и тот же хэш-код, тогда как может HashMap отслеживать, какой ключ он использует?
может кто-нибудь объяснить, как HashMap внутренне использует хэш-код объекта?
16 ответов
hashmap работает следующим образом (это немного упрощено, но иллюстрирует основной механизм):
он имеет несколько "ведер", которые он использует для хранения пар ключ-значение. Каждое ведро имеет уникальный номер-это то, что идентифицирует ведро. Когда вы помещаете пару ключ-значение в карту, hashmap будет смотреть на хэш-код ключа и хранить пару в ведре, идентификатором которого является хэш-код ключа. Например, хэш-код ключа 235 -> пара хранится в ведре номер 235. (Обратите внимание, что в одном ведре может храниться более одной пары ключ-значение).
когда вы ищете значение в hashmap, давая ему ключ, он сначала посмотрит на хэш-код ключа, который вы дали. Затем hashmap будет смотреть в соответствующее ведро, а затем он будет сравнивать ключ, который вы дали с ключами всех пар в ведре, сравнивая их с equals().
теперь вы можете видеть, как это очень эффективно для поиска пары ключ-значение на карте: по хэш-коду ключа hashmap сразу знает, в каком ведре искать, так что ему нужно только протестировать то, что находится в этом ведре.
глядя на вышеуказанный механизм, вы также можете увидеть, какие требования необходимы на hashCode() и equals() методы клавиш:
если два ключа совпадают (
equals()возвращаетtrueкогда вы сравниваете их), ихhashCode()метод должен возвращать то же число. Если ключи нарушают это, тогда ключи, которые равны, могут храниться в разных ведрах, и hashmap не сможет найти пары ключ-значение (потому что он будет выглядеть в одном ведре).если два ключа разные, то не имеет значения, являются ли их хэш-коды одинаковыми или нет. Они будут храниться в одном ведре, если их хэш-коды одинаковы, и в этом случае hashmap будет использовать
equals()чтобы отличить их друг от друга.
ваше третье утверждение неверно.
совершенно законно, чтобы два неравных объекта имели один и тот же хэш-код. Он используется HashMap как "фильтр первого прохода", чтобы карта могла быстро найти возможно записи с указанным ключом. Ключи с тем же хэш-кодом затем проверяются на равенство с указанным ключом.
вам не нужно требование, чтобы два неравных объекта не могли иметь один и тот же хэш-код, иначе это ограничило бы вам 232 возможные объекты. (Это также означает, что разные типы не могут даже использовать поля объекта для генерации хэш-кодов, поскольку другие классы могут генерировать тот же хэш.)
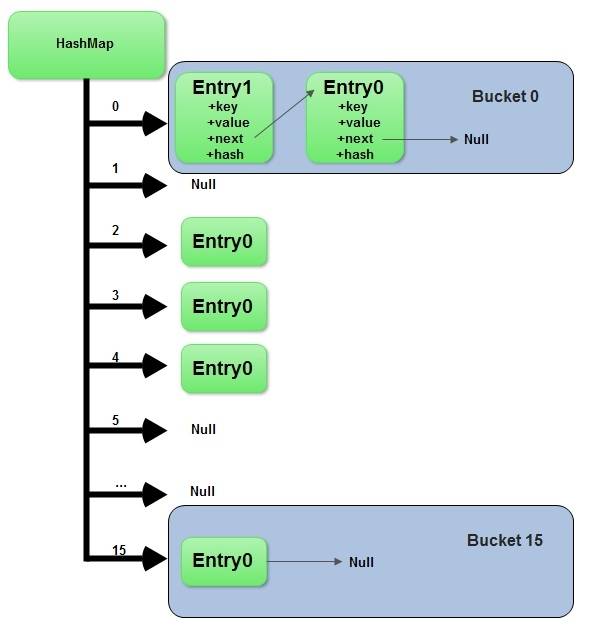
HashMap массив Entry объекты.
считают HashMap как просто массив объектов.
посмотрите, что это Object - это:
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
final int hash;
…
}
каждого Entry объект представляет собой пару ключ-значение. Поле next относится к другой Entry объект, если ведро имеет более одного Entry.
иногда может случиться, что хэш-коды для 2 разных объектов одинаковы. В данном случае два объекты будут сохранены в одном ведре и будут представлены в виде связанного списка.
Точка входа-это недавно добавленный объект. Этот объект относится к другому объекту с next поле и так далее. Последняя запись относится к null.
при создании HashMap с конструктором по умолчанию
HashMap hashMap = new HashMap();
массив создается с размером 16 и балансом нагрузки по умолчанию 0.75.
добавление новой пары ключ-значение
- рассчитать хэш-код для ключа
- вычислить позицию
hash % (arrayLength-1)где элемент должен быть помещен (сегмент) - если вы попытаетесь добавить значение с ключом, который уже был сохранен в
HashMap, затем значение перезаписывается. - в противном случае элемент добавляется в ведро.
если ведро уже имеет хотя бы один элемент, добавляется новый и помещается в первую позицию ведра. Его next поле относится к старому элемент.
удаление
- вычислить хэш-код для данного ключа
- вычислить номер ведра
hash % (arrayLength-1) - получите ссылку на первый объект записи в ведре и с помощью метода equals повторите все записи в данном ведре. В конце концов, мы найдем правильный
Entry. Если нужный элемент не найден, возвращаетnull
вы можете найти превосходную информацию на http://javarevisited.blogspot.com/2011/02/how-hashmap-works-in-java.html
Подведем Итоги:
HashMap работает по принципу хэширования
put (ключ, значение): HashMap хранит как ключ, так и объект значения как карту.Вхождение. Частности, применяется хэш-код(ключ), чтобы получить ведро. если есть столкновение, HashMap использует LinkedList для хранения объекта.
get (ключ): HashMap использует хэш-код ключевого объекта, чтобы узнать местоположение ведра, а затем вызвать ключи.метод equals () для идентификации правильного узла в LinkedList и возврата связанного объекта значения для этого ключа в Java HashMap.
вот приблизительное описание для Java 8 версия (это может немного отличаться от Java 6).
структуры данных
-
хэш-таблицы
Значение хэша рассчитывается черезhash()on key, и он решает, какое ведро хэш-таблицы использовать для данного ключа. -
список ссылок (одиночно)
Когда граф элементы в ведре небольшие, используется односвязный список. -
красно-черное дерево
Когда количество элементов в ведре велико, используется красно-черное дерево.
классы (внутри)
-
Map.Entry
Представлять одну сущность на карте, сущность ключ/значение. -
HashMap.Node
Связанный список версия узла.это может представляем:
- хэш-ведро.
Потому что у него есть свойство hash. - узел однонаправленного списка, (таким образом также руководитель linkedlist).
- хэш-ведро.
-
HashMap.TreeNode
Древовидная версия узла.
поля (внутри)
-
Node[] table
Таблица ведро, (глава связанных списков).
Если ведро не содержит элементов, то это null, таким образом, занимает только пространство ссылки. -
Set<Map.Entry> entrySetНабор сущностей. -
int size
Количество объектов. -
float loadFactor
Перед изменением размера укажите, насколько заполнена хэш-таблица. -
int threshold
Следующий размер в размер.
Формула:threshold = capacity * loadFactor
методы (внутри)
-
int hash(key)
Вычислить хэш по ключ. -
как отобразить хэш в ведро?
Используйте следующую логику:static int hashToBucket(int tableSize, int hash) { return (tableSize - 1) & hash; }
о емкости
в хэш-таблице емкость означает количество ведер, его можно получить из table.length.
Также может быть рассчитан через threshold и loadFactor, таким образом, нет необходимости определять как поле класса.
смогл получить эффективную емкость через: capacity()
операции
- найти объект по ключу.
Сначала найдите ведро по хэш-значению, затем цикл связанный список или поиск отсортированного дерева. - Добавить объект с ключом.
Сначала найдите ведро в соответствии с хэш-значением ключа.
Затем попробуйте найти значение:- если найдено, замените значение.
- в противном случае добавьте новый узел в начале связанного списка или вставьте в сортировку дерево.
- изменение размера
Когдаthresholdдостигнуто, удвоит емкость hashtable(table.length), затем выполните повторный хэш для всех элементов, чтобы перестроить таблицу.
Это может быть дорогостоящая операция.
производительность
- get & put
Сложность времениO(1), потому что:- ведро доступно через индекс массива, таким образом
O(1). - связанный список в каждом ведре небольшая длина, таким образом, может рассматриваться как
O(1). - размер дерева также ограничен, потому что расширит емкость и повторный хэш, когда количество элементов увеличится, поэтому его можно просмотреть как
O(1), а неO(log N).
- ведро доступно через индекс массива, таким образом
хэш-код определяет, какое ведро для проверки хэш-карты. Если в ведре больше одного объекта, выполняется линейный поиск, чтобы найти, какой элемент в ведре равен желаемому элементу (используя equals()) метод.
другими словами, если у вас есть идеальный хэш-код, то доступ к hashmap постоянен, вам никогда не придется перебирать ведро (технически вам также придется иметь ведра MAX_INT, реализация Java может делиться несколькими хэш-кодами в такое же ведро, котор нужно отрезать вниз на требованиях к космоса). Если у вас худший хэш-код (всегда возвращает одно и то же число), то ваш доступ к hashmap становится линейным, так как вам нужно искать каждый элемент на карте (все они находятся в одном ведре), чтобы получить то, что вы хотите.
большую часть времени хорошо написано хэш-код не идеален, но достаточно уникальный, чтобы дать вам более или менее постоянный доступ.
вы ошибаетесь в пункте три. Две записи могут иметь один и тот же хэш-код, но не быть равными. Взгляните на реализацию HashMap.получить от OpenJdk. Вы можете видеть, что он проверяет, что хэши равны и ключи равны. Если бы точка три была истинной, то не было бы необходимости проверять, что ключи равны. Хэш-код сравнивается перед ключом, потому что первый является более эффективным сравнением.
Если вы заинтересованы в изучении немного больше об этом, взгляните на статью Википедии на открыть решении столкновение, который, я считаю, является механизмом, который использует реализация OpenJdk. Этот механизм тонко отличается от подхода "ведра", который упоминается в одном из других ответов.
Это самый запутанный вопрос для многих из нас в интервью.Но это не так сложно.
мы знаем!--4-->
хранилище HashMap магазинах пара в карту.Запись (мы все знаем)
HashMap работает по алгоритму хэширования и использует метод hashCode() и equals() в методах put() и get (). (даже мы это знаем)
When we call put method by passing key-value pair, HashMap uses Key **hashCode()** with hashing to **find out the index** to store the key-value pair. (this is important)The Entry is **stored in the LinkedList**, so if there are already existing entry, it uses **equals() method to check if the passed key already exists** (even this is important)если да, он перезаписывает значение else он создает новую запись и сохраняет эту запись значения ключа.
когда мы называем метод GET передавая ключ, он снова использует hashCode (), чтобы найти индекс в массиве, а затем используйте equals() метод, чтобы найти правильную запись и вернуть его стоимость. (теперь это очевидно)
ЭТО ИЗОБРАЖЕНИЕ ПОМОЖЕТ ВАМ ПОНЯТЬ:
Изменить Сентябрь 2017: здесь мы видим, как хэш-значение используется вместе с equals после того, как мы найдем ведро.
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
}
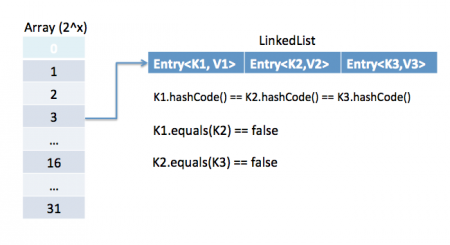
import java.util.HashMap;
public class Students {
String name;
int age;
Students(String name, int age ){
this.name = name;
this.age=age;
}
@Override
public int hashCode() {
System.out.println("__hash__");
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
System.out.println("__eq__");
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Students other = (Students) obj;
if (age != other.age)
return false;
if (name == null) {
if (other.name != null)
return false;
} else if (!name.equals(other.name))
return false;
return true;
}
public static void main(String[] args) {
Students S1 = new Students("taj",22);
Students S2 = new Students("taj",21);
System.out.println(S1.hashCode());
System.out.println(S2.hashCode());
HashMap<Students,String > HM = new HashMap<Students,String > ();
HM.put(S1, "tajinder");
HM.put(S2, "tajinder");
System.out.println(HM.size());
}
}
Output:
__ hash __
116232
__ hash __
116201
__ hash __
__ hash __
2
Итак, здесь мы видим, что если оба объекта S1 и S2 имеют разное содержимое, то мы уверены, что наш переопределенный метод хэш-кода будет генерировать другой хэш-код(116232,11601) для обоих объектов. Теперь, поскольку есть разные хэш-коды, поэтому он даже не будет беспокоиться о вызове метода EQUALS. Потому что другой хэш-код гарантирует различное содержимое в объекте.
public static void main(String[] args) {
Students S1 = new Students("taj",21);
Students S2 = new Students("taj",21);
System.out.println(S1.hashCode());
System.out.println(S2.hashCode());
HashMap<Students,String > HM = new HashMap<Students,String > ();
HM.put(S1, "tajinder");
HM.put(S2, "tajinder");
System.out.println(HM.size());
}
}
Now lets change out main method a little bit. Output after this change is
__ hash __
116201
__ hash __
116201
__ hash __
__ hash __
__ eq __
1
We can clearly see that equal method is called. Here is print statement __eq__, since we have same hashcode, then content of objects MAY or MAY not be similar. So program internally calls Equal method to verify this.
Conclusion
If hashcode is different , equal method will not get called.
if hashcode is same, equal method will get called.
Thanks , hope it helps.
хэш-карта работает по принципу хеширования
метод HashMap get(Key k) вызывает метод hashCode для ключевого объекта и применяет возвращенное hashValue к своей собственной статической хэш-функции, чтобы найти местоположение ведра(резервный массив), где ключи и значения хранятся в виде вложенного класса, называемого Entry (Map.Вступление. ) Таким образом, Вы пришли к выводу, что из предыдущей строки ключ и значение хранятся в ведре как форма объекта ввода . Поэтому думая, что только значение хранится в ведро не правильное и не произведет хорошего впечатления на интервьюера .
- всякий раз, когда мы вызываем get( Key k ) метод на объекте HashMap . Сначала он проверяет, является ли ключ null или нет . Обратите внимание, что в HashMap может быть только один нулевой ключ .
Если ключ равен null, то нулевые ключи всегда сопоставляются с хэшем 0, таким образом, индекс 0.
Если key не равен null, он вызовет hashfunction на ключевом объекте, см. строку 4 в приведенном выше методе, т. е. ключ.hashCode (), поэтому после ключа.hashCode () возвращает hashValue , строка 4 выглядит как
int hash = hash(hashValue)
и теперь он применяет возвращенное hashValue в свою собственную функцию хэширования .
мы можем задаться вопросом, почему мы снова вычисляем hashvalue, используя hash (hashValue). Ответ: он защищает от некачественных хэш-функций.
теперь final hashvalue используется для поиска местоположения ковша, в котором хранится объект записи . Объект запись в ведро такой магазинах (хэш,ключ,значение,bucketindex)
каждый объект записи представляет пару ключ-значение. Поле next относится к другому объекту записи, если в ведре более 1 записи.
иногда может случиться, что хэш-коды для 2 разных объектов одинаковы. В этом случае 2 объекта будут сохранены в одном ведре и будут представлены как LinkedList. Точка входа-это недавно добавленный объект. Этот объект относится к другому объекту со следующим полем и так один. Последняя запись относится к null. При создании HashMap по умолчанию конструктор
массив создается с размером 16 и балансом нагрузки по умолчанию 0.75.
Я не буду вдаваться в детали того, как работает HashMap, но приведу пример, чтобы мы могли вспомнить, как работает HashMap, связывая его с реальностью.
У нас есть ключ, значение ,хэш-код и ведро.
на некоторое время мы свяжем каждый из них со следующим:
- Ведро -> Общество
- HashCode - > адрес Общества (уникальный всегда)
- значение - > дом в обществе
- Ключ -> Дом адрес.
Используя Карту.вам(ключ) :
Стиви хочет попасть в дом своего друга (Жосса), который живет на вилле в VIP-обществе, пусть это будет общество JavaLovers. Адрес жосса-его SSN (который отличается для всех). Существует индекс, в котором мы узнаем название Общества, основанное на SSN. Этот индекс можно рассматривать как алгоритм для поиска хэш-кода.
- общество SSN Имя
- 92313 (Жосса) -- JavaLovers
- 13214 -- AngularJSLovers
- 98080 -- JavaLovers
- 53808 -- BiologyLovers
- этот SSN(ключ) сначала дает нам хэш-код (из таблицы индексов), который является не чем иным, как именем общества.
- теперь дома mulitple могут находиться в одном обществе, поэтому хэш-код может быть общим.
- предположим, что общество является общим для двух дома, как мы собираемся определить, в какой дом мы собираемся, да, используя ключ (SSN), который является не чем иным, как адресом дома
Используя Карту.поставить(ключ,значение)
Это находит подходящее общество для этого значения, находя хэш-код, а затем значение сохраняется.
Я надеюсь, что это поможет, и это открыто для модификаций.
в суммеризованной форме того, как hashMap работает на java?
HashMap работает по принципу хеширования, у нас есть метод put() и get() для хранения и извлечения объекта из HashMap. Когда мы передаем метод key и value to put () для хранения в HashMap, он использует метод key object hashcode () для вычисления хэш-кода, и они, применяя хэширование к этому хэш-коду, идентифицируют местоположение ведра для хранения объекта value. При извлечении используется метод Key object equals чтобы узнать правильную пару значений ключа и объект возвращаемого значения, связанный с этим ключом. HashMap использует связанный список в случае столкновения, и объект будет сохранен в следующем узле связанного списка. Также HashMap хранит оба кортежа ключ+значение в каждом узле связанного списка.
два объекта равны, означает, что они имеют одинаковый хэш-код, но не наоборот
обновление Java 8 в HashMap -
вы делаете эту операцию в ваш код -
myHashmap.put("old","key-value-pair");
myHashMap.put("very-old","old-key-value-pair");
Итак, предположим, что ваш хэш-код вернулся для обоих ключей "old" и "very-old" то же самое. То, что произойдет.
myHashMap является HashMap, и предположим, что изначально вы не указали его емкость. Таким образом, емкость по умолчанию согласно java 16 лет. Итак, как только вы инициализировали hashmap с помощью нового ключевого слова, он создал 16 ведер. теперь, когда вы выполнили первое утверждение -
myHashmap.put("old","key-value-pair");
затем хэш-код для "old" вычисляется, и потому, что хэш-код может быть очень большим целым числом, поэтому java внутренне сделала это - (хэш-это хэш-код здесь и > > > - правый сдвиг)
hash XOR hash >>> 16
таким образом, чтобы дать как больше pictureit вернет некоторый индекс, который будет от 0 до 15. Теперь ваша пара ключевых значений "old" и "key-value-pair" будет преобразован в переменную экземпляра ключа и значения объекта ввода. и тогда этот объект записи будет сохранен в ведре, или вы можете сказать, что при определенном индексе этот объект записи будет сохранен.
FYI-Entry-это класс в интерфейсе Карты-Map.Запись, с этой подписью / определением
class Entry{
final Key k;
value v;
final int hash;
Entry next;
}
теперь, когда вы выполните следующую инструкцию -
myHashmap.put("very-old","old-key-value-pair");
и "very-old" дает тот же хэш-код как "old", поэтому эта новая пара значений ключа снова отправлено в тот же индекс или в ту же корзину. Но так как это ведро не пустое, то next переменная объекта ввода используется для хранения этой новой пары значений ключа.
и это будет сохранено как связанный список для каждого объекта, который имеет тот же хэш-код, но TRIEFY_THRESHOLD указан со значением 6. поэтому после этого связанный список преобразуется в сбалансированное дерево (красно-черное дерево) с первым элементом в качестве корня.
как говорится, картина стоит 1000 слов. Я говорю: Какой код лучше, чем 1000 слов. Вот исходный код HashMap. Получить метод:
/**
* Implements Map.get and related methods
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
таким образом, становится ясно, что хэш используется для поиска "ведра", и первый элемент всегда проверяется в этом ведре. Если нет, то ... --2--> ключа используется для поиска фактического элемента в связанном списке.
посмотрим put() способ:
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
это немного сложнее, но он будет ясно, что новый элемент помещается во вкладку в позиции, рассчитанной на основе хэша:
i = (n - 1) & hash здесь i - это индекс, в который будет помещен новый элемент (или это"ведро"). n - размер tab array (массив "ведер").
во-первых, его пытаются поставить в качестве первого элемента в этом "ведре". Если элемент уже существует,добавьте новый узел в список.
это будет длинный ответ, возьмите напиток и читайте дальше ...
хеширование - это сохранение пары ключ-значение в памяти, которая может быть прочитана и записана быстрее. он хранит ключи в массиве и значения в LinkedList .
допустим, я хочу сохранить 4 пары ключевых значений -
{
“girl” => “ahhan” ,
“misused” => “Manmohan Singh” ,
“horsemints” => “guess what”,
“no” => “way”
}
поэтому для хранения ключей нам нужен массив из 4 элементов . Теперь, как сопоставить один из этих 4 Ключей с 4 индексами массива (0,1,2,3)?
Итак, java находит хэш-код отдельных ключей и сопоставляет их с определенным индексом массива . Формулы хэш-кода -
1) reverse the string.
2) keep on multiplying ascii of each character with increasing power of 31 . then add the components .
3) So hashCode() of girl would be –(ascii values of l,r,i,g are 108, 114, 105 and 103) .
e.g. girl = 108 * 31^0 + 114 * 31^1 + 105 * 31^2 + 103 * 31^3 = 3173020
гашиш и девушка !! Я знаю, о чем ты думаешь. Ваше увлечение этим диким дуэтом может заставить вас пропустить важную вещь .
почему java умножить его на 31 ?
это потому, что 31-нечетное простое в виде 2^5 – 1 . И нечетное простое уменьшает вероятность хэша Столкновение!--14-->
теперь, как этот хэш-код сопоставляется с индексом массива?
ответ:Hash Code % (Array length -1) . Так что “girl” отображается на (3173020 % 3) = 1 в нашем случае . который является вторым элементом массива .
и значение "ahhan" хранится в LinkedList, связанном с индексом массива 1 .
HashCollision - если вы попытаетесь найти hasHCode ключи “misused” и “horsemints” С помощью формулы описанные выше, вы увидите, что оба дают нам то же самое 1069518484. Whooaa !! урок усвоен -
2 равные объекты должны иметь одинаковый хэш-код, но нет никакой гарантии, если хэш-код соответствует, тогда объекты равны . Поэтому он должен хранить оба значения, соответствующие "неправильно" и "horsemints" ковш 1 (1069518484 % 3) .
теперь хэш-карта выглядит как –
Array Index 0 –
Array Index 1 - LinkedIst (“ahhan” , “Manmohan Singh” , “guess what”)
Array Index 2 – LinkedList (“way”)
Array Index 3 –
теперь, если какое-то тело пытается найти значение ключа “horsemints” , java быстро найдет его хэш-код, модуль и начнет поиск его значения в соответствующем LinkedList index 1 . Таким образом, нам не нужно искать все 4 индекса массива, что делает доступ к данным быстрее.
но , подождите , одну секунду . в этом linkedList есть 3 значения, соответствующие индексу массива 1, как он узнает, какое из них было значением для ключа "horsemints"?
на самом деле я солгал, когда сказал, что HashMap просто хранит значения в LinkedList не .
он хранит обе пары ключевых значений как запись карты. На самом деле карта выглядит так .
Array Index 0 –
Array Index 1 - LinkedIst (<”girl” => “ahhan”> , <” misused” => “Manmohan Singh”> , <”horsemints” => “guess what”>)
Array Index 2 – LinkedList (<”no” => “way”>)
Array Index 3 –
теперь вы можете видеть, проходя через linkedList, соответствующий ArrayIndex1, он фактически сравнивает ключ каждой записи этого LinkedList с "horsemints", и когда он находит его, он просто возвращает его значение .
Надеюсь, вам было весело, читая его:)