Как насчет грамматик тезисов и минимального синтаксического анализатора, чтобы распознать его?
Я пытаюсь узнать, как сделать компилятор. Для этого я много читал о контекстно-свободном языке. Но есть вещи,которые я не могу сделать сам.
поскольку это мой первый компилятор, есть некоторые практики, о которых я не знаю. Мои вопросы задаются с целью создания генератора синтаксического анализатора, а не компилятора или лексера. Некоторые вопросы могут быть очевидны..
среди моих чтений являются : Анализ Снизу Вверх, Сверху Вниз Разбор, Формальных Грамматик. Показанное изображение приходит от:Miscellanous Парсинга. Все из Стэнфордского класса CS143.
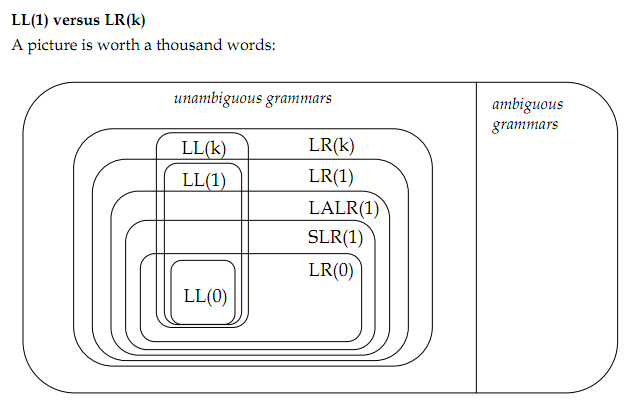
вот пункты:
0) как (неоднозначный / однозначный ) и ( левый рекурсивный / правый рекурсивный ) влияют на потребности того или иного алгоритма ? Есть ли другие способы квалифицировать грамматику ?
1) неоднозначная грамматика-это та, которая имеет несколько синтаксических разборов деревья. Но не должен ли выбор крайнего левого или правого деривации привести к единственности дерева разбора ?
[EDIT: Answered здесь ]
2.1) но все же, связана ли двусмысленность грамматики с k ? Я имею в виду, давая грамматику LR(2), она неоднозначна для парсера LR(1) и не неоднозначна для LR(2)?
[EDIT: нет, это не так, грамматика LR(2) означает, что парсеру понадобятся два токена lookahead, чтобы выбрать правильное правило для использовать. С другой стороны, неоднозначная грамматика-это та, которая, возможно, приводит к нескольким деревьям разбора. ]
2.2) таким образом, парсер LR (*), пока вы можете себе это представить, не будет иметь двусмысленной грамматики вообще, а затем может анализировать весь набор контекстных свободных языков ?
[EDIT: ответил Ира Бакстер, LR(*) менее мощный, чем GLR, в том, что он не может обрабатывать несколько деревьев синтаксического анализа. ]
3) в зависимости от предыдущих ответов, то, что следует, может быть противоречивым. Рассматривая синтаксический анализ LR, вызывают ли неоднозначные грамматики конфликт сдвига-уменьшения ? Может ли однозначная грамматика вызвать его ? Точно так же, как насчет уменьшения конфликтов?
[EDIT: вот оно, неоднозначные грамматики приводят к конфликтам shift-reduce и reduce-reduce. По contrapositive, если нет никаких конфликтов, грамматика является однозначной. ]
4) возможность разбора левой рекурсивной грамматики является преимуществом LR (k) parser над LL (k), это единственное различие между их ?
[EDIT: yes. ]
5) Давать G1:
G1 :
S -> S + S
S -> S - S
S -> a
5.1) Г1 является леворекурсивной, справа-рекурсивный, и неоднозначная, я прав ? Это грамматика LR(2)? Можно было бы сделать однозначные :
G2 :
S -> S + a
S -> S - a
S -> a
5.2) G2 все еще неоднозначен ? Нужен ли парсеру для G2 два lookaheads ? По факторизации имеем:
G3 :
S -> S V
V -> + a
V -> - a
S -> a
5.3) теперь парсер для G3 нужен только один lookahead ? Какие части счетчика для трансформации ? Требуется ли LR (1) минимальный парсер ?
5.4) G1 является левым рекурсивным, чтобы проанализировать его с помощью синтаксического анализатора LL, необходимо преобразовать его в правую рекурсивную грамматику:
G4 :
S -> a + S
S -> a - S
S -> a
затем
G5 :
S -> a V
V -> - V
V -> + V
V -> a
5.5) нужен ли G4 хотя бы парсер LL(2)? G5 только анализируется синтаксическим анализатором LL(1), G1-G5 определяет тот же язык, и этот язык ( a (+/- a)^n ). Это правда ?
5.6) для каждой грамматики G1 - G5, каков минимальный набор которому она принадлежит ?
6) наконец, поскольку многие разные грамматики могут определять один и тот же язык, как выбрать грамматику и связанный парсер ? В результате разбора важна дерево ? Каково влияние дерева синтаксического анализа ?
Я прошу слишком много, и я не жду полного ответа, в любом случае любая помощь будет очень ценится.
Thx для чтения !
1 ответов
" многие грамматики могут определять один и тот же язык, как выбрать..."?
обычно вы выбираете тот, который соответствует следующим критериям:
- концептуально так просто ,как вы можете это сделать (подразумевается: меньше, чем другие)
- отслеживает терминологию в справочном руководстве langauge, где это возможно
- наименьшее количество изгиба для удовлетворения ограничений вашего генератора анализатора
Это может сделать беспорядок ваша концептуальная простота и диаграмма различных стилей парсера показывают количество различных проблем, с которыми вы сталкиваетесь в зависимости от вашего выбора генератора. Это усугубляется тем фактом, что выбор часто делается задолго до того, как вы фактически выбираете грамматику.
один из способов минимизировать изгиб грамматики-выбрать генератор синтаксического анализатора, который обрабатывает полностью контекстные грамматики. разбор GLR это очень существенное преимущество. Я использую его в течение 15 лет и сделали десятки реальных языках с ним.