Как найти наименьшего общего предка двух узлов в двоичном дереве?
двоичное дерево здесь может не обязательно быть двоичным деревом поиска.
Структуру можно было бы принять за ... --3-->
struct node {
int data;
struct node *left;
struct node *right;
};
максимальное решение, которое я мог бы выработать с другом, было что-то в этом роде -
Считать это бинарное дерево :
двоичное дерево http://lcm.csa.iisc.ernet.in/dsa/img151.gif
{kind=link}
выходы обхода inorder- 8, 4, 9, 2, 5, 1, 6, 3, 7
и результаты обхода postorder - 8, 9, 4, 5, 2, 6, 7, 3, 1
Так, например, если мы хотим найти общего предка узлов 8 и 5, то мы составляем список всех узлов, которые находятся между 8 и 5 в обходе дерева порядка, который в этом случае оказывается [4, 9, 2]. Затем мы проверяем, какой узел в этом списке появляется последним в обходе postorder, который равен 2. Следовательно, общий предок для 8 и 5 равен 2.
сложность для этого алгоритма, я считаю, O (n) (O (n) для inorder / postorder обходы, остальные шаги снова являются O (n), поскольку они являются не более чем простыми итерациями в массивах). Но есть большая вероятность, что это неправильно. :-)
но это очень грубый подход, и я не уверен, что он сломается для какого-то случая. Есть ли другие (возможно, более оптимальное) решение этой проблемы?
30 ответов
Ник Джонсон прав, что алгоритм сложности времени O(n) - лучшее, что вы можете сделать, если у вас нет родительских указателей.) Для простой рекурсивной версии этого алгоритма см. код сообщение Киндинга который работает в O (n) времени.
но имейте в виду, что если ваши узлы имеют родительские указатели, возможен улучшенный алгоритм. Для обоих узлов, о которых идет речь, создайте список, содержащий путь от корня до узла, начав с узла и вставив родитель.
Так на 8 в вашем примере, вы получаете (показать шаги): {4}, {2, 4}, {1, 2, 4}
сделайте то же самое для другого рассматриваемого узла, в результате чего (шаги не показаны): {1, 2}
теперь сравните два списка, которые вы сделали, ища первый элемент, где список отличается, или последний элемент одного из списков, в зависимости от того, что приходит первым.
этот алгоритм требует времени O (h), где h-высота дерева. В худшем случае O (h) эквивалентно O (n), но если дерево сбалансировано, то это только O(log(n)). Для этого также требуется o(h) пространство. Улучшенная версия возможна, которая использует только постоянное пространство, с кодом, показанным в сообщение CEGRD
независимо от того, как построено дерево, если это будет операция, которую вы выполняете много раз на дереве, не меняя его между ними, есть другие алгоритмы, которые вы можете использовать, которые требуют подготовки O (n) [линейного] времени, но тогда поиск любой пары занимает только O (1) [постоянное время. Ссылки на эти алгоритмы см. На странице проблема наименьшего общего предка на Википедия. (Кредит Джейсону для первоначальной публикации этой ссылки)
начиная от root узел и перемещение вниз, если вы найдете любой узел, который имеет либо p или q как его прямой ребенок, то это LCA. (edit-это должно быть if p или q - это значение узла, верните его. В противном случае он потерпит неудачу, когда один из p или q является прямым потомком другого.)
Else, если вы найдете узел с p в его правом (или левом) поддереве и q в его левом (или правом) поддереве, то это LCA.
в исправлен код выглядит так:
treeNodePtr findLCA(treeNodePtr root, treeNodePtr p, treeNodePtr q) {
// no root no LCA.
if(!root) {
return NULL;
}
// if either p or q is the root then root is LCA.
if(root==p || root==q) {
return root;
} else {
// get LCA of p and q in left subtree.
treeNodePtr l=findLCA(root->left , p , q);
// get LCA of p and q in right subtree.
treeNodePtr r=findLCA(root->right , p, q);
// if one of p or q is in leftsubtree and other is in right
// then root it the LCA.
if(l && r) {
return root;
}
// else if l is not null, l is LCA.
else if(l) {
return l;
} else {
return r;
}
}
}
приведенный ниже код не удается, когда либо является прямым потомком другого.
treeNodePtr findLCA(treeNodePtr root, treeNodePtr p, treeNodePtr q) {
// no root no LCA.
if(!root) {
return NULL;
}
// if either p or q is direct child of root then root is LCA.
if(root->left==p || root->left==q ||
root->right ==p || root->right ==q) {
return root;
} else {
// get LCA of p and q in left subtree.
treeNodePtr l=findLCA(root->left , p , q);
// get LCA of p and q in right subtree.
treeNodePtr r=findLCA(root->right , p, q);
// if one of p or q is in leftsubtree and other is in right
// then root it the LCA.
if(l && r) {
return root;
}
// else if l is not null, l is LCA.
else if(l) {
return l;
} else {
return r;
}
}
}
вот рабочий код в JAVA
public static Node LCA(Node root, Node a, Node b) {
if (root == null) {
return null;
}
// If the root is one of a or b, then it is the LCA
if (root == a || root == b) {
return root;
}
Node left = LCA(root.left, a, b);
Node right = LCA(root.right, a, b);
// If both nodes lie in left or right then their LCA is in left or right,
// Otherwise root is their LCA
if (left != null && right != null) {
return root;
}
return (left != null) ? left : right;
}
ответы, приведенные до сих пор, используют рекурсию или сохраняют, например, путь в памяти.
оба этих подхода могут потерпеть неудачу, если у вас очень глубокое дерево.
вот мой взгляд на этот вопрос. Когда мы проверяем глубину (расстояние от корня) обоих узлов, если они равны, то мы можем безопасно двигаться вверх от обоих узлов к общему предку. Если одна из глубин больше, то мы должны двигаться вверх от более глубокого узла, оставаясь в другом один.
вот код:
findLowestCommonAncestor(v,w):
depth_vv = depth(v);
depth_ww = depth(w);
vv = v;
ww = w;
while( depth_vv != depth_ww ) {
if ( depth_vv > depth_ww ) {
vv = parent(vv);
depth_vv--;
else {
ww = parent(ww);
depth_ww--;
}
}
while( vv != ww ) {
vv = parent(vv);
ww = parent(ww);
}
return vv;
временная сложность этого алгоритма: O (n). Пространственная сложность этого алгоритма: O (1).
Что касается вычисления глубины, мы можем сначала вспомнить определение: Если v-корень, глубина(v) = 0; в противном случае глубина(v) = глубина(родитель(v)) + 1. Мы можем вычислить глубину следующим образом:
depth(v):
int d = 0;
vv = v;
while ( vv is not root ) {
vv = parent(vv);
d++;
}
return d;
Ну, это зависит от того, как структурировано ваше двоичное дерево. Предположительно, у вас есть какой - то способ найти нужный листовой узел, учитывая корень дерева-просто примените это к обоим значениям, пока выбранные ветви не разойдутся.
Если у вас нет способа найти нужный лист с учетом корня, то ваше единственное решение - как при нормальной работе, так и для поиска последнего общего узла - это поиск дерева грубой силой.
Это можно найти в:- http://goursaha.freeoda.com/DataStructure/LowestCommonAncestor.html
tree_node_type *LowestCommonAncestor(
tree_node_type *root , tree_node_type *p , tree_node_type *q)
{
tree_node_type *l , *r , *temp;
if(root==NULL)
{
return NULL;
}
if(root->left==p || root->left==q || root->right ==p || root->right ==q)
{
return root;
}
else
{
l=LowestCommonAncestor(root->left , p , q);
r=LowestCommonAncestor(root->right , p, q);
if(l!=NULL && r!=NULL)
{
return root;
}
else
{
temp = (l!=NULL)?l:r;
return temp;
}
}
}
автономный алгоритм наименее распространенных предков Тарьяна достаточно хорошо (см. также Википедия). Существует больше о проблеме (самая низкая общая проблема предка) на Википедия.
, чтобы найти общего предка двух узлов :-
- найдите данный узел Node1 в дереве с помощью двоичного поиска и сохраните все узлы, посещенные в этом процессе, в массиве, скажем A1. Время-O(logn), пространство - O (logn)
- найдите данный Node2 в дереве с помощью двоичного поиска и сохраните все узлы, посещенные в этом процессе, в массиве, скажем A2. Время-O(logn), пространство - O (logn)
- Если список A1 или список A2 пуст, то один узел не существует, поэтому нет общего предок.
- Если список A1 и список A2 непусты, то посмотрите в список, пока не найдете несоответствующий узел. Как только вы найдете такой узел, то узел до этого общего предка.
Это будет работать для бинарного дерева поиска.
Я сделал попытку с иллюстративными картинками и рабочим кодом на Java,
http://tech.bragboy.com/2010/02/least-common-ancestor-without-using.html
приведенный ниже рекурсивный алгоритм будет работать в O (log N) для сбалансированного двоичного дерева. Если любой из узлов, переданных в функцию getLCA (), совпадает с корнем, то корень будет LCA, и не будет необходимости выполнять какой-либо recussrion.
тестов. [1] оба узла n1 & n2 находятся в дереве и находятся по обе стороны от родительского узла. [2] либо узла N1 или N2 корень, ДМС-это корень. [3] только n1 или n2 в дереве LCA будет либо корневым узлом левого поддерева корня дерева, либо LCA будет корневым узлом правого поддерева корня дерева.
[4] ни n1, ни n2 нет в дереве, нет LCA. [5] оба n1 и n2 находятся на прямой линии рядом друг с другом, LCA будет либо n1, либо n2, который когда-либо закрывается до корня дерева.
//find the search node below root
bool findNode(node* root, node* search)
{
//base case
if(root == NULL)
return false;
if(root->val == search->val)
return true;
//search for the node in the left and right subtrees, if found in either return true
return (findNode(root->left, search) || findNode(root->right, search));
}
//returns the LCA, n1 & n2 are the 2 nodes for which we are
//establishing the LCA for
node* getLCA(node* root, node* n1, node* n2)
{
//base case
if(root == NULL)
return NULL;
//If 1 of the nodes is the root then the root is the LCA
//no need to recurse.
if(n1 == root || n2 == root)
return root;
//check on which side of the root n1 and n2 reside
bool n1OnLeft = findNode(root->left, n1);
bool n2OnLeft = findNode(root->left, n2);
//n1 & n2 are on different sides of the root, so root is the LCA
if(n1OnLeft != n2OnLeft)
return root;
//if both n1 & n2 are on the left of the root traverse left sub tree only
//to find the node where n1 & n2 diverge otherwise traverse right subtree
if(n1OnLeft)
return getLCA(root->left, n1, n2);
else
return getLCA(root->right, n1, n2);
}
просто спуститесь со всего дерева root пока оба заданных узла, скажем p и q, для которых предок должен быть найден, находятся в одном и том же под-дереве (то есть их значения меньше или больше, чем у корня).
это идет прямо от корня до наименее общего предка, не глядя на остальную часть дерева, так что это почти так же быстро, как он получает. Несколько способов сделать это.
Итеративный, O(1) космос!--14-->
питон
def lowestCommonAncestor(self, root, p, q):
while (root.val - p.val) * (root.val - q.val) > 0:
root = (root.left, root.right)[p.val > root.val]
return root
Java
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
while ((root.val - p.val) * (root.val - q.val) > 0)
root = p.val < root.val ? root.left : root.right;
return root;
}
в случае переполнения, я бы сделал (root.Вэл - (длинный), стр. Валь) * (корень.val - (длинный)q.val)
рекурсивные
питон
def lowestCommonAncestor(self, root, p, q):
next = p.val < root.val > q.val and root.left or \
p.val > root.val < q.val and root.right
return self.lowestCommonAncestor(next, p, q) if next else root
Java
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
return (root.val - p.val) * (root.val - q.val) < 1 ? root :
lowestCommonAncestor(p.val < root.val ? root.left : root.right, p, q);
}
в scala код:
abstract class Tree
case class Node(a:Int, left:Tree, right:Tree) extends Tree
case class Leaf(a:Int) extends Tree
def lca(tree:Tree, a:Int, b:Int):Tree = {
tree match {
case Node(ab,l,r) => {
if(ab==a || ab ==b) tree else {
val temp = lca(l,a,b);
val temp2 = lca(r,a,b);
if(temp!=null && temp2 !=null)
tree
else if (temp==null && temp2==null)
null
else if (temp==null) r else l
}
}
case Leaf(ab) => if(ab==a || ab ==b) tree else null
}
}
Node *LCA(Node *root, Node *p, Node *q) {
if (!root) return NULL;
if (root == p || root == q) return root;
Node *L = LCA(root->left, p, q);
Node *R = LCA(root->right, p, q);
if (L && R) return root; // if p and q are on both sides
return L ? L : R; // either one of p,q is on one side OR p,q is not in L&R subtrees
}
Если это полное двоичное дерево с дочерними узлами узла x как 2 * x и 2 * x+1, чем есть более быстрый способ сделать это
int get_bits(unsigned int x) {
int high = 31;
int low = 0,mid;
while(high>=low) {
mid = (high+low)/2;
if(1<<mid==x)
return mid+1;
if(1<<mid<x) {
low = mid+1;
}
else {
high = mid-1;
}
}
if(1<<mid>x)
return mid;
return mid+1;
}
unsigned int Common_Ancestor(unsigned int x,unsigned int y) {
int xbits = get_bits(x);
int ybits = get_bits(y);
int diff,kbits;
unsigned int k;
if(xbits>ybits) {
diff = xbits-ybits;
x = x >> diff;
}
else if(xbits<ybits) {
diff = ybits-xbits;
y = y >> diff;
}
k = x^y;
kbits = get_bits(k);
return y>>kbits;
}
как это работает
- получить биты, необходимые для представления x & y, который с помощью двоичного поиска является O (log (32))
- общий префикс двоичного обозначения x & y является общим предком
- в зависимости от того, что представлено большим нет битов доводится до того же бита k >> diff
- k = х^г erazes общий префикс X и y
- найти биты, представляющие оставшийся суффикс
- shift x или y битами суффикса, чтобы получить общий префикс, который является общим предком.
это работает, потому что, в основном, делят большее число на два рекурсивно, пока оба числа равны. Это число является общим предком. Деление-это фактически правильный сдвиг. Поэтому нам нужно найти общий префикс двух чисел, чтобы найти ближайший предок!--2-->
вот способ сделать это на C++. Постарались сохранить алгоритм максимально легким для понимания:
// Assuming that `BinaryNode_t` has `getData()`, `getLeft()` and `getRight()`
class LowestCommonAncestor
{
typedef char type;
// Data members which would behave as place holders
const BinaryNode_t* m_pLCA;
type m_Node1, m_Node2;
static const unsigned int TOTAL_NODES = 2;
// The core function which actually finds the LCA; It returns the number of nodes found
// At any point of time if the number of nodes found are 2, then it updates the `m_pLCA` and once updated, we have found it!
unsigned int Search (const BinaryNode_t* const pNode)
{
if(pNode == 0)
return 0;
unsigned int found = 0;
found += (pNode->getData() == m_Node1);
found += (pNode->getData() == m_Node2);
found += Search(pNode->getLeft()); // below condition can be after this as well
found += Search(pNode->getRight());
if(found == TOTAL_NODES && m_pLCA == 0)
m_pLCA = pNode; // found !
return found;
}
public:
// Interface method which will be called externally by the client
const BinaryNode_t* Search (const BinaryNode_t* const pHead,
const type node1,
const type node2)
{
// Initialize the data members of the class
m_Node1 = node1;
m_Node2 = node2;
m_pLCA = 0;
// Find the LCA, populate to `m_pLCANode` and return
(void) Search(pHead);
return m_pLCA;
}
};
Как использовать:
LowestCommonAncestor lca;
BinaryNode_t* pNode = lca.Search(pWhateverBinaryTreeNodeToBeginWith);
if(pNode != 0)
...
самый простой способ найти наименьшего общего предка-использовать следующий алгоритм:
Examine root node
if value1 and value2 are strictly less that the value at the root node
Examine left subtree
else if value1 and value2 are strictly greater that the value at the root node
Examine right subtree
else
return root
public int LCA(TreeNode root, int value 1, int value 2) {
while (root != null) {
if (value1 < root.data && value2 < root.data)
return LCA(root.left, value1, value2);
else if (value2 > root.data && value2 2 root.data)
return LCA(root.right, value1, value2);
else
return root
}
return null;
}
Я нашел решение
- взять симметричного
- принять предварительный заказ
- принять postorder
в зависимости от 3 траверсов, вы можете решить, кто является LCA. От LCA найти расстояние обоих узлов. Добавьте эти два расстояния, и вы получите ответ.
считайте это дерево 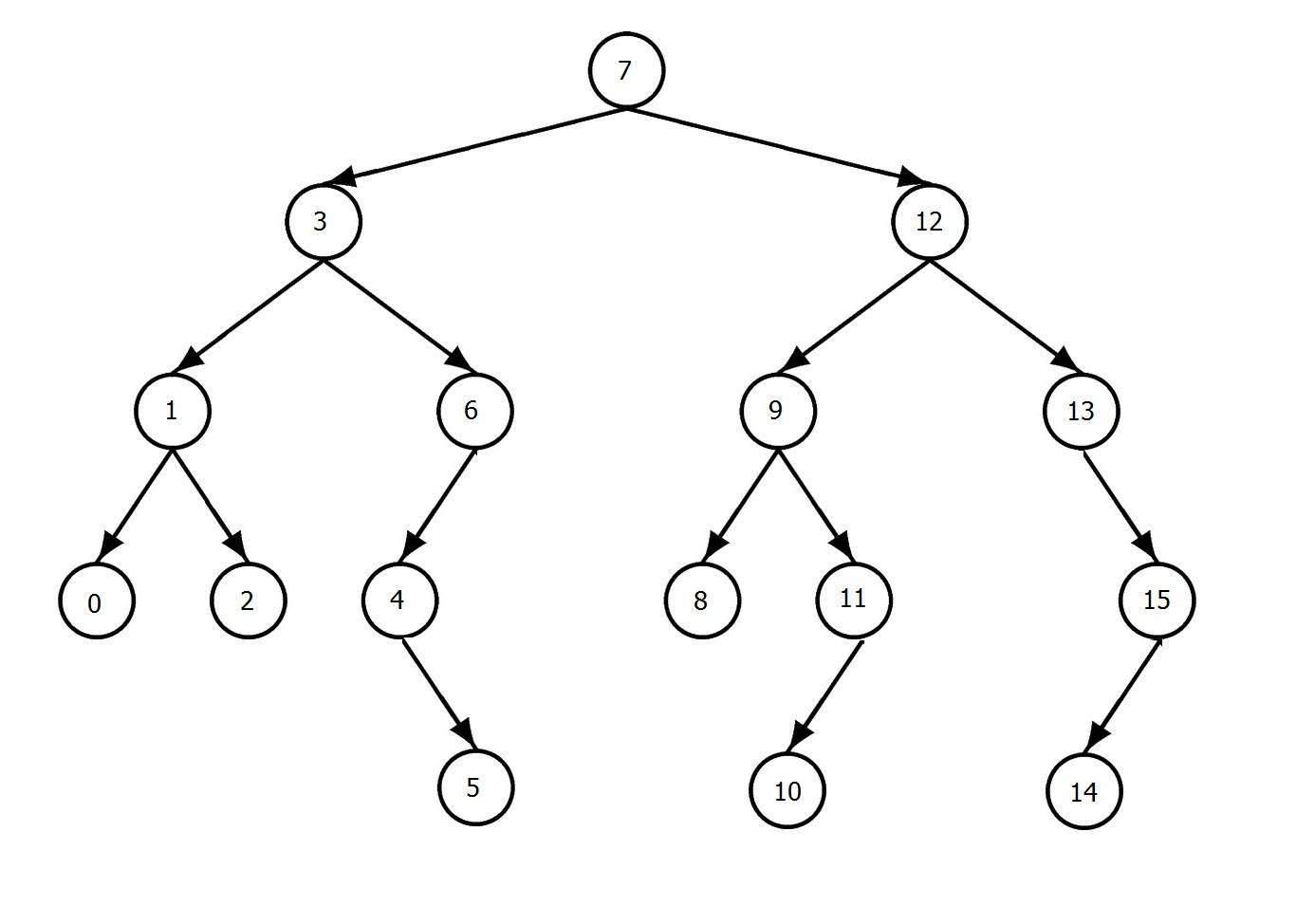
Если мы сделаем postorder и preorder traversal и найдем первого встречающегося общего предшественника и преемника, мы получим общего предка.
postorder => 0,2,1,5,4,6,3,8,10,11,9,14,15,13,12,7 предзаказ => 7,3,1,0,2,6,4,5,12,9,8,11,10,13,15,14
- например :1
наименьший общий предок 8,11
в postorder у нас есть = >9,14,15,13,12,7 после 8 & 11 в предзаказ мы =>7,3,1,0,2,6,4,5,12,9 до 8 & 11
9 первое общее число которое происходит после 8& 11 в postorder и перед 8 & 11 в preorder, следовательно 9 ответ
- например :2
наименьший общий предок 5,10
11,9,14,15,13,12,7 в почтовом заказе 7,3,1,0,2,6,4 в предзаказе
7-это первое число, которое происходит после 5,10 в postorder и до 5,10 в preorder, следовательно, 7-это ответ
вот что я думаю,
- найдите маршрут для первого узла, сохраните его на arr1.
- начните поиск маршрута для узла 2, при этом проверьте каждое значение от root до arr1.
- время, когда значение отличается , выход. Старое сопоставленное значение - LCA.
сложности : Шаг 1: O(n) , Шаг 2 =~ O(n) , total =~ O (n).
вот два подхода в c# (.net) (оба обсуждались выше) для справки:
рекурсивная версия поиска LCA в двоичном дереве (O (N) - так как посещается не более каждого узла) (основные моменты решения-LCA is (a) только узел в двоичном дереве, где оба элемента находятся по обе стороны поддеревьев (слева и справа), является LCA. (b) а также не имеет значения, какой узел присутствует с любой стороны-изначально я пытался сохранить эту информацию, и, очевидно, рекурсивная функция становится настолько запутанной. как только я понял это, он стал очень элегантным.
-
Поиск обоих узлов(O (N)) и отслеживание путей(использует дополнительное пространство - так, #1, вероятно, превосходит даже мысль, что пространство, вероятно, незначительно, если двоичное дерево хорошо сбалансировано, а затем дополнительное потребление памяти будет только в O(log (N)).
так что пути сравниваются (essentailly похож на принятый ответ-но пути исходя узел указателя нет в двоичном дереве)
только для завершения (не относится к вопросу), LCA в BST(O(log (N))
тесты
рекурсивные:
private BinaryTreeNode LeastCommonAncestorUsingRecursion(BinaryTreeNode treeNode,
int e1, int e2)
{
Debug.Assert(e1 != e2);
if(treeNode == null)
{
return null;
}
if((treeNode.Element == e1)
|| (treeNode.Element == e2))
{
//we don't care which element is present (e1 or e2), we just need to check
//if one of them is there
return treeNode;
}
var nLeft = this.LeastCommonAncestorUsingRecursion(treeNode.Left, e1, e2);
var nRight = this.LeastCommonAncestorUsingRecursion(treeNode.Right, e1, e2);
if(nLeft != null && nRight != null)
{
//note that this condition will be true only at least common ancestor
return treeNode;
}
else if(nLeft != null)
{
return nLeft;
}
else if(nRight != null)
{
return nRight;
}
return null;
}
где выше частная рекурсивная версия вызывается следующим открытым методом:
public BinaryTreeNode LeastCommonAncestorUsingRecursion(int e1, int e2)
{
var n = this.FindNode(this._root, e1);
if(null == n)
{
throw new Exception("Element not found: " + e1);
}
if (e1 == e2)
{
return n;
}
n = this.FindNode(this._root, e2);
if (null == n)
{
throw new Exception("Element not found: " + e2);
}
var node = this.LeastCommonAncestorUsingRecursion(this._root, e1, e2);
if (null == node)
{
throw new Exception(string.Format("Least common ancenstor not found for the given elements: {0},{1}", e1, e2));
}
return node;
}
решение путем отслеживания пути обоих узлов:
public BinaryTreeNode LeastCommonAncestorUsingPaths(int e1, int e2)
{
var path1 = new List<BinaryTreeNode>();
var node1 = this.FindNodeAndPath(this._root, e1, path1);
if(node1 == null)
{
throw new Exception(string.Format("Element {0} is not found", e1));
}
if(e1 == e2)
{
return node1;
}
List<BinaryTreeNode> path2 = new List<BinaryTreeNode>();
var node2 = this.FindNodeAndPath(this._root, e2, path2);
if (node1 == null)
{
throw new Exception(string.Format("Element {0} is not found", e2));
}
BinaryTreeNode lca = null;
Debug.Assert(path1[0] == this._root);
Debug.Assert(path2[0] == this._root);
int i = 0;
while((i < path1.Count)
&& (i < path2.Count)
&& (path2[i] == path1[i]))
{
lca = path1[i];
i++;
}
Debug.Assert(null != lca);
return lca;
}
где FindNodeAndPath определяется как
private BinaryTreeNode FindNodeAndPath(BinaryTreeNode node, int e, List<BinaryTreeNode> path)
{
if(node == null)
{
return null;
}
if(node.Element == e)
{
path.Add(node);
return node;
}
var n = this.FindNodeAndPath(node.Left, e, path);
if(n == null)
{
n = this.FindNodeAndPath(node.Right, e, path);
}
if(n != null)
{
path.Insert(0, node);
return n;
}
return null;
}
BST (LCA) - не связано (только для завершения Для справки)
public BinaryTreeNode BstLeastCommonAncestor(int e1, int e2)
{
//ensure both elements are there in the bst
var n1 = this.BstFind(e1, throwIfNotFound: true);
if(e1 == e2)
{
return n1;
}
this.BstFind(e2, throwIfNotFound: true);
BinaryTreeNode leastCommonAcncestor = this._root;
var iterativeNode = this._root;
while(iterativeNode != null)
{
if((iterativeNode.Element > e1 ) && (iterativeNode.Element > e2))
{
iterativeNode = iterativeNode.Left;
}
else if((iterativeNode.Element < e1) && (iterativeNode.Element < e2))
{
iterativeNode = iterativeNode.Right;
}
else
{
//i.e; either iterative node is equal to e1 or e2 or in between e1 and e2
return iterativeNode;
}
}
//control will never come here
return leastCommonAcncestor;
}
Тесты
[TestMethod]
public void LeastCommonAncestorTests()
{
int[] a = { 13, 2, 18, 1, 5, 17, 20, 3, 6, 16, 21, 4, 14, 15, 25, 22, 24 };
int[] b = { 13, 13, 13, 2, 13, 18, 13, 5, 13, 18, 13, 13, 14, 18, 25, 22};
BinarySearchTree bst = new BinarySearchTree();
foreach (int e in a)
{
bst.Add(e);
bst.Delete(e);
bst.Add(e);
}
for(int i = 0; i < b.Length; i++)
{
var n = bst.BstLeastCommonAncestor(a[i], a[i + 1]);
Assert.IsTrue(n.Element == b[i]);
var n1 = bst.LeastCommonAncestorUsingPaths(a[i], a[i + 1]);
Assert.IsTrue(n1.Element == b[i]);
Assert.IsTrue(n == n1);
var n2 = bst.LeastCommonAncestorUsingRecursion(a[i], a[i + 1]);
Assert.IsTrue(n2.Element == b[i]);
Assert.IsTrue(n2 == n1);
Assert.IsTrue(n2 == n);
}
}
Если кто-то интересуется псевдо-кодом(для университетских домашних работ), вот один.
GETLCA(BINARYTREE BT, NODE A, NODE B)
IF Root==NIL
return NIL
ENDIF
IF Root==A OR root==B
return Root
ENDIF
Left = GETLCA (Root.Left, A, B)
Right = GETLCA (Root.Right, A, B)
IF Left! = NIL AND Right! = NIL
return root
ELSEIF Left! = NIL
Return Left
ELSE
Return Right
ENDIF
хотя на это уже был дан ответ, Это мой подход к этой проблеме с использованием языка программирования C. Хотя код показывает двоичное дерево поиска (Что касается insert ()), но алгоритм работает и для двоичного дерева. Идея состоит в том, чтобы пройти по всем узлам, которые лежат от узла A до узла B в обходе inorder, искать индексы для них в обходе post order. Узел с максимальным индексом в обходе post order является самым низким общим предком.
этот является рабочим кодом C для реализации функции поиска наименьшего общего предка в двоичном дереве. Я предоставляю все функции полезности и т. д. также, но перейти к CommonAncestor () для быстрого понимания.
#include <stdio.h>
#include <malloc.h>
#include <stdlib.h>
#include <math.h>
static inline int min (int a, int b)
{
return ((a < b) ? a : b);
}
static inline int max (int a, int b)
{
return ((a > b) ? a : b);
}
typedef struct node_ {
int value;
struct node_ * left;
struct node_ * right;
} node;
#define MAX 12
int IN_ORDER[MAX] = {0};
int POST_ORDER[MAX] = {0};
createNode(int value)
{
node * temp_node = (node *)malloc(sizeof(node));
temp_node->left = temp_node->right = NULL;
temp_node->value = value;
return temp_node;
}
node *
insert(node * root, int value)
{
if (!root) {
return createNode(value);
}
if (root->value > value) {
root->left = insert(root->left, value);
} else {
root->right = insert(root->right, value);
}
return root;
}
/* Builds inorder traversal path in the IN array */
void
inorder(node * root, int * IN)
{
static int i = 0;
if (!root) return;
inorder(root->left, IN);
IN[i] = root->value;
i++;
inorder(root->right, IN);
}
/* Builds post traversal path in the POST array */
void
postorder (node * root, int * POST)
{
static int i = 0;
if (!root) return;
postorder(root->left, POST);
postorder(root->right, POST);
POST[i] = root->value;
i++;
}
int
findIndex(int * A, int value)
{
int i = 0;
for(i = 0; i< MAX; i++) {
if(A[i] == value) return i;
}
}
int
CommonAncestor(int val1, int val2)
{
int in_val1, in_val2;
int post_val1, post_val2;
int j=0, i = 0; int max_index = -1;
in_val1 = findIndex(IN_ORDER, val1);
in_val2 = findIndex(IN_ORDER, val2);
post_val1 = findIndex(POST_ORDER, val1);
post_val2 = findIndex(POST_ORDER, val2);
for (i = min(in_val1, in_val2); i<= max(in_val1, in_val2); i++) {
for(j = 0; j < MAX; j++) {
if (IN_ORDER[i] == POST_ORDER[j]) {
if (j > max_index) {
max_index = j;
}
}
}
}
printf("\ncommon ancestor of %d and %d is %d\n", val1, val2, POST_ORDER[max_index]);
return max_index;
}
int main()
{
node * root = NULL;
/* Build a tree with following values */
//40, 20, 10, 30, 5, 15, 25, 35, 1, 80, 60, 100
root = insert(root, 40);
insert(root, 20);
insert(root, 10);
insert(root, 30);
insert(root, 5);
insert(root, 15);
insert(root, 25);
insert(root, 35);
insert(root, 1);
insert(root, 80);
insert(root, 60);
insert(root, 100);
/* Get IN_ORDER traversal in the array */
inorder(root, IN_ORDER);
/* Get post order traversal in the array */
postorder(root, POST_ORDER);
CommonAncestor(1, 100);
}
может быть еще один подход. Однако он не так эффективен, как тот, который уже предложен в ответах.
создайте вектор пути для узла n1.
создайте второй вектор пути для узла n2.
вектор пути, подразумевающий, что заданные узлы из этого будут пересекаться, чтобы добраться до рассматриваемого узла.
сравните оба вектора пути. Индекс, в котором они не совпадают, возвращает узел при этом индекс-1. Это даст LCA.
минусы этого подхода:
нужно дважды пересечь дерево для вычисления векторов пути. Нужно добавить o (h) пространство для хранения векторов пути.
однако это легко реализовать и понять.
код для вычисления вектора пути:
private boolean findPathVector (TreeNode treeNode, int key, int pathVector[], int index) {
if (treeNode == null) {
return false;
}
pathVector [index++] = treeNode.getKey ();
if (treeNode.getKey () == key) {
return true;
}
if (findPathVector (treeNode.getLeftChild (), key, pathVector, index) ||
findPathVector (treeNode.getRightChild(), key, pathVector, index)) {
return true;
}
pathVector [--index] = 0;
return false;
}
попробуйте так
node * lca(node * root, int v1,int v2)
{
if(!root) {
return NULL;
}
if(root->data == v1 || root->data == v2) {
return root;}
else
{
if((v1 > root->data && v2 < root->data) || (v1 < root->data && v2 > root->data))
{
return root;
}
if(v1 < root->data && v2 < root->data)
{
root = lca(root->left, v1, v2);
}
if(v1 > root->data && v2 > root->data)
{
root = lca(root->right, v1, v2);
}
}
return root;
}
грубым образом:
- на каждый узел
- X = найти, если любой из n1, n2 существует в левой части узла
- Y = найти, если любой из n1, n2 существует в правой части узла
- если сам узел n1/ / n2, мы можем назвать его либо найденным слева или право для целей обобщения.
- если оба X и Y истинны, то узел является CA
в проблема с вышеуказанным методом заключается в том, что мы будем делать "найти" несколько раз, т. е. существует возможность многократного обхода каждого узла. Мы можем преодолеть эту проблему, если мы можем записать информацию, чтобы не обрабатывать ее снова (подумайте о динамическом программировании).
поэтому вместо того, чтобы найти каждый узел, мы ведем запись о том, что уже найдено.
Лучше Так:
- мы проверяем, если для данного узла, если left_set (значение либо n1 / n2 был найден в левом поддереве), либо right_set в глубине первым способом. (Примечание: мы даем самому корню свойство быть left_set, если это либо n1/n2)
- если и left_set и right_set, то узел является LCA.
код:
struct Node *
findCA(struct Node *root, struct Node *n1, struct Node *n2, int *set) {
int left_set, right_set;
left_set = right_set = 0;
struct Node *leftCA, *rightCA;
leftCA = rightCA = NULL;
if (root == NULL) {
return NULL;
}
if (root == n1 || root == n2) {
left_set = 1;
if (n1 == n2) {
right_set = 1;
}
}
if(!left_set) {
leftCA = findCA(root->left, n1, n2, &left_set);
if (leftCA) {
return leftCA;
}
}
if (!right_set) {
rightCA= findCA(root->right, n1, n2, &right_set);
if(rightCA) {
return rightCA;
}
}
if (left_set && right_set) {
return root;
} else {
*set = (left_set || right_set);
return NULL;
}
}
код для первого поиска ширины, чтобы убедиться, что оба узла находятся в дереве. Только тогда двигаться вперед с поиском LCA. Прокомментируйте, пожалуйста, если у вас есть какие-либо предложения по улучшению. Я думаю, что мы, вероятно, можем отметить их посещение и перезапустить поиск в определенный момент, когда мы остановились, чтобы улучшить второй узел (если он не найден посещенным)
public class searchTree {
static boolean v1=false,v2=false;
public static boolean bfs(Treenode root, int value){
if(root==null){
return false;
}
Queue<Treenode> q1 = new LinkedList<Treenode>();
q1.add(root);
while(!q1.isEmpty())
{
Treenode temp = q1.peek();
if(temp!=null) {
q1.remove();
if (temp.value == value) return true;
if (temp.left != null) q1.add(temp.left);
if (temp.right != null) q1.add(temp.right);
}
}
return false;
}
public static Treenode lcaHelper(Treenode head, int x,int y){
if(head==null){
return null;
}
if(head.value == x || head.value ==y){
if (head.value == y){
v2 = true;
return head;
}
else {
v1 = true;
return head;
}
}
Treenode left = lcaHelper(head.left, x, y);
Treenode right = lcaHelper(head.right,x,y);
if(left!=null && right!=null){
return head;
}
return (left!=null) ? left:right;
}
public static int lca(Treenode head, int h1, int h2) {
v1 = bfs(head,h1);
v2 = bfs(head,h2);
if(v1 && v2){
Treenode lca = lcaHelper(head,h1,h2);
return lca.value;
}
return -1;
}
}
вы правы, что без родительского узла решение с обходом даст вам o (n) временную сложность.
подход обхода Предположим, вы находите LCA для узла A и B, самый простой подход-сначала получить путь от корня до A, а затем получить путь от корня до B. Как только у вас есть эти два пути, вы можете легко перебрать их и найти последний общий узел, который является самым низким общим предком A и B. Б.
рекурсивное решение Другой подход - использовать рекурсию. Во-первых, мы можем получить LCA как из левого дерева, так и из правого дерева (если существует). Если любой из A или B является корневым узлом, то корень является LCA, и мы просто возвращаем корень, который является конечной точкой рекурсии. Поскольку мы продолжаем делить дерево на под-деревья, в конце концов, мы попадем в A и B.
чтобы объединить решения подзадач, если LCA (левое дерево) возвращает узел, мы знаем, что оба A и B находятся в левом дереве и возвращенном узле-конечный результат. Если LCA(left) и LCA (right) возвращают непустые узлы, это означает, что A и B находятся в левом и правом дереве соответственно. В этом случае корневой узел является самым низким общим узлом.
Регистрация Самый Низкий Общий Предок для детального анализа и решения.
некоторые решения здесь предполагают, что есть ссылка на корневой узел, некоторые предполагают, что дерево является BST.
Совместное использование моего решения с помощью hashmap без ссылки на root узел и дерево могут быть BST или non-BST:
var leftParent : Node? = left
var rightParent : Node? = right
var map = [data : Node?]()
while leftParent != nil {
map[(leftParent?.data)!] = leftParent
leftParent = leftParent?.parent
}
while rightParent != nil {
if let common = map[(rightParent?.data)!] {
return common
}
rightParent = rightParent?.parent
}
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if(root==null || root == p || root == q){
return root;
}
TreeNode left = lowestCommonAncestor(root.left,p,q);
TreeNode right = lowestCommonAncestor(root.right,p,q);
return left == null ? right : right == null ? left : root;
}
код в Php. Я предположил, что дерево является двоичным деревом массива. Поэтому вам даже не требуется дерево для вычисления LCA. вход: индекс двух узлов выход: индекс LCA
<?php
global $Ps;
function parents($l,$Ps)
{
if($l % 2 ==0)
$p = ($l-2)/2;
else
$p = ($l-1)/2;
array_push($Ps,$p);
if($p !=0)
parents($p,$Ps);
return $Ps;
}
function lca($n,$m)
{
$LCA = 0;
$arr1 = array();
$arr2 = array();
unset($Ps);
$Ps = array_fill(0,1,0);
$arr1 = parents($n,$arr1);
unset($Ps);
$Ps = array_fill(0,1,0);
$arr2 = parents($m,$arr2);
if(count($arr1) > count($arr2))
$limit = count($arr2);
else
$limit = count($arr1);
for($i =0;$i<$limit;$i++)
{
if($arr1[$i] == $arr2[$i])
{
$LCA = $arr1[$i];
break;
}
}
return $LCA;//this is the index of the element in the tree
}
var_dump(lca(5,6));
?>
скажите мне, есть ли какие-либо недостатки.