Как обнаружить цикл в связанном списке?
скажем, у вас есть связанная структура списка в Java. Он состоит из узлов:
class Node {
Node next;
// some user data
}
и каждый узел указывает на следующий узел, за исключением последнего узла, который имеет null для next. Допустим, существует вероятность того, что список может содержать цикл, т. е. конечный узел вместо null имеет ссылку на один из узлов в списке, который был перед ним.
каков наилучший способ написания
boolean hasLoop(Node first)
вернет true если данное Узел является первым из списка с циклом, и false иначе? Как вы могли написать так, чтобы это заняло постоянное пространство и разумное количество времени?
вот изображение того, как выглядит список с циклом:
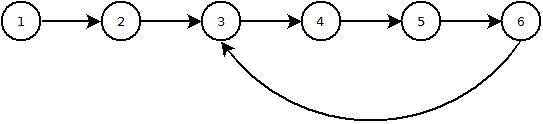
23 ответов
вы можете использовать алгоритм поиска циклов Флойда, также известный как черепаха и заяц алгоритм.
Идея в том, чтобы иметь две ссылки на список и переместить их в разной скоростью. Двигайтесь вперед на 1 узел, а другой 2 узлы.
- если связанный список имеет цикл, то они Уилл!--10-->наверняка удовлетворить.
- Else либо
пара ссылки(или их
next) станетnull.
функция Java, реализующая алгоритм:
boolean hasLoop(Node first) {
if(first == null) // list does not exist..so no loop either
return false;
Node slow, fast; // create two references.
slow = fast = first; // make both refer to the start of the list
while(true) {
slow = slow.next; // 1 hop
if(fast.next != null)
fast = fast.next.next; // 2 hops
else
return false; // next node null => no loop
if(slow == null || fast == null) // if either hits null..no loop
return false;
if(slow == fast) // if the two ever meet...we must have a loop
return true;
}
}
вот уточнение быстрого / медленного решения, которое правильно обрабатывает списки нечетной длины и улучшает ясность.
boolean hasLoop(Node first) {
Node slow = first;
Node fast = first;
while(fast != null && fast.next != null) {
slow = slow.next; // 1 hop
fast = fast.next.next; // 2 hops
if(slow == fast) // fast caught up to slow, so there is a loop
return true;
}
return false; // fast reached null, so the list terminates
}
альтернативное решение для черепахи и кролика, не совсем так приятно, как я временно меняю список:
идея состоит в том, чтобы ходить по списку, и обратить его, как вы идете. Затем, когда вы впервые достигнете узла, который уже был посещен, его следующий указатель будет указывать "назад", заставляя итерацию двигаться к first снова, где он заканчивается.
Node prev = null;
Node cur = first;
while (cur != null) {
Node next = cur.next;
cur.next = prev;
prev = cur;
cur = next;
}
boolean hasCycle = prev == first && first != null && first.next != null;
// reconstruct the list
cur = prev;
prev = null;
while (cur != null) {
Node next = cur.next;
cur.next = prev;
prev = cur;
cur = next;
}
return hasCycle;
тестовый код:
static void assertSameOrder(Node[] nodes) {
for (int i = 0; i < nodes.length - 1; i++) {
assert nodes[i].next == nodes[i + 1];
}
}
public static void main(String[] args) {
Node[] nodes = new Node[100];
for (int i = 0; i < nodes.length; i++) {
nodes[i] = new Node();
}
for (int i = 0; i < nodes.length - 1; i++) {
nodes[i].next = nodes[i + 1];
}
Node first = nodes[0];
Node max = nodes[nodes.length - 1];
max.next = null;
assert !hasCycle(first);
assertSameOrder(nodes);
max.next = first;
assert hasCycle(first);
assertSameOrder(nodes);
max.next = max;
assert hasCycle(first);
assertSameOrder(nodes);
max.next = nodes[50];
assert hasCycle(first);
assertSameOrder(nodes);
}
лучше, чем алгоритм Флойда
Ричард Брент описал алгоритм обнаружения альтернативного цикла, что очень похоже на зайца и черепаху [цикл Флойда], за исключением того, что медленный узел здесь не перемещается, но позже "телепортируется" в положение быстрого узла с фиксированными интервалами.
описание доступно здесь:http://www.siafoo.net/algorithm/11 Брент утверждает, что его алгоритм на 24-36% быстрее, чем алгоритм цикла Флойда. O(n) временная сложность, O (1) пространственная сложность.
public static boolean hasLoop(Node root){
if(root == null) return false;
Node slow = root, fast = root;
int taken = 0, limit = 2;
while (fast.next != null) {
fast = fast.next;
taken++;
if(slow == fast) return true;
if(taken == limit){
taken = 0;
limit <<= 1; // equivalent to limit *= 2;
slow = fast; // teleporting the turtle (to the hare's position)
}
}
return false;
}
посмотри алгоритм rho Полларда. Это не совсем та же проблема, но, возможно, вы поймете логику из нее и примените ее для связанных списков.
(Если вы ленивы, вы можете просто проверить обнаружение цикла -- проверьте часть о черепахе и зайце.)
для этого требуется только линейное время, и 2 дополнительных указателей.
В Java:
boolean hasLoop( Node first ) {
if ( first == null ) return false;
Node turtle = first;
Node hare = first;
while ( hare.next != null && hare.next.next != null ) {
turtle = turtle.next;
hare = hare.next.next;
if ( turtle == hare ) return true;
}
return false;
}
(большинство решения не проверяйте для обоих next и next.next для значения null. Кроме того, поскольку черепаха всегда позади, вам не нужно проверять ее на нуль-заяц уже это сделал.)
В unicornaddict имеет хороший алгоритм выше, но, к сожалению, он содержит ошибку для непересекающихся списков нечетной длины >= 3. Проблема в том, что fast может "застрять" непосредственно перед концом списка, slow догоняет его, и цикл (ошибочно) обнаружен.
вот исправленный алгоритм.
static boolean hasLoop(Node first) {
if(first == null) // list does not exist..so no loop either.
return false;
Node slow, fast; // create two references.
slow = fast = first; // make both refer to the start of the list.
while(true) {
slow = slow.next; // 1 hop.
if(fast.next == null)
fast = null;
else
fast = fast.next.next; // 2 hops.
if(fast == null) // if fast hits null..no loop.
return false;
if(slow == fast) // if the two ever meet...we must have a loop.
return true;
}
}
следующее Может быть не лучшим методом-Это O (n^2). Однако он должен служить для выполнения работы (в конечном итоге).
count_of_elements_so_far = 0;
for (each element in linked list)
{
search for current element in first <count_of_elements_so_far>
if found, then you have a loop
else,count_of_elements_so_far++;
}
алгоритм
public static boolean hasCycle (LinkedList<Node> list)
{
HashSet<Node> visited = new HashSet<Node>();
for (Node n : list)
{
visited.add(n);
if (visited.contains(n.next))
{
return true;
}
}
return false;
}
сложности
Time ~ O(n)
Space ~ O(n)
public boolean hasLoop(Node start){
TreeSet<Node> set = new TreeSet<Node>();
Node lookingAt = start;
while (lookingAt.peek() != null){
lookingAt = lookingAt.next;
if (set.contains(lookingAt){
return false;
} else {
set.put(lookingAt);
}
return true;
}
// Inside our Node class:
public Node peek(){
return this.next;
}
простите мне мое невежество (я все еще довольно новичок в Java и программировании), но почему бы не работать выше?
Я думаю, что это не решает проблему постоянного пространства... но он, по крайней мере, попадает туда в разумное время, верно? Он займет пространство связанный список, плюс пространство наборов из n элементов (где n-количество элементов в связанном списке, или количество элементов, пока не достигнет петли). И для времени, наихудший анализ, я думаю, предложил бы O(nlog (n)). Sortedset look-ups for contains ()-log(n) (проверьте javadoc, но я уверен, что базовая структура TreeSet-TreeMap, которая, в свою очередь, является красно-черным деревом), и в худшем случае (без циклов или цикла в самом конце) ей придется делать N поисков.
если нам разрешено вставлять класс Node, Я бы решил проблему, как я ее реализовал ниже. hasLoop() работает в O (n) времени и занимает только пространство counter. Кажется ли это подходящим решением? Или есть способ сделать это без вложения Node? (Очевидно, в реальной реализации было бы больше методов, таких как RemoveNode(Node n), etc.)
public class LinkedNodeList {
Node first;
Int count;
LinkedNodeList(){
first = null;
count = 0;
}
LinkedNodeList(Node n){
if (n.next != null){
throw new error("must start with single node!");
} else {
first = n;
count = 1;
}
}
public void addNode(Node n){
Node lookingAt = first;
while(lookingAt.next != null){
lookingAt = lookingAt.next;
}
lookingAt.next = n;
count++;
}
public boolean hasLoop(){
int counter = 0;
Node lookingAt = first;
while(lookingAt.next != null){
counter++;
if (count < counter){
return false;
} else {
lookingAt = lookingAt.next;
}
}
return true;
}
private class Node{
Node next;
....
}
}
вы даже можете сделать это за постоянное O (1) Время (хотя это будет не очень быстро или эффективно): существует ограниченное количество узлов, которые может содержать память вашего компьютера, скажем, N записей. Если вы пересекаете более N записей, то у вас есть цикл.
// To detect whether a circular loop exists in a linked list
public boolean findCircularLoop() {
Node slower, faster;
slower = head;
faster = head.next; // start faster one node ahead
while (true) {
// if the faster pointer encounters a NULL element
if (faster == null || faster.next == null)
return false;
// if faster pointer ever equals slower or faster's next
// pointer is ever equal to slower then it's a circular list
else if (slower == faster || slower == faster.next)
return true;
else {
// advance the pointers
slower = slower.next;
faster = faster.next.next;
}
}
}
Я не вижу никакого способа сделать это фиксированным количеством времени или пространства, оба будут увеличиваться с размером списка.
Я бы использовал IdentityHashMap (учитывая, что еще нет IdentityHashSet) и сохранить каждый узел на карте. Перед узлом хранится вы называете containsKey на нем. Если узел уже существует у вас цикл.
ItentityHashMap использует == вместо .равняется так, что вы проверяете, где объект находится в памяти, а чем если бы в нем было то же самое содержимое.
Я мог бы ужасно опоздать и новый, чтобы справиться с этой нитью. Но все же ... .
почему адрес узла и" следующий " узел не могут быть сохранены в таблице
Если бы мы могли табулировать таким образом
node present: (present node addr) (next node address)
node 1: addr1: 0x100 addr2: 0x200 ( no present node address till this point had 0x200)
node 2: addr2: 0x200 addr3: 0x300 ( no present node address till this point had 0x300)
node 3: addr3: 0x300 addr4: 0x400 ( no present node address till this point had 0x400)
node 4: addr4: 0x400 addr5: 0x500 ( no present node address till this point had 0x500)
node 5: addr5: 0x500 addr6: 0x600 ( no present node address till this point had 0x600)
node 6: addr6: 0x600 addr4: 0x400 ( ONE present node address till this point had 0x400)
следовательно, образуется цикл.
вот мой runnable код.
то, что я сделал, это почитать связанный список, используя три временных узла (сложность пространства O(1)), которые отслеживают ссылки.
интересный факт об этом заключается в том, чтобы помочь обнаружить цикл в связанном списке, потому что, когда вы идете вперед, вы не ожидаете вернуться к начальной точке (корневому узлу), и один из временных узлов должен перейти к нулю, если у вас нет цикла, который означает, что он указывает на корневой узел.
временная сложность этого алгоритма составляет O(n) и сложность пространства O(1).
вот узел класса для связанного списка:
public class LinkedNode{
public LinkedNode next;
}
вот основной код с простым тестовым случаем из трех узлов, который последний узел указывает на второй узел:
public static boolean checkLoopInLinkedList(LinkedNode root){
if (root == null || root.next == null) return false;
LinkedNode current1 = root, current2 = root.next, current3 = root.next.next;
root.next = null;
current2.next = current1;
while(current3 != null){
if(current3 == root) return true;
current1 = current2;
current2 = current3;
current3 = current3.next;
current2.next = current1;
}
return false;
}
вот простой тестовый случай из трех узлов, последний узел, указывающий на второй узел:
public class questions{
public static void main(String [] args){
LinkedNode n1 = new LinkedNode();
LinkedNode n2 = new LinkedNode();
LinkedNode n3 = new LinkedNode();
n1.next = n2;
n2.next = n3;
n3.next = n2;
System.out.print(checkLoopInLinkedList(n1));
}
}
этот код оптимизирован и будет давать результат быстрее, чем с выбранным в качестве лучшего ответа.Этот код избавляет от очень долгого процесса преследования указателя прямого и обратного узлов, который произойдет в следующем случае, если мы будем следовать методу "лучший ответ".Посмотрите на сухую линию следующего, и вы поймете, что я пытаюсь сказать.Затем посмотрите на проблему через данный метод ниже и измерьте нет. шагов, чтобы найти ответ.
1->2->9->3 ^--------^
вот код:
boolean loop(node *head)
{
node *back=head;
node *front=head;
while(front && front->next)
{
front=front->next->next;
if(back==front)
return true;
else
back=back->next;
}
return false
}
boolean hasCycle(Node head) {
boolean dec = false;
Node first = head;
Node sec = head;
while(first != null && sec != null)
{
first = first.next;
sec = sec.next.next;
if(first == sec )
{
dec = true;
break;
}
}
return dec;
}
используйте вышеуказанную функцию для обнаружения цикла в linkedlist в java.
обнаружение цикла в связанном списке может быть сделано одним из самых простых способов, что приводит к сложности O(N).
по мере прохождения списка, начиная с head, создайте отсортированный список адресов. Когда вы вставляете новый адрес, проверьте, есть ли адрес уже в отсортированном списке, который принимает сложность O(logN).
вы можете использовать алгоритм черепахи Флойда, как предложено в приведенных выше ответах.
этот алгоритм может проверить, имеет ли односвязный список замкнутый цикл. Это может быть достигнуто путем итерации списка с двумя указателями, которые будут двигаться с разной скоростью. Таким образом, если есть цикл, два указателя встретятся в какой-то момент в будущем.
пожалуйста, не стесняйтесь проверить мои блоге в структуре данных связанных списков, где я также включил код фрагмент с реализацией вышеупомянутого алгоритма на языке Java.
с уважением,
Андреас (@xnorcode)
вот решение для обнаружения цикла.
public boolean hasCycle(ListNode head) {
ListNode slow =head;
ListNode fast =head;
while(fast!=null && fast.next!=null){
slow = slow.next; // slow pointer only one hop
fast = fast.next.next; // fast pointer two hops
if(slow == fast) return true; // retrun true if fast meet slow pointer
}
return false; // return false if fast pointer stop at end
}
этот подход имеет накладные расходы на пространство, но более простую реализацию:
цикл может быть идентифицирован путем хранения узлов на карте. И перед тем, как положить узел; проверьте, если узел уже существует. Если узел уже существует на карте, это означает, что связанный список имеет цикл.
public boolean loopDetector(Node<E> first) {
Node<E> t = first;
Map<Node<E>, Node<E>> map = new IdentityHashMap<Node<E>, Node<E>>();
while (t != null) {
if (map.containsKey(t)) {
System.out.println(" duplicate Node is --" + t
+ " having value :" + t.data);
return true;
} else {
map.put(t, t);
}
t = t.next;
}
return false;
}
вот мое решение в java
boolean detectLoop(Node head){
Node fastRunner = head;
Node slowRunner = head;
while(fastRunner != null && slowRunner !=null && fastRunner.next != null){
fastRunner = fastRunner.next.next;
slowRunner = slowRunner.next;
if(fastRunner == slowRunner){
return true;
}
}
return false;
}
public boolean isCircular() {
if (head == null)
return false;
Node temp1 = head;
Node temp2 = head;
try {
while (temp2.next != null) {
temp2 = temp2.next.next.next;
temp1 = temp1.next;
if (temp1 == temp2 || temp1 == temp2.next)
return true;
}
} catch (NullPointerException ex) {
return false;
}
return false;
}