Как перевести простой логический оператор в SQL?
у меня есть следующая таблица базы данных с информацией о людях, болезнях и лекарствах:
PERSON_T DISEASE_T DRUG_T
========= ========== ========
PERSON_ID DISEASE_ID DRUG_ID
GENDER PERSON_ID PERSON_ID
NAME DISEASE_START_DATE DRUG_START_DATE
DISEASE_END_DATE DRUG_END_DATE
из этих таблиц я запускаю некоторые статистические данные о том, какие люди принимали какие наркотики и какие болезни. Из этого я могу понять, какие шаблоны интересны для мне нужно копнуть глубже. Например, ниже приведен упрощенный пример логического шаблона, который я мог бы найти для болезни 52:
( (Drug 234 = false AND Drug 474 = true AND Drug 26 = false) OR
(Drug 395 = false AND Drug 791 = false AND Drug 371 = true) )
Edit: Вот еще один пример:
( (Drug 234 = true AND Drug 474 = true AND Drug 26 = false) OR
(Drug 395 = false AND Drug 791 = false AND Drug 371 = true) )
теперь я хочу преобразовать этот шаблон в sql-запрос и найти всех людей, которые соответствуют этому шаблону.
Например, я хочу найти всех людей в PERSON_T, у которых была болезнь и
((кто не принимал препарат 234 и 26 до проявления симптомов, но принимал препарат 474 до проявления симптомов) или
(кто принимал препарат 371 до проявления симптомов, но не препарат 791 и 395 до проявления симптомов))
как бы я идти о переводе этот шаблон возвращается в исходный запрос?
вот моя первая попытка, но я застрял на первом сроке:
SELECT * FROM PERSON_T, DRUG_T, DISEASE_T
WHERE DISEASE_ID = 52 AND
PERSON_T.PERSON_ID = DISEASE_T.PERSON_ID AND
PERSON_T.PERSON_ID = DRUG_T.PERSON_ID AND
(DRUG_T.DRUG_ID=234 AND (DRUG_T.DRUG_START_DATE>DISEASE_T.END_DATE || ???)
мне нужно, чтобы это работало в PostgreSql, но я предполагаю, что любой данный ответ может быть переведен из данной базы данных в PostgreSql.
ответ на комментарий
- исправлено форматирование базы данных таблицы. Спасибо.
- мне нужно иметь возможность взять произвольное логическое утверждение и перевести его в SQL. Булевы операторы, которые мы фактически создаем, намного длиннее, чем пример, который я привел. Любые новые таблицы, которые я создаю, будут в новой базе данных и должны иметь ту же схему, что и исходные таблицы. Таким образом, для конечного пользователя они могут запускать один и тот же код в новых таблицах, и он работает так же, как если бы он работал в исходных таблицах. Это требование от клиента. Я надеюсь, что смогу создать представление, которое является просто запросом к исходным таблицам. Если мы не сможем заставить это работать, я могу создайте копию таблиц и отфильтруйте данные, когда я копирую их в новую таблицу. Мы не используем нейронные сети для анализа. Мы используем наши собственные алгоритмы, которые масштабируются значительно лучше, чем нейронные сети.
- в Disease_Start_Date-это дата, когда человек получает diseaes, который, вероятно, когда симптомы начинают появляться. Disease_End_Date - это когда человек восстанавливается, что вероятно, когда симптомы исчезают.
- Drug_start_date когда человек начинает принимать наркотики. Drug_end_date-это когда человек перестает принимать наркотики.
редактировать Я добавил свой собственный ответ. Может ли кто-нибудь придумать более простой ответ?
10 ответов
для меня простое (если уродливое) решение-использовать предложения EXISTS и NOT EXISTS:
SELECT *
FROM PERSON_T INNER JOIN DISEASE_T
USING (PERSON_ID)
WHERE DISEASE_ID = 52
AND EXISTS (SELECT 1 FROM DRUG_T
WHERE DRUG_T.PERSON_ID = PERSON_T.PERSON_ID
AND DRUG_ID = 474
AND [time condition])
AND NOT EXISTS (SELECT 1 FROM DRUG_T
WHERE DRUG_T.PERSON_ID = PERSON_T.PERSON_ID
AND DRUG_ID = 234
AND [time condition])
...и так далее. В примере мы спрашиваем людей, которые принимали препарат 474, но не 234. Очевидно, что вы можете сгруппировать предложения с помощью ANDs и ORs в соответствии с тем, что вам нужно.
в сторону: я нахожу все шапки трудно читать. Обычно я использую верхний регистр для ключевых слов SQL и нижний регистр для имен таблиц и столбцов.
Я понятия не имею, как это будет работать с большими таблицами (я думаю, что это будет довольно паршиво, поскольку сравнение дат обычно довольно дорого), но вот метод, который должен работать. Это относительно многословно, но очень легко изменить для разных булевых случаев.
Пример 1:
SELECT dis.*
FROM disease_t dis
LEFT JOIN drug d1 ON d1.person_id = dis.person_id AND d1.drug_id = 234
LEFT JOIN drug d2 ON d2.person_id = dis.person_id AND d2.drug_id = 474
LEFT JOIN drug d3 ON d3.person_id = dis.person_id AND d3.drug_id = 26
LEFT JOIN drug d4 ON d4.person_id = dis.person_id AND d4.drug_id = 395
LEFT JOIN drug d5 ON d5.person_id = dis.person_id AND d5.drug_id = 791
LEFT JOIN drug d6 ON d6.person_id = dis.person_id AND d6.drug_id = 371
WHERE dis.disease_id = 52
AND (((d1.person_id IS NULL OR dis.startdate < d1.startdate) AND
(d2.person_id IS NOT NULL AND d2.startdate < dis.startdate) AND
(d3.person_id IS NULL OR dis.startdate < d3.startdate))
OR
((d4.person_id IS NULL OR dis.startdate < d4.startdate) AND
(d5.person_id IS NULL OR dis.startdate < d5.startdate) AND
(d6.person_id IS NOT NULL AND d6.startdate < dis.startdate)))
Пример 2:
SELECT dis.*
FROM disease_t dis
LEFT JOIN drug d1 ON d1.person_id = dis.person_id AND d1.drug_id = 234
LEFT JOIN drug d2 ON d2.person_id = dis.person_id AND d2.drug_id = 474
LEFT JOIN drug d3 ON d3.person_id = dis.person_id AND d3.drug_id = 26
LEFT JOIN drug d4 ON d4.person_id = dis.person_id AND d4.drug_id = 395
LEFT JOIN drug d5 ON d5.person_id = dis.person_id AND d5.drug_id = 791
LEFT JOIN drug d6 ON d6.person_id = dis.person_id AND d6.drug_id = 371
WHERE dis.disease_id = 52
AND (((d1.person_id IS NOT NULL AND d1.startdate < dis.startdate) AND
(d2.person_id IS NOT NULL AND d2.startdate < dis.startdate) AND
(d3.person_id IS NULL OR dis.startdate < d3.startdate))
or
((d4.person_id IS NULL OR dis.startdate < d4.startdate) AND
(d5.person_id IS NULL OR dis.startdate < d5.startdate) AND
(d6.person_id IS NOT NULL AND d6.startdate < dis.startdate)))
вот запрос, который обрабатывает ( (Drug 234 = true AND Drug 474 = true AND Drug 26 = false) OR (Drug 395 = false AND Drug 791 = false AND Drug 371 = true) ), Как ты выложил.
/*
-- AS DEFINED BY JOINS
-- All "person_id"'s match
-- Drug 1 is not Drug 2
-- Drug 1 is not Drug 3
-- Drug 2 is not Drug 3
-- All Drugs are optional as far as the SELECT statement is concerned (left join)
-- Drug IDs will be defined in the WHERE clause
-- All Diseases for "person_id"
-- AS DEFINED IN WHERE STATEMENT
-- Disease IS 52
-- AND ONE OF THE FOLLOWING:
-- 1) Disease started AFTER Drug 1
-- Disease started AFTER Drug 2
-- Drug 1 IS 234
-- Drug 2 IS 474
-- Drug 3 IS NOT 26 (AND NOT 234 or 474, as defined in JOINs)
-- 2) Disease started AFTER Drug 3
-- Drug 1 IS NOT 395
-- Drug 2 IS NOT 791
-- Drug 3 IS 371
*/
SELECT p.person_id, p.gender FROM person_t as p
LEFT JOIN drug_t AS dr1 ON (p.person_id = dr1.person_id)
LEFT JOIN drug_t AS dr2 ON (p.person_id = dr2.person_id AND dr1.drug_id != dr2.drug_id)
LEFT JOIN drug_t AS dr3 ON (p.person_id = dr3.person_id AND dr1.drug_id != dr3.drug_id AND dr2.drug_id != dr3.drug_id)
JOIN disease_t AS ds ON (p.person_id = ds.person_id)
WHERE ds.disease_id = 52
AND ( ( (dr1.drug_start_date < ds.disease_start_date AND dr2.drug_start_date < ds.disease_start_date)
AND (dr1.drug_id = 234 AND dr2.drug_id = 474 AND dr3.drug_id != 26)
)
OR
( (dr3.drug_start_date < ds.disease_start_date)
AND (dr1.drug_id != 395 AND dr2.drug_id != 791 AND dr3.drug_id = 371)
)
)
простите любые ошибки, но я думаю, что что-то вроде этого будет работать (в T-SQL):
SELECT col1, col2, col3...
FROM PERSON_T AS P, DRUG_T AS DR, DISEASE_T AS DI
WHERE disease_id = 52
AND P.person_id = DI.person_id
AND P.person_id = DR.person_id
AND drug_id NOT IN(234, 26)
AND drug_id = 474
AND disease_start_date < drug_start_date
UNION
SELECT col1, col2, col3...
FROM PERSON_T AS P, DRUG_T AS DR, DISEASE_T AS DI
WHERE disease_id = 52
AND P.person_id = DI.person_id
AND P.person_id = DR.person_id
AND drug_id NOT IN(791, 395)
AND drug_id = 371
AND disease_start_date < drug_start_date
теперь это не нужно делать с Союзом, но для читаемости я думал, что это было проще всего, учитывая ваши условия. Может быть, это приведет вас в правильном направлении.
SELECT per.person_id, per.name, per.gender
FROM person_t per
INNER JOIN disease_t dis
USING (person_id)
INNER JOIN drug_t drug
USING (person_id)
WHERE dis.disease_id = 52 AND drug.drug_start_date < dis.disease_start_date AND ((drug.drug_id IN (234, 474) AND drug.drug_id NOT IN (26)) OR (drug.drug_id IN (371) AND drug.drug_id NOT IN (395, 791)));
это сделает то, что вы просите. Утверждения IN в конце довольно понятны.
у меня нет тестовых данных, чтобы попробовать это, но я думаю, вы могли бы сделать что-то вроде:
SELECT *
FROM DISEASE_T D
INNER JOIN DRUG_T DR ON D.PERSON_ID = DR.PERSON_ID AND D.DRUG_ID=52
INNER JOIN PERSON_T P ON P.PERSON_ID = D.PERSON_ID
GROUP BY PERSON_ID
HAVING SUM(
CASE WHEN DRUG_ID=234 AND DRUG_START_DATE<DISEASE_START_DATE THEN -1
WHEN DRUG_ID=474 AND DRUG_START_DATE<DISEASE_START_DATE THEN 1
WHEN DRUG_ID=26 AND DRUG_START_DATE<DISEASE_START_DATE THEN -1
ELSE 0 END) = 1
OR
SUM(
CASE WHEN DRUG_ID=395 AND DRUG_START_DATE<DISEASE_START_DATE THEN -1
WHEN DRUG_ID=791 AND DRUG_START_DATE<DISEASE_START_DATE THEN -1
WHEN DRUG_ID=371 AND DRUG_START_DATE<DISEASE_START_DATE THEN 1
ELSE 0 END) = 1
случай, который я знаю, потерпит неудачу, если у вас есть несколько записей для одного и того же человека и одного и того же препарата/болезни в таблицах наркотиков/болезней. Если это так, вы также можете изменить предложение HAVING, чтобы выглядеть более похожим:
(SUM(CASE WHEN DRUG_ID=234 AND DRUG_START_DATE<DISEASE_START_DATE THEN 1 ELSE 0 END) = 0
AND SUM(CASE WHEN DRUG_ID=474 AND DRUG_START_DATE<DISEASE_START_DATE THEN 1 ELSE 0 END) > 0
AND SUM(CASE WHEN DRUG_ID=26 AND DRUG_START_DATE<DISEASE_START_DATE THEN 1 ELSE 0 END) = 0)
OR
(SUM(CASE WHEN DRUG_ID=395 AND DRUG_START_DATE<DISEASE_START_DATE THEN 1 ELSE 0 END) = 0
AND SUM(CASE WHEN DRUG_ID=791 AND DRUG_START_DATE<DISEASE_START_DATE THEN 1 ELSE 0 END) = 0
AND SUM(CASE WHEN DRUG_ID=371 AND DRUG_START_DATE<DISEASE_START_DATE THEN 1 ELSE 0 END) > 0)
Я бы, вероятно, подошел к этой проблеме с некоторого направления, подобного этому. Он довольно гибкий.
DRUG_DISEASE_CORRELATION_QUERY
===============================
DRUG_DISEASE_CORRELATION_QUERY_ID
DISEASE_ID
DESCRIPTION
(1, 52, 'What this query does.')
(2, 52, 'Add some more results.')
DRUG_DISEASE_CORRELATION_QUERY_INCLUDE_DRUG
===========================================
DRUG_DISEASE_CORRELATION_QUERY_ID
DRUG_ID
(1, 234)
(1, 474)
(2, 371)
DRUG_DISEASE_CORRELATION_QUERY_EXCLUDE_DRUG
===========================================
DRUG_DISEASE_CORRELATION_QUERY_ID
DRUG_ID
(1, 26)
(2, 395)
(2, 791)
CREATE VIEW DRUG_DISEASE_CORRELATION
AS
SELECT
p.*,
q.DRUG_DISEASE_CORRELATION_QUERY_ID
FROM
DRUG_DISEASE_CORRELATION_QUERY q
INNER JOIN DISEASE_T ds on ds.DISEASE_ID = q.DISEASE_ID
INNER JOIN PERSON_T p ON p.PERSON_ID = ds.PERSON_ID
WHERE
AND EXISTS (SELECT * FROM DRUG_T dr WHERE dr.PERSON_ID = p.PERSON_ID AND dr.DRUG_ID IN
(SELECT qid.DRUG_ID FROM DRUG_DISEASE_CORRELATION_QUERY_INCLUDE_DRUG qid WHERE
qid.DRUG_DISEASE_CORRELATION_QUERY_ID = q.DRUG_DISEASE_CORRELATION_QUERY_ID)
AND DRUG_START_DATE < ds.DISEASE_START_DATE)
AND NOT EXISTS (SELECT * FROM DRUG_T dr WHERE dr.PERSON_ID = p.PERSON_ID AND dr.DRUG_ID IN
(SELECT qed.DRUG_ID FROM DRUG_DISEASE_CORRELATION_QUERY_EXCLUDE_DRUG qed WHERE
qed.DRUG_DISEASE_CORRELATION_QUERY_ID = q.DRUG_DISEASE_CORRELATION_QUERY_ID)
AND DRUG_START_DATE < ds.DISEASE_START_DATE)
GO
SELECT * FROM DRUG_DISEASE_CORRELATION WHERE DRUG_DISEASE_CORRELATION_QUERY_ID = 1
UNION
SELECT * FROM DRUG_DISEASE_CORRELATION WHERE DRUG_DISEASE_CORRELATION_QUERY_ID = 2
Если я правильно понял, вы хотите:
- выберите этих людей
- которые были заражены одним (1) специфическим заболеванием
- , которые были обработаны с одной или более указанных препаратов
- и которые не были обработаны с одним или больше определенными другими лекарствами
Это может быть упрощено путем преобразования ваших "требований к лекарствам" во временную таблицу некоторой формы. Это позволило бы использовать любое количество "хорошие" и "плохие" наркотики для запроса. То, что у меня ниже, может быть реализовано как хранимая процедура, но если это не вариант, доступно несколько запутанных опций.
ломая вниз по ступенькам:
первый, вот как выбираются нужные пациенты. Мы будем использовать это в качестве подзапроса позже:
SELECT [PersonData]
from DISEASE_T di
inner join PERSON_T pe
on pe.Person_Id = di.Person_Id
where di.Disease_Id = [TargetDisease]
and [TimeConstraints]
второй, для каждого набора" целевых " препаратов, которые вы собрали вместе, настройте временную таблицу так (это Синтаксис SQL Server, Postgres должен иметь что-то подобное):
CREATE TABLE #DrugSet
(
Drug_Id [KeyDataType]
,Include int not null
)
заполните его одной строкой для каждого препарата, который вы рассматриваете:
- Drug_Id = препарат, который вы проверяете
- Include = 1, если человек должен был принять препарат, и 0, если они не должны были принять его
и вычислить два значения:
@GoodDrugs, количество лекарств, которые вы хотите, чтобы пациент принял
@BadDrugs, количество наркотиков вы хотите, чтобы пациент не принимал
Теперь сшейте все вышеперечисленное вместе в следующем запросе:
SELECT pe.[PersonData] -- All the desired columns from PERSON_T and elsewhere
from DRUG_T dr
-- Filter to only include "persons of interest"
inner join (select [PersonData]
from DISEASE_T di
inner join PERSON_T pe
on pe.Person_Id = di.Person_Id
where di.Disease_Id = [TargetDisease]
and [TimeConstraints]) pe
on pe.Person_Id = dr.Person_ID
-- Join with any of the drugs we are intersted in
left outer join #DrugSet ta
on ta.Drug_Id = dr.Drug_Id
group by pe.[PersonData] -- Same as in the SELECT clause
having sum(case ta.Include
when 1 then 1 -- This patient has been given a drug that we're looking to match
else 0 -- This patient has not been given this drug (catches NULLs, too)
end) = @GoodDrugs
and sum(case ta.Include
when 0 then 1 -- This patient has been given this drug that we're NOT looking to match
else 0 -- This patient has not been given this drug (catches NULLs, too)
end) = @BadDrugs
Я намеренно проигнорировал критерии времени, поскольку вы не вдавались в подробности о них, но они должны быть довольно простыми для добавления (хотя я надеюсь, что это не знаменитые последние слова). Дальнейшая оптимизация возможна, но многое зависит от данных и других возможных критериев.
вам нужно будет запустить это один раз для каждого "набора наркотиков" (то есть наборов TRUE или фальшивые наркотики, соединенные вместе), объединяя список с каждым проходом. Вероятно, вы могли бы расширить #DrugSet, чтобы учесть каждый набор лекарств, который вы проверяете, но я не хочу пытаться и код, который без каких-либо серьезных данных, чтобы проверить его.
*/
ни один из ответов не работает. Опять же, вот шаблон, который я хочу реализовать: ( (Препарат 234 = true и препарат 474 = true и наркотиков 26 = false) или (Препарат 395 = ложь и препарат 791 = ложь и препарат 371 = истина))
Я считаю, что следующий запрос будет работать для (Drug 234 = true и Drug 474 = true и Drug 26 = false). Учитывая это, довольно легко добавить вторую половину запроса.
SELECT p.person_id, p.gender FROM person_t as p
join drug_t as dr on dr.person_id = p.person_id
join disease_t as ds on ds.person_id=p.person_id
WHERE dr.drug_start_date < ds.disease_start_date AND disease_id = 52 AND dr.drug_id=234
INTERSECT
SELECT p.person_id, p.gender FROM person_t as p
join drug_t as dr on dr.person_id = p.person_id
join disease_t as ds on ds.person_id=p.person_id
WHERE dr.drug_start_date < ds.disease_start_date AND disease_id = 52 AND dr.drug_id=474
INTERSECT (
SELECT p.person_id, p.gender
FROM person_t as p
JOIN disease_t as ds on ds.person_id = p.person_id
LEFT JOIN drug_t as dr ON dr.person_id = p.person_id AND dr.drug_id = 26
WHERE disease_id = 52 AND dr.person_id is null
UNION
SELECT p.person_id, p.gender
FROM person_t as p
JOIN disease_t as ds on ds.person_id = p.person_id
JOIN drug_t as dr ON dr.person_id = p.person_id AND dr.drug_id = 26
WHERE disease_id = 52 AND dr.drug_start_date > ds.disease_start_date)
этот запрос работает, но довольно уродлив. Я также подозреваю, это будет очень медленно, как только у меня будет производственная база данных со 100 миллионами человек. Есть все, что я могу сделать, чтобы упростить/оптимизировать этот запрос?
Я попытался сломать проблему и следовать как можно логичнее.
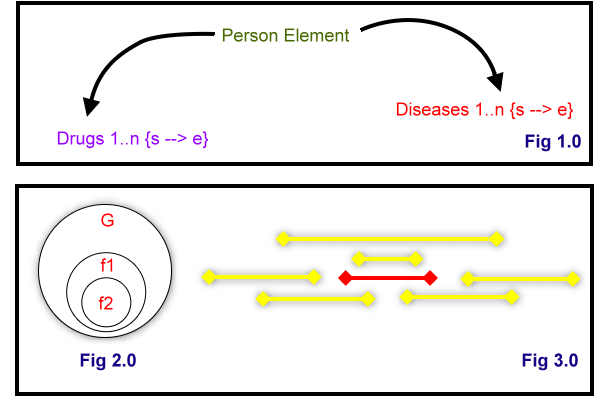
во-первых, три таблицы (Person_T, Drugs_T, Disease_T) можно представить так, как показано на рис. 1.0:
человек может иметь несколько лекарства и несколько заболевания. У каждого лекарства и болезни есть дата начала и дата окончания.
поэтому я бы сначала нормализовал три таблицы в одну таблицу (Table_dn) таким образом:
dnId | PersonId | DrugId | DiseaseId | DgSt | DgEn | DiSt | DiEn
---- -------- ------ --------- ---- ---- ---- ----
этот денормализованную таблицу можно временную таблицу, если это необходимо, независимо от Table_dn теперь содержит весь глобальный набор данных, как показано на рис. 2.0 (обозначается как G).
из моего понимания вашего описания я вижу, по существу, двухслойный фильтр.
1
этот фильтр является просто логическим набором лекарств комбинации, как вы уже заявили в своем описании вопроса. например:
(drug a = 1 & drug b = 0 & etc) OR (.....
2
этот фильтр немного сложнее, чем первый, это критерии диапазона дат. На рис. 3.0 Этот диапазон дат показан в красный. Желтый представляет даты записи, которые охватывают несколькими способами:
- перед красным периодом
- после красного периода
- между красным срок
- окончание до конца красного периода
- начиная с начала красного периода
Теперь желтая дата периоды могут быть период наркотиков или период болезни или сочетание обоих.
этот фильтр должен применяться к набору результатов, полученных из первых результатов.
конечно, в зависимости от вашего точного вопроса эти два фильтра могут потребоваться в другую сторону (e.g F2, затем f1).
псевдо-код SQL:
Select sub.*
From
(select *
from Table_dn
where [Filter 1]
) as sub
where [Filter 2]