Как проверить файл CSV перед импортом в базу данных с помощью служб SSIS?
у меня есть CSV-файл с тремя столбцами.
sno sname quantity
--- ----- --------
1 aaa 23
2 bbb null
3 ccc 34
4 ddd ddd
5 eee xxx
6 fff 87
таблица в базе данных SQL Server выглядит следующим образом/
CREATE TABLE csvtable
( sno int
, sname varchar(100)
, quantity numeric(5,2)
)
Я создал пакет служб SSIS для импорта данных csv-файла в таблицу базы данных. Я получаю ошибку во время выполнения пакета, потому что количество является строкой. Я создал другую таблицу для хранения недопустимых данных.
CREATE TABLE wrongcsvtable
( sno nvarchar(10)
, sname nvarchar(100)
, quantity nvarchar(100)
)
на csvtable, Я хотел бы сохранить следующие данные.
sno sanme quantity
--- ------ --------
1 aaa 23
3 ccc 34
6 fff 87
в wrongcsvtable, Я хотел бы сохранить следующие данные.
sno sanme quantity
--- ------ --------
2 bbb null
4 ddd ddd
5 eee xxx
может ли кто-нибудь указать мне в правильном направлении для достижения вышеупомянутого результата?
2 ответов
вот один из возможных вариантов. Вы можете достичь этого, используя Data Conversion преобразование в Data Flow Task. Следующий пример показывает, как этого можно достичь. В примере используется SSIS 2005 с базой данных SQL Server 2008.
шаг за шагом процесс:
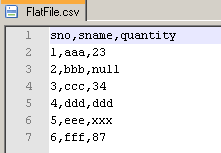
создайте файл с именем
FlatFile.CSVи заполнить его данными, как показано на скриншоте #1.в базе данных SQL, создайте две таблицы имени
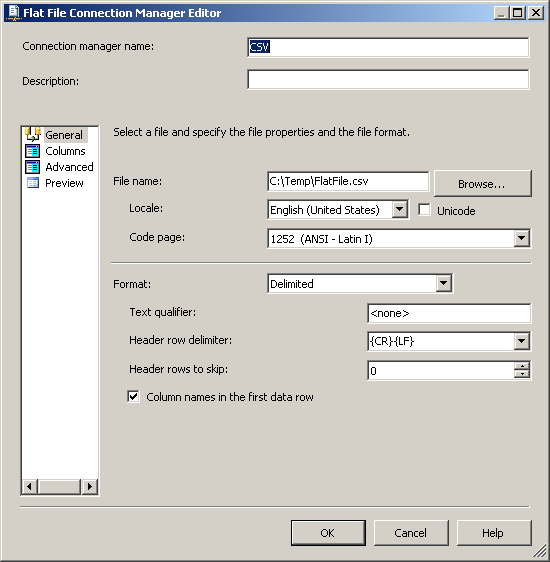
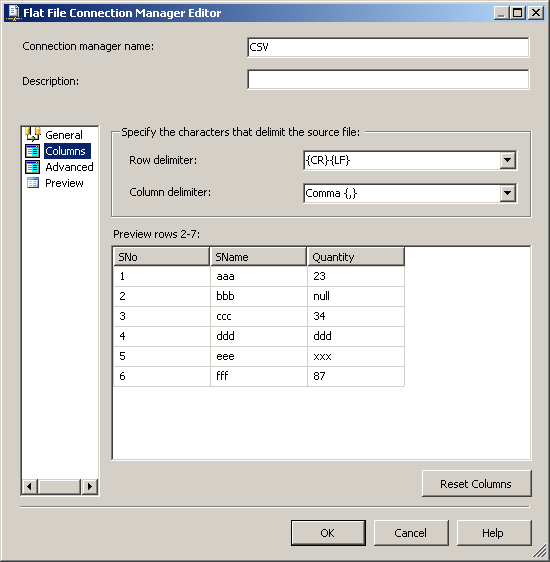
dbo.CSVCorrectиdbo.CSVWrongиспользование скриптов, предусмотренных SQL-скриптов. Поля в таблицеdbo.CSVWrongдолжны иметь типы данных тип varchar или аргумент или чар чтобы он мог принимать недопустимые записи.в пакете служб SSIS создайте соединение OLE DB с именем SQLServer для подключения к базе данных SQL Server и создайте соединение с плоским файлом CSV. Смотрите скриншот #2. Настройте соединение с плоским файлом CSV, как показано на скриншотах #3 - #7. Все столбцы в соединении с плоским файлом должны быть настроены как строка тип данных, чтобы пакет не сбой при чтении файла.
на вкладке поток управления пакета поместите
Data Flow Taskкак показано на скриншоте #8.на вкладке "поток данных" пакет, место
Flat File Sourceи настройте его, как показано на скриншотах #9 и№10.на вкладке поток данных пакета, поместить
Data Conversionпреобразование и настройте его, как показано на скриншоте #11. Нажмите наConfigure Error Output, и и усечение значения столбцов из сбой компонента to перенаправить строку. Смотрите скриншот #12.на вкладке поток данных пакета, поместить
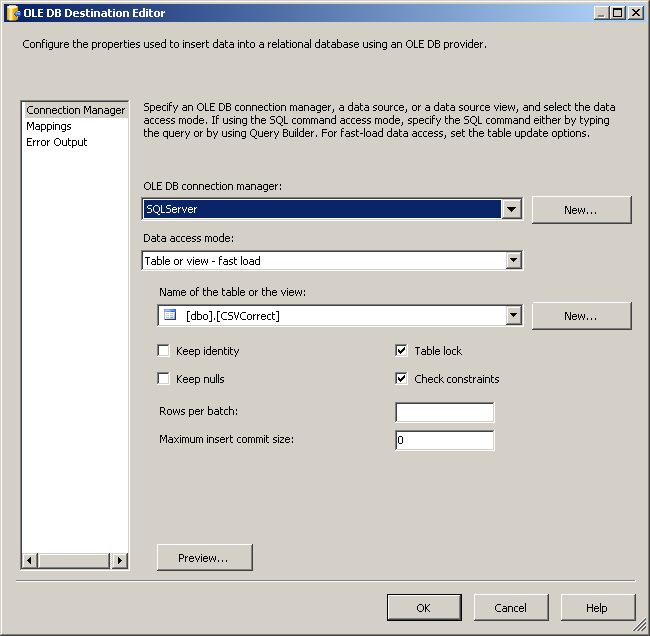
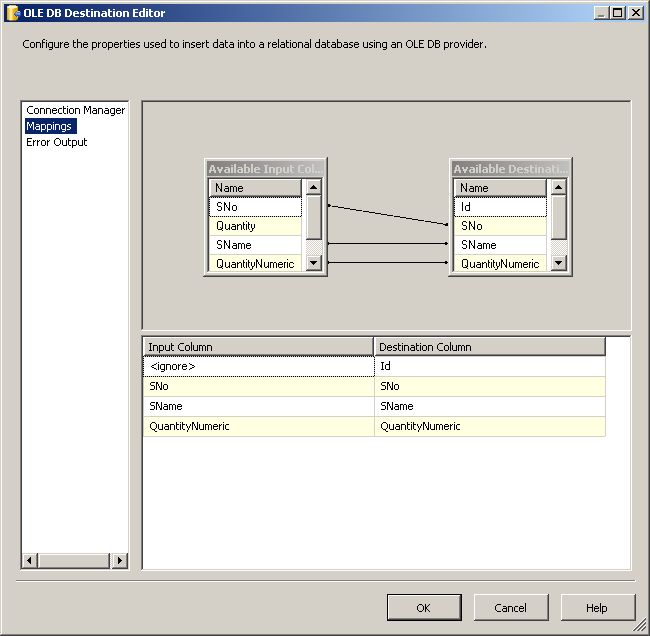
OLE DB Destinationи соедините зеленое стрелка Преобразование Данных к этому назначению OLE DB. Настройте назначение OLE DB, как показано на скриншотах #13 и№14.на вкладке поток данных пакета, поместите другой
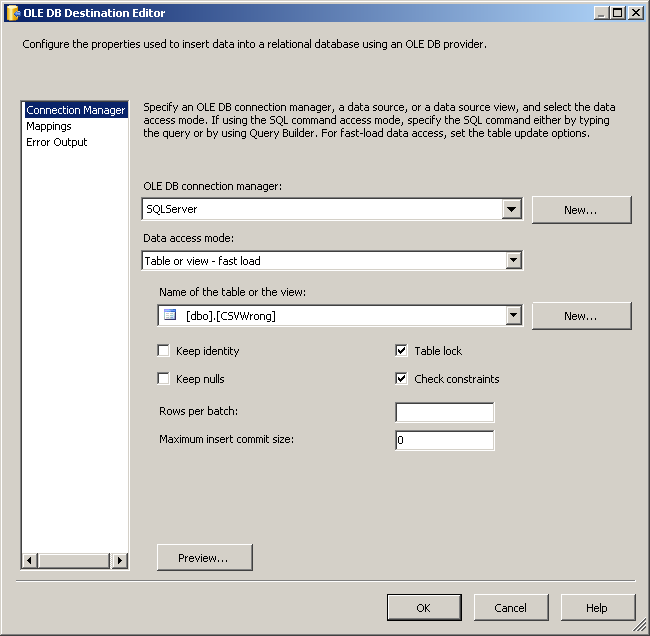
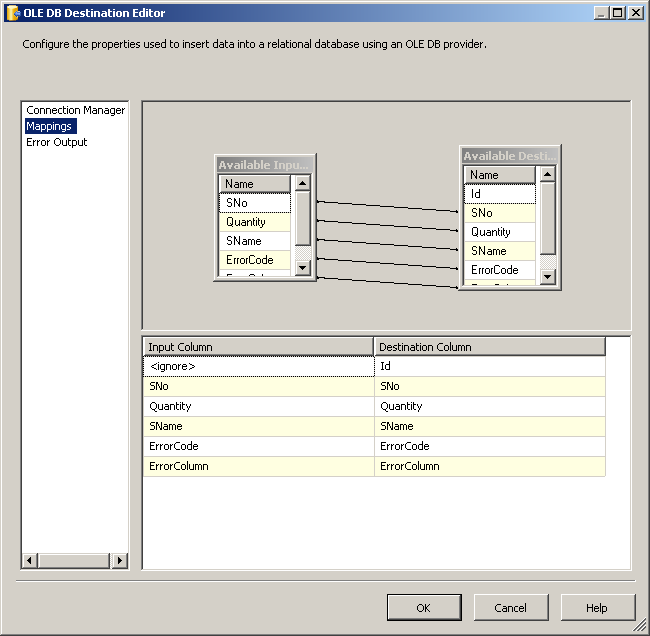
OLE DB Destinationи соедините красный стрелка сведения Преобразование к этому назначению OLE DB. Настройте назначение OLE DB, как показано на скриншотах #15 и№16.скриншот #17 показывает задачу потока данных после ее полной настройки.
скриншот #18 показывает данные в таблицах до выполнение пакета.
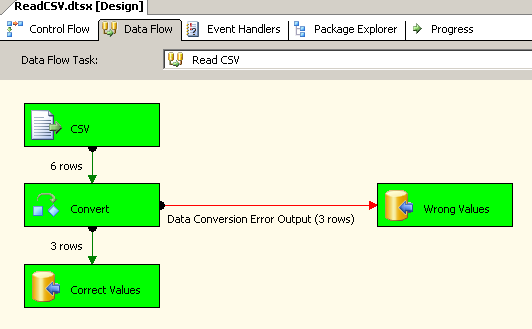
скриншот #19 показывает выполнение пакета в задаче потока данных.
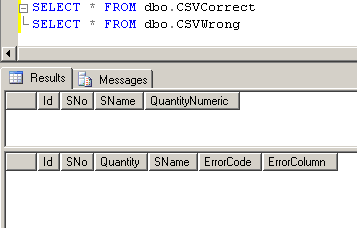
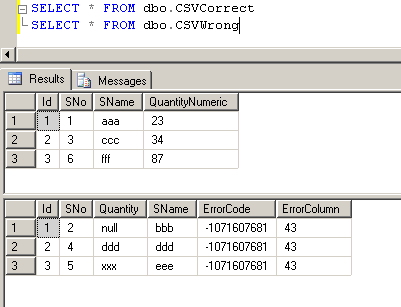
скриншот #20 показывает данные в таблицах после выполнения пакета.
надеюсь, это поможет.
SQL-скриптов:
CREATE TABLE [dbo].[CSVCorrect](
[Id] [int] IDENTITY(1,1) NOT NULL,
[SNo] [int] NULL,
[SName] [varchar](50) NULL,
[QuantityNumeric] [numeric](18, 0) NULL,
CONSTRAINT [PK_CSVCorrect] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[CSVWrong](
[Id] [int] IDENTITY(1,1) NOT NULL,
[SNo] [varchar](50) NULL,
[Quantity] [varchar](50) NULL,
[SName] [varchar](50) NULL,
[ErrorCode] [int] NULL,
[ErrorColumn] [int] NULL,
CONSTRAINT [PK_CSVWrong] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
скриншот #1:
Скриншот #2:
скриншот #3:
скриншот #4:
скриншот #5:
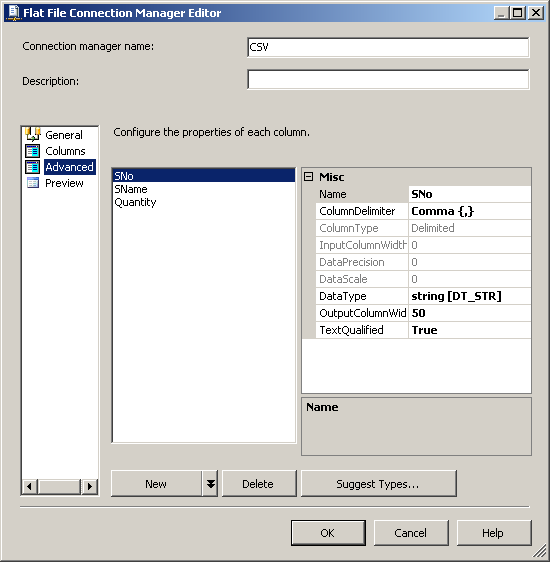
скриншот #6:
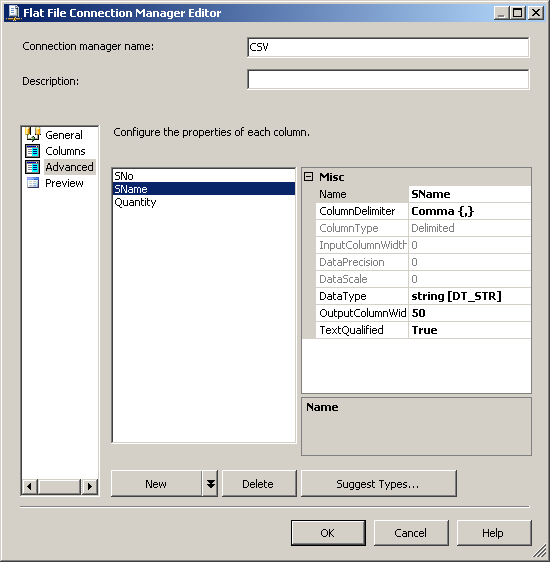
скриншот #7:
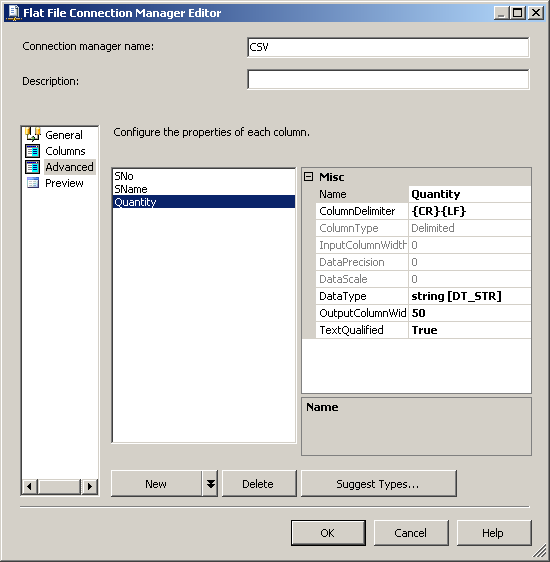
скриншот #8:
скриншот #9:
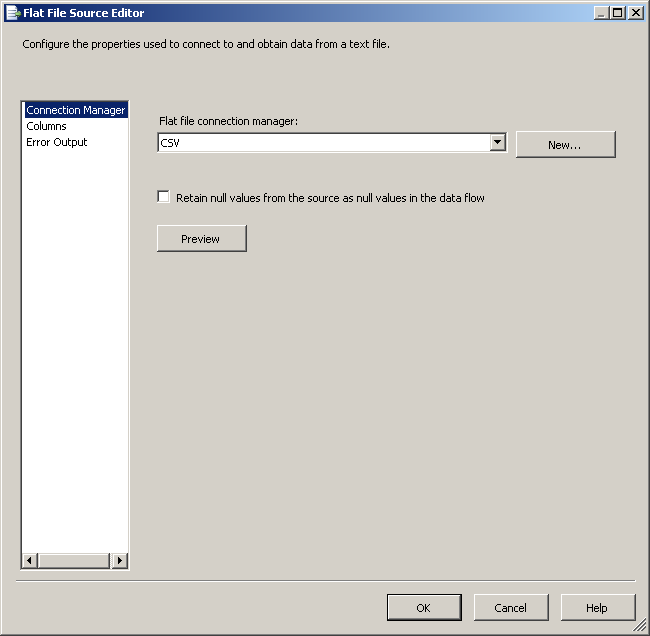
скриншот #10:
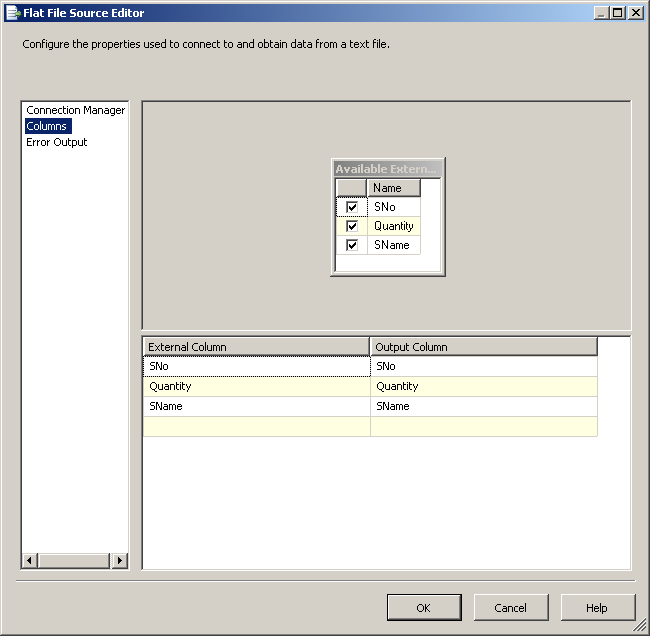
скриншот #11:
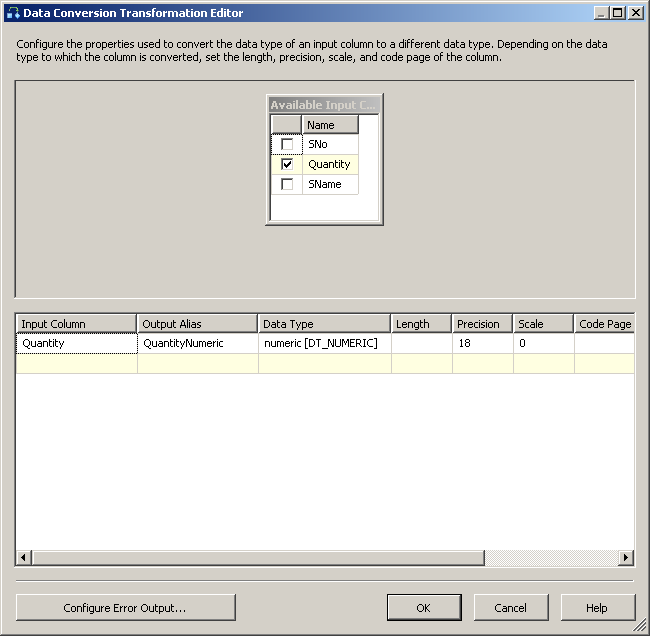
скриншот № 12:
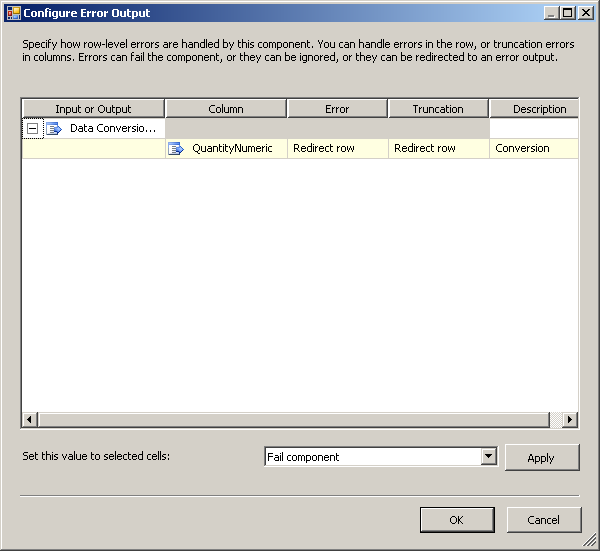
скриншот #13:
скриншот № 14:
скриншот #15:
скриншот № 16:
скриншот #17:
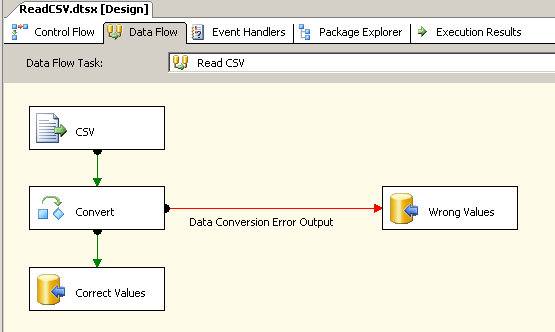
скриншот #18:
скриншот #19:
скриншот #20:
поместите условное разделение в поток данных. Проверьте, не является ли количество нецелым. Созданная вами ветвь перейдет в wrongcsvtable и ветка по умолчанию перейдет в csvtable
редактировать забыл, что в условном разбиении нет числового теста. Что вам нужно сделать, так это добавить производное преобразование столбца, которое преобразует поле quantity в целое число. В диалоговом окне Настройка вывода ошибок задайте значения ошибки и усечения игнорировать неудачи. Это передаст элемент со значением для нового поля как NULL, если данные не являются числовыми. После этого в условном разбиении проверьте, является ли новое поле null или нет. Записи с нулевым полем идут в wrongcsvtable другие записи, перейдите к csvtable.