Как Python dict может иметь несколько ключей с одним и тем же хэшем?
Я пытаюсь понять хэш-функцию python под капотом. Я создал пользовательский класс, где все экземпляры возвращают одно и то же хэш-значение.
class C(object):
def __hash__(self):
return 42
Я просто предположил, что только один экземпляр класса выше может быть в комплекте в любое время, но на самом деле набор может иметь несколько элементов с одинаковым хэшем.
c, d = C(), C()
x = {c: 'c', d: 'd'}
print x
# {<__main__.C object at 0x83e98cc>:'c', <__main__.C object at 0x83e98ec>:'d'}
# note that the dict has 2 elements
Я еще немного поэкспериментировал и обнаружил, что если я переопределю __eq__ способ такой, что все экземпляры класса равны, то множество разрешает только один экземпляр.
class D(C):
def __eq__(self, other):
return hash(self) == hash(other)
p, q = D(), D()
y = {p:'p', q:'q'}
print y
# {<__main__.D object at 0x8817acc>]: 'q'}
# note that the dict has only 1 element
поэтому мне любопытно узнать, как dict может иметь несколько элементов с одним и тем же хэшем. Спасибо!
Примечание: отредактировал вопрос, чтобы дать пример dict (вместо set), потому что все обсуждение в ответах касается dicts. Но то же самое относится и к наборам; наборы также могут иметь несколько элементов с одинаковым хэш-значением.
5 ответов
для подробного описания того, как работает хеширование Python, см. Мой ответ на почему раннее возвращение медленнее, чем остальное?
в основном он использует хэш-выбрать слот в таблице. Если в слоте есть значение и хэш совпадает, он сравнивает элементы, чтобы увидеть, если они равны.
Если хэш не совпадает или элементы не равны, то он пытается другой слот. Существует формула для выбора этого (которую я описываю в ссылочном ответе), и это постепенно вытягивает неиспользуемые части хэш-значения; но как только он использует их все, он в конечном итоге будет работать через все слоты в хэш-таблице. Это гарантирует, что в конечном итоге мы найдем соответствующий элемент или пустой слот. Когда поиск находит пустой слот, он вставляет значение или сдается (в зависимости от того, добавляем мы или получаем значение).
важно отметить, что нет списков или ведер: есть только хэш-таблица с определенным количеством слоты, и каждый хэш используется для создания последовательности слотов-кандидатов.
вот все о Python dicts, которые я смог собрать (вероятно, больше, чем кто-либо хотел бы знать; но ответ является всеобъемлющим). Крик к Дункан для указания на то, что Python диктует использовать слоты и ведет меня вниз эту кроличью нору.
- словари Python реализованы как хэш-таблицы.
- хэш-таблицы должны учитывать хеширования т. е. даже если два ключа есть же хэш-значение, реализация таблицы должна иметь стратегию для вставки и извлечения пар ключ и значение однозначно.
- Python dict использует открыть решении для разрешения хэш-коллизий (описано ниже) (см. dictobject.c: 296-297).
- Python hash table - это просто continguous блок памяти (вроде массива, поэтому вы можете сделать
O(1)поиск по индексу). - каждый слот в таблице может хранить одно и только одна запись. это важно:
- каждого запись в таблице фактически комбинация трех значений -. Это реализовано как структура C (см. dictobject.h: 51-56)
-
на рисунке ниже представлено логическое представление хэш-таблицы python. На рисунке ниже, 0, 1, ..., я. ,.. слева расположены индексы слоты в хэш-таблице (они являются только для иллюстративных целей и не хранятся вместе со столом очевидно!).
# Logical model of Python Hash table -+-----------------+ 0| <hash|key|value>| -+-----------------+ 1| ... | -+-----------------+ .| ... | -+-----------------+ i| ... | -+-----------------+ .| ... | -+-----------------+ n| ... | -+-----------------+ когда новый дикт инициализируется, он начинается с 8 слоты. (см. dictobject.h: 49)
- при добавлении записей в таблицу мы начинаем с некоторого слота,
iна основе хэш-ключа. CPython использует начальноеi = hash(key) & mask. Гдеmask = PyDictMINSIZE - 1, но это не очень важно). Просто обратите внимание, что начальный слот i, который проверяется, зависит от хэш ключа. - если слот пуст, то запись добавляется в слот (по записи, я имею в виду,
<hash|key|value>). Но что, если это место занято!? Скорее всего, потому, что другая запись имеет тот же хэш (хэш-столкновение!) - если слот занят, CPython (и даже PyPy) сравнивает хэш и ключ (по сравнению Я имею в виду
==сравнение неisсравнение) вступления в слот с ключом текущей записи вставлено (dictobject.c: 337,344-345). Если и матч, то он думает, что запись уже существует, сдается и переходит к следующей записи, которая будет вставлена. Если хэш или ключ не совпадают, он запускается прощупывание. - зондирование просто означает, что он ищет слоты по слоту, чтобы найти пустой слот. Технически мы могли бы просто идти один за другим, i+1, i+2,... и использовать первый доступный (это линейное зондирование). Но по понятным причинам красиво в комментариях (см. dictobject.c: 33-126), С CPython использует случайные зондирующего. При случайном зондировании следующий слот выбирается в псевдослучайном порядке. Запись добавляется в первый пустой слот. Для этого обсуждения фактический алгоритм, используемый для выбора следующего слота, не очень важен (см. dictobject.c: 33-126 для алгоритма зондирования). Важно то, что слоты зондируются до тех пор, пока первый пустой слот не будет найдено.
- то же самое происходит для поиска, просто начинается с начального слота i (где я зависит от хэша ключа). Если хэш и ключ не совпадают с записью в слоте, он начинает зондирование, пока не найдет слот с совпадением. Если все слоты исчерпаны, он сообщает об ошибке.
- кстати, дикт будет изменен, если он заполнен на две трети. Это позволяет избежать замедления поиска. (см. dictobject.h: 64-65)
там вы идете! Реализация Python dict проверяет как хэш-равенство двух ключей, так и нормальное равенство (==) ключей при вставке элементов. Итак, в общем, если есть два ключа,a и b и hash(a)==hash(b), а a!=b, тогда оба могут гармонично существовать в Python dict. Но если ... --11--> и a==b, тогда они не могут быть в одном и том же Дикте.
потому что мы должны исследовать после каждого хэш-столкновения, один побочный эффект слишком многих хэш-столкновений это то, что поиск и вставки станут очень медленными (как указывает Дункан в комментарии).
Я думаю, короткий ответ на мой вопрос: "потому что так это реализовано в исходном коде ;)"
в то время как это хорошо знать (для geek points?), Я не уверен, как его можно использовать в реальной жизни. Потому что, если вы не пытаетесь явно сломать что-то, почему два объекта, которые не равны, имеют одинаковый хэш?
редактировать: ответ ниже является одним из возможных способов борьбы с хэш-коллизий, однако не как это делает Python. Ссылка на вики Python ниже также неверна. Лучшим источником, приведенным @Duncan ниже, является сама реализация:http://svn.python.org/projects/python/trunk/Objects/dictobject.c прошу прощения за путаницу.
он хранит список (или ведро) элементов в хэше, а затем повторяет это список, пока он не найдет фактический ключ в этом списке. На картинке написано более тысячи слов:--15-->
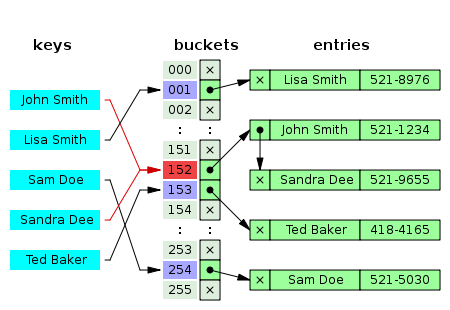
здесь вы видите John Smith и Sandra Dee как хэш 152. Ведро 152 содержит их обоих. При взгляде вверх Sandra Dee сначала он находит список в bucket 152, затем перебирает этот список до Sandra Dee найдено и возвращает 521-6955.
следующее неверно, это только здесь для контекста: On в Python wiki вы можете найти (псевдо?) код, как Python выполняет поиск.
на самом деле существует несколько возможных решений этой проблемы, ознакомьтесь со статьей Википедии для приятного обзора:http://en.wikipedia.org/wiki/Hash_table#Collision_resolution
хэш-таблицы, в общем, должны учитывать хэш-коллизии! Вам не повезет, и две вещи в конечном итоге будут хэшировать одно и то же. Под ним есть набор объектов в списке элементов, который имеет тот же самый хэш-ключ. Обычно в этом списке есть только одна вещь, но в этом случае он будет продолжать складывать их в один и тот же. Единственный способ узнать, что они разные, - через оператор equals.
когда это произойдет, ваша производительность будет ухудшаться с течением времени, что почему вы хотите, чтобы ваша хэш-функция была как можно более "случайной".
в потоке я не видел, что именно python делает с экземплярами пользовательских классов, когда мы помещаем его в словарь в качестве ключей. Давайте прочитаем некоторую документацию: он объявляет, что в качестве ключей могут использоваться только хэшируемые объекты. Hashable-это все неизменяемые встроенные классы и все пользовательские классы.
пользовательские классы имеют __cmp__ () и __хэша__() методы по умолчанию; с ними, все объекты сравните неравные (кроме самих себя) и X.__hash__ () возвращает результат, полученный из id (x).
поэтому, если у вас есть постоянно __hash__ в вашем классе, но не предоставляющий метод __cmp__ или __eq__, то все ваши экземпляры неравны для словаря. С другой стороны, если вы предоставляете какой-либо метод __cmp__ или __eq__, но не предоставляете __hash__, ваши экземпляры по-прежнему неравны с точки зрения словаря.
class A(object):
def __hash__(self):
return 42
class B(object):
def __eq__(self, other):
return True
class C(A, B):
pass
dict_a = {A(): 1, A(): 2, A(): 3}
dict_b = {B(): 1, B(): 2, B(): 3}
dict_c = {C(): 1, C(): 2, C(): 3}
print(dict_a)
print(dict_b)
print(dict_c)
выход
{<__main__.A object at 0x7f9672f04850>: 1, <__main__.A object at 0x7f9672f04910>: 3, <__main__.A object at 0x7f9672f048d0>: 2}
{<__main__.B object at 0x7f9672f04990>: 2, <__main__.B object at 0x7f9672f04950>: 1, <__main__.B object at 0x7f9672f049d0>: 3}
{<__main__.C object at 0x7f9672f04a10>: 3}