Как сравнить символы Юникода, которые "похожи"?
я попадаю в удивительную проблему.
Я загрузил текстовый файл в свое приложение, и у меня есть логика, которая сравнивает значение с Μ.
и я понял, что даже если тексты такие же сравнения имеет значение false.
Console.WriteLine("μ".Equals("µ")); // returns false
Console.WriteLine("µ".Equals("µ")); // return true
в более поздней строке символ µ вставляется копией.
однако это могут быть не единственные символы, которые похожи на это.
есть ли способ в C# сравнить символы, которые выглядят одинаково, но на самом деле разные?
10 ответов
во многих случаях, вы можете нормализуют оба символа Юникода до определенной формы нормализации перед их сравнением, и они должны быть в состоянии соответствовать. Конечно, какая форма нормализации вам нужно использовать, зависит от самих символов; просто потому, что они посмотреть так и не обязательно означает, что они представляют тот же характер. Вам также нужно рассмотреть, подходит ли он для вашего варианта использования - см. комментарий Юкки К. Корпелы.
для этого конкретная ситуация, если вы ссылаетесь на ссылки в Тони!--4-->, вы увидите, что таблица для U + 00B5 говорит:
декомпозиция греческая маленькая буква MU (U+03BC)
это означает, что U + 00B5, второй символ в исходном сравнении, может быть разложен на U + 03BC, первый символ.
таким образом, вы нормализуете символы, используя декомпозицию полной совместимости, с формами нормализации KC или КД. Вот краткий пример, который я написал, чтобы продемонстрировать:
using System;
using System.Text;
class Program
{
static void Main(string[] args)
{
char first = 'μ';
char second = 'µ';
// Technically you only need to normalize U+00B5 to obtain U+03BC, but
// if you're unsure which character is which, you can safely normalize both
string firstNormalized = first.ToString().Normalize(NormalizationForm.FormKD);
string secondNormalized = second.ToString().Normalize(NormalizationForm.FormKD);
Console.WriteLine(first.Equals(second)); // False
Console.WriteLine(firstNormalized.Equals(secondNormalized)); // True
}
}
для получения подробной информации о нормализации Unicode и различных формах нормализации обратитесь к System.Text.NormalizationForm и спецификация Unicode.
потому что это действительно разные символы, даже они выглядят одинаково, сначала это фактическая буква и имеет char code = 956 (0x3BC) а второй-микро-знак и имеет 181 (0xB5).
ссылки:
поэтому, если вы хотите сравнить их, и вам нужно, чтобы они были равными, вам нужно обработать его вручную или перед сравнением замените один символ другим. Или используйте следующий код:
public void Main()
{
var s1 = "μ";
var s2 = "µ";
Console.WriteLine(s1.Equals(s2)); // false
Console.WriteLine(RemoveDiacritics(s1).Equals(RemoveDiacritics(s2))); // true
}
static string RemoveDiacritics(string text)
{
var normalizedString = text.Normalize(NormalizationForm.FormKC);
var stringBuilder = new StringBuilder();
foreach (var c in normalizedString)
{
var unicodeCategory = CharUnicodeInfo.GetUnicodeCategory(c);
if (unicodeCategory != UnicodeCategory.NonSpacingMark)
{
stringBuilder.Append(c);
}
}
return stringBuilder.ToString().Normalize(NormalizationForm.FormC);
}
и демо
Они оба имеют разные коды символов: см. это для получения более подробной информации
Console.WriteLine((int)'μ'); //956
Console.WriteLine((int)'µ'); //181
где, 1-я:
Display Friendly Code Decimal Code Hex Code Description
====================================================================
μ μ μ μ Lowercase Mu
µ µ µ µ micro sign Mu
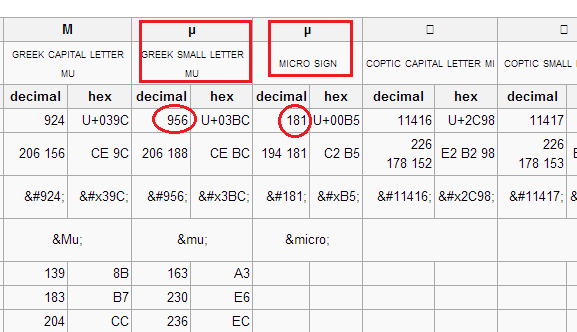
для конкретного примера μ (mu) и µ (микро-знак), последний имеет декомпозиции совместимости к первому, так что вы можете нормализуют строка FormKC или FormKD преобразовать микро-знаки в mus.
однако существует множество наборов символов, которые выглядят одинаково, но не эквивалентны ни в одной форме нормализации Unicode. Например, A (лат.), Α (греч.), и А (кириллица). На сайте Юникод имеет confusables.txt файл со списком этих, предназначенных, чтобы помочь разработчикам защититься от омографических атак. При необходимости вы можете проанализировать этот файл и построить таблицу для "визуальной нормализации" строк.
Поиск как символы базы данных Unicode и видим разница.
один греческая строчная буква µ и другое Микро Знак µ.
Name : MICRO SIGN Block : Latin-1 Supplement Category : Letter, Lowercase [Ll] Combine : 0 BIDI : Left-to-Right [L] Decomposition : <compat> GREEK SMALL LETTER MU (U+03BC) Mirror : N Index entries : MICRO SIGN Upper case : U+039C Title case : U+039C Version : Unicode 1.1.0 (June, 1993)
Name : GREEK SMALL LETTER MU Block : Greek and Coptic Category : Letter, Lowercase [Ll] Combine : 0 BIDI : Left-to-Right [L] Mirror : N Upper case : U+039C Title case : U+039C See Also : micro sign U+00B5 Version : Unicode 1.1.0 (June, 1993)
редактировать после слияния этого вопроса с как сравнить " μ " и " µ " в C#
Оригинальный ответ размещен:
"μ".ToUpper().Equals("µ".ToUpper()); //This always return true.
редактировать После прочтения комментариев, Да, нехорошо использовать вышеуказанный метод, потому что он может дать неправильные результаты для некоторых других типов входных данных, для этого мы должны использовать нормализуют использование полной декомпозиции совместимости, как указано в wiki. (Благодаря ответу сообщение от BoltClock)
static string GREEK_SMALL_LETTER_MU = new String(new char[] { '\u03BC' });
static string MICRO_SIGN = new String(new char[] { '\u00B5' });
public static void Main()
{
string Mus = "µμ";
string NormalizedString = null;
int i = 0;
do
{
string OriginalUnicodeString = Mus[i].ToString();
if (OriginalUnicodeString.Equals(GREEK_SMALL_LETTER_MU))
Console.WriteLine(" INFORMATIO ABOUT GREEK_SMALL_LETTER_MU");
else if (OriginalUnicodeString.Equals(MICRO_SIGN))
Console.WriteLine(" INFORMATIO ABOUT MICRO_SIGN");
Console.WriteLine();
ShowHexaDecimal(OriginalUnicodeString);
Console.WriteLine("Unicode character category " + CharUnicodeInfo.GetUnicodeCategory(Mus[i]));
NormalizedString = OriginalUnicodeString.Normalize(NormalizationForm.FormC);
Console.Write("Form C Normalized: ");
ShowHexaDecimal(NormalizedString);
NormalizedString = OriginalUnicodeString.Normalize(NormalizationForm.FormD);
Console.Write("Form D Normalized: ");
ShowHexaDecimal(NormalizedString);
NormalizedString = OriginalUnicodeString.Normalize(NormalizationForm.FormKC);
Console.Write("Form KC Normalized: ");
ShowHexaDecimal(NormalizedString);
NormalizedString = OriginalUnicodeString.Normalize(NormalizationForm.FormKD);
Console.Write("Form KD Normalized: ");
ShowHexaDecimal(NormalizedString);
Console.WriteLine("_______________________________________________________________");
i++;
} while (i < 2);
Console.ReadLine();
}
private static void ShowHexaDecimal(string UnicodeString)
{
Console.Write("Hexa-Decimal Characters of " + UnicodeString + " are ");
foreach (short x in UnicodeString.ToCharArray())
{
Console.Write("{0:X4} ", x);
}
Console.WriteLine();
}
выход
INFORMATIO ABOUT MICRO_SIGN
Hexa-Decimal Characters of µ are 00B5
Unicode character category LowercaseLetter
Form C Normalized: Hexa-Decimal Characters of µ are 00B5
Form D Normalized: Hexa-Decimal Characters of µ are 00B5
Form KC Normalized: Hexa-Decimal Characters of µ are 03BC
Form KD Normalized: Hexa-Decimal Characters of µ are 03BC
________________________________________________________________
INFORMATIO ABOUT GREEK_SMALL_LETTER_MU
Hexa-Decimal Characters of µ are 03BC
Unicode character category LowercaseLetter
Form C Normalized: Hexa-Decimal Characters of µ are 03BC
Form D Normalized: Hexa-Decimal Characters of µ are 03BC
Form KC Normalized: Hexa-Decimal Characters of µ are 03BC
Form KD Normalized: Hexa-Decimal Characters of µ are 03BC
________________________________________________________________
при чтении информации в Unicode_equivalence нашел
выбор критериев эквивалентности может повлиять на результаты поиска. Например, некоторые типографские лигатуры, такие как U+FB03 (ffi), ..... так поиск для U + 0066 (f) в качестве подстроки успеха на NFKC нормализация U+FB03 но не в NFC нормализация U+FB03.
поэтому для сравнения эквивалентности мы должны обычно использовать FormKC т. е. нормализация NFKC или FormKD i.e нормализация NFKD.
Мне было немного любопытно узнать больше обо всех символах Юникода, поэтому я сделал образец, который будет повторять все символы Юникода в UTF-16 и у меня есть некоторые результаты, которые я хочу обсудить
- информация о персонажах чей
FormCиFormDнормированные значения не были эквивалентныTotal: 12,118Character (int value): 192-197, 199-207, 209-214, 217-221, 224-253, ..... 44032-55203 - информация о персонажах, чьи
FormKCиFormKDнормированные значения не были эквивалентныTotal: 12,245Character (int value): 192-197, 199-207, 209-214, 217-221, 224-228, ..... 44032-55203, 64420-64421, 64432-64433, 64490-64507, 64512-64516, 64612-64617, 64663-64667, 64735-64736, 65153-65164, 65269-65274 - весь персонаж чей
FormCиFormDнормализованные значения не были эквивалентны, тамFormKCиFormKDнормализованные значения также не были эквивалентны, кроме этих символов
Письмена:901 '΅', 8129 '῁', 8141 '῍', 8142 '῎', 8143 '῏', 8157 '῝', 8158 '῞', 8159 '῟', 8173 '῭', 8174 '΅' - дополнительный персонаж, чей
FormKCиFormKDнормализованные значения не были эквивалентны, но тамFormCиFormDнормализованные значения были эквивалентныTotal: 119
Персонажи:452 'DŽ' 453 'Dž' 454 'dž' 12814 '㈎' 12815 '㈏' 12816 '㈐' 12817 '㈑' 12818 '㈒' 12819 '㈓' 12820 '㈔' 12821 '㈕', 12822 '㈖' 12823 '㈗' 12824 '㈘' 12825 '㈙' 12826 '㈚' 12827 '㈛' 12828 '㈜' 12829 '㈝' 12830 '㈞' 12910 '㉮' 12911 '㉯' 12912 '㉰' 12913 '㉱' 12914 '㉲' 12915 '㉳' 12916 '㉴' 12917 '㉵' 12918 '㉶' 12919 '㉷' 12920 '㉸' 12921 '㉹' 12922 '㉺' 12923 '㉻' 12924 '㉼' 12925 '㉽' 12926 '㉾' 13056 '㌀' 13058 '㌂' 13060 '㌄' 13063 '㌇' 13070 '㌎' 13071 '㌏' 13072 '㌐' 13073 '㌑' 13075 '㌓' 13077 '㌕' 13080 '㌘' 13081 '㌙' 13082 '㌚' 13086 '㌞' 13089 '㌡' 13092 '㌤' 13093 '㌥' 13094 '㌦' 13099 '㌫' 13100 '㌬' 13101 '㌭' 13102 '㌮' 13103 '㌯' 13104 '㌰' 13105 '㌱' 13106 '㌲' 13108 '㌴' 13111 '㌷' 13112 '㌸' 13114 '㌺' 13115 '㌻' 13116 '㌼' 13117 '㌽' 13118 '㌾' 13120 '㍀' 13130 '㍊' 13131 '㍋' 13132 '㍌' 13134 '㍎' 13139 '㍓' 13140 '㍔' 13142 '㍖' .......... ﺋ' 65164 'ﺌ' 65269 'ﻵ' 65270 'ﻶ' 65271 'ﻷ' 65272 'ﻸ' 65273 'ﻹ' 65274' - есть некоторые символы, которые не может быть нормализован, они бросают
ArgumentExceptionесли пробовалTotal:2081Characters(int value): 55296-57343, 64976-65007, 65534
эти ссылки могут быть действительно полезны, чтобы понять, какие правила govern для эквивалентности Unicode
скорее всего, есть два разных кода символов, которые делают (заметно) один и тот же символ. Хотя технически они не равны, они выглядят равными. Посмотрите на таблицу символов и посмотрите, есть ли несколько экземпляров этого символа. Или распечатайте код символов двух символов в коде.
вы спросите: "как сравнить их", но вы не говорите нам, что вы хотите сделать.
существует по крайней мере два основных способа их сравнения:
либо вы сравниваете их напрямую, как вы, и они разные
или вы используете нормализацию совместимости Unicode, если вам нужно сравнение, которое находит их соответствующими.
может возникнуть проблема, потому что нормализация совместимости Unicode сделает многие другие символы равными. Если вы хотите, чтобы только эти два символа рассматривались как одинаковые, вы должны свернуть свои собственные функции нормализации или сравнения.
для более конкретного решения нам нужно знать ваши конкретные проблемы. В каком контексте вы столкнулись с этой проблемой?
во-первых, 2 сущности, которые вы пытаетесь сравнить, являются glyphs, глиф является частью набора символов, предоставляемых тем, что обычно известно как "шрифт", вещь, которая обычно приходит в ttf, otf или любой формат, который вы используете.
глифы представление учитывая символ, и поскольку они являются представлением, которое зависит от определенного набора, вы не можете просто ожидать, что у вас будет 2 похожих или даже "лучших" одинаковых символа, это фраза, которая не имеет смысла, если вы рассматриваете контекст, вы должны по крайней мере указать, какой шрифт или набор символов вы рассматриваете, когда формулируете такой вопрос.
что обычно используется для решения проблемы, подобной той, с которой вы сталкиваетесь, это OCR, по существу программное обеспечение, которое распознает и сравнивает глифы, если C# предоставляет OCR по умолчанию я этого не знаю, но это вообще очень плохая идея, если вам действительно не нужен OCR, и вы знаете, что с ним делать.
вы можете в конечном итоге интерпретировать книгу по физике как древнегреческую книгу, не упоминая тот факт, что OCR обычно дороги с точки зрения ресурсов.
есть причина, почему эти символы локализованы так, как они локализованы, просто не делайте этого.
можно нарисовать оба символа с одинаковым стилем и размером шрифта с помощью DrawString метод. После создания двух растровых изображений с символами их можно сравнить пиксель за пикселем.
преимущество этого метода заключается в том, что вы можете сравнивать не только абсолютные равные герои, но слишком похожие (с определенным допуском).