Как удалить все ссылки HTML-файла в Bash или grep или batch и сохранить их в текстовом файле
у меня есть файл, который является HTML-код, и он имеет около 150 ссылок. Мне нужны только ссылки из этих тегов, АКА,<a href="*http://www.google.com*"></a>. Я хочу получить только http://www.google.com часть.
когда я запускаю grep,
cat website.htm | grep -E '<a href=".*">' > links.txt
это возвращает мне всю строку, которую он нашел на не той ссылке, которую я хочу, поэтому я попытался использовать cut:
cat drawspace.txt | grep -E '<a href=".*">' | cut -d’”’ --output-delimiter=$'n' > links.txt
кроме того, что это неправильно, и это не работает, дайте мне некоторые ошибки о неправильных параметрах... Поэтому я предполагаю,что файл тоже должен был быть передан. Может быть, как cut -d’”’ --output-delimiter=$'n' grepedText.txt > links.txt.
но я хотел сделать это в одной команде, если это возможно... Поэтому я попытался сделать на awk.
cat drawspace.txt | grep '<a href=".*">' | awk '{print }’
но это тоже не будет работать. Он требовал от меня больше информации, потому что я еще не закончил....
Я попытался написать пакетный файл, и он сказал мне, что FINDSTR не является внутренней или внешней командой... Поэтому я принимаю свое окружение. переменные были перепутаны и вместо того, чтобы исправить, что я попытался установить grep на Windows, но это дало мне ту же ошибку....
вопрос в том, как правильно удалить HTTP-ссылки из HTML-код? С этим я заставлю его работать на мою ситуацию.
P. S. Я вот читаю так много ссылок/переполнение стека постов, что показ моих ссылок займет слишком много времени.... Если пример HTML необходим, чтобы показать сложность процесса, то я добавлю он.
у меня также есть Mac и ПК, которые я переключал между ними, чтобы использовать их команды shell/batch/grep/terminal, так что либо или поможет мне.
Я также хочу отметить, что я нахожусь в правильном каталоге
HTML-код:
<tr valign="top">
<td class="beginner">
B03
</td>
<td>
<a href="http://www.drawspace.com/lessons/b03/simple-symmetry">Simple Symmetry</a> </td>
</tr>
<tr valign="top">
<td class="beginner">
B04
</td>
<td>
<a href="http://www.drawspace.com/lessons/b04/faces-and-a-vase">Faces and a Vase</a> </td>
</tr>
<tr valign="top">
<td class="beginner">
B05
</td>
<td>
<a href="http://www.drawspace.com/lessons/b05/blind-contour-drawing">Blind Contour Drawing</a> </td>
</tr>
<tr valign="top">
<td class="beginner">
B06
</td>
<td>
<a href="http://www.drawspace.com/lessons/b06/seeing-values">Seeing Values</a> </td>
</tr>
ожидаемый результат:
http://www.drawspace.com/lessons/b03/simple-symmetry
http://www.drawspace.com/lessons/b04/faces-and-a-vase
http://www.drawspace.com/lessons/b05/blind-contour-drawing
etc.
5 ответов
$ sed -n 's/.*href="\([^"]*\).*//p' file
http://www.drawspace.com/lessons/b03/simple-symmetry
http://www.drawspace.com/lessons/b04/faces-and-a-vase
http://www.drawspace.com/lessons/b05/blind-contour-drawing
http://www.drawspace.com/lessons/b06/seeing-values
можно использовать grep для этого:
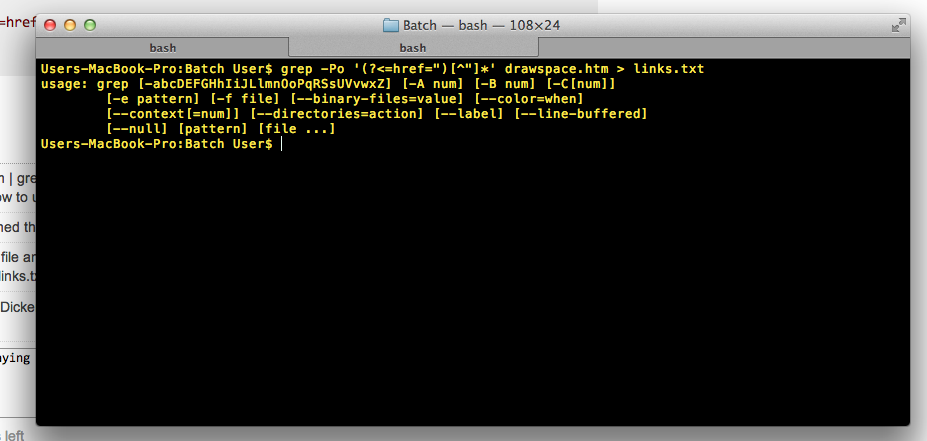
grep -Po '(?<=href=")[^"]*' file
он печатает все, что после href=" пока не появится новая двойная кавычка.
С заданным вводом он возвращает:
http://www.drawspace.com/lessons/b03/simple-symmetry
http://www.drawspace.com/lessons/b04/faces-and-a-vase
http://www.drawspace.com/lessons/b05/blind-contour-drawing
http://www.drawspace.com/lessons/b06/seeing-values
обратите внимание, что не нужно писать cat drawspace.txt | grep '<a href=".*">', вы можете избавиться от бесполезное использование cat С grep '<a href=".*">' drawspace.txt.
другой пример
$ cat a
hello <a href="httafasdf">asdas</a>
hello <a href="hello">asdas</a>
other things
$ grep -Po '(?<=href=")[^"]*' a
httafasdf
hello
Я предполагаю, что ваш компьютер или Mac не будет иметь команду lynx, установленную по умолчанию (она доступна бесплатно в интернете), но lynx позволит вам делать такие вещи:
$lynx-дамп-image_links-listonly / usr / share/xdiagnose / рабочие нагрузки / youtube-перезагрузка.HTML-код
выход: Ссылки
- файл://localhost/usr/share/xdiagnose / рабочие нагрузки / youtube-перезагрузка.HTML-код
- http://www.youtube.com/v/zeNXuC3N5TQ&hl=en&fs=1&autoplay=1
тогда это простой вопрос для grep для http: lines. И даже могут быть варианты lynx для печати только http: lines (у lynx есть много, много вариантов).
согласно комментарию triplee, использование regex для анализа HTML или XML-файлов по существу не выполняется. Такие инструменты, как sed и awk чрезвычайно эффективны для обработки текстовых файлов, но когда это сводится к разбору сложноструктурированных данных-таких как XML, HTML, JSON, ... - они не более чем кувалда. Да, вы можете выполнить работу, но иногда это будет стоить огромных денег. Для обработки таких деликатных файлов вам нужно немного больше тонкости, используя более целевой набор инструментов.
в случае разбора XML или HTML, можно легко использовать xmlstarlet.
в случае файла XHTML вы можете использовать :
xmlstarlet sel --html -N "x=http://www.w3.org/1999/xhtml" \
-t -m '//x:a/@href' -v . -n
здесь -N дает пространство имен XHTML, если таковые имеются, это распознается
<html xmlns="http://www.w3.org/1999/xhtml">
однако, поскольку HTML-страницы часто не являются хорошо сформированным XML, может быть удобно очистить его немного, используя tidy. В приведенном выше примере это дает тогда:
$ tidy -q -numeric -asxhtml --show-warnings no <file.html> \
| xmlstarlet sel --html -N "x=http://www.w3.org/1999/xhtml" \
-t -m '//x:a/@href' -v . -n
http://www.drawspace.com/lessons/b03/simple-symmetry
http://www.drawspace.com/lessons/b04/faces-and-a-vase
http://www.drawspace.com/lessons/b05/blind-contour-drawing
http://www.drawspace.com/lessons/b06/seeing-values
использовать grep извлечь все строки со ссылками в них, а затем использовать sed чтобы вытащить URL-адреса:
grep -o '<a href=".*">' *.html | sed 's/\(<a href="\|\">\)//g' > link.txt;