Как удалить выбросы из набора данных
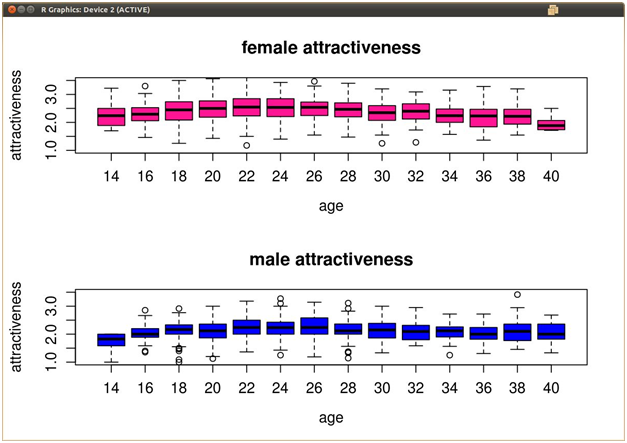
У меня есть несколько многомерных данных красоты против возрастов. Возрасте от 20-40 с интервалом 2 (20, 22, 24....40), и для каждой записи данных им присваивается рейтинг возраста и красоты от 1-5. Когда я делаю boxplots этих данных (возраст по оси X, рейтинги красоты по оси Y), есть некоторые выбросы, нанесенные вне усов каждой коробки.
Я хочу удалить эти выбросы из самого фрейма данных, но я не уверен, как R вычисляет выбросы для своей коробки график. Ниже приведен пример того, как могут выглядеть мои данные.
8 ответов
OK, вы должны применить что-то подобное к вашему набору данных. Не заменяйте и не сохраняйте, иначе вы уничтожите свои данные! И, кстати, вы должны (почти) никогда не удалять выбросы из своих данных:
remove_outliers <- function(x, na.rm = TRUE, ...) {
qnt <- quantile(x, probs=c(.25, .75), na.rm = na.rm, ...)
H <- 1.5 * IQR(x, na.rm = na.rm)
y <- x
y[x < (qnt[1] - H)] <- NA
y[x > (qnt[2] + H)] <- NA
y
}
чтобы увидеть его в действии:
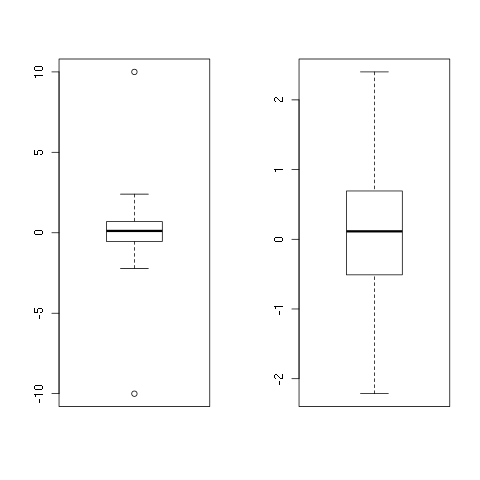
set.seed(1)
x <- rnorm(100)
x <- c(-10, x, 10)
y <- remove_outliers(x)
## png()
par(mfrow = c(1, 2))
boxplot(x)
boxplot(y)
## dev.off()
и еще раз, вы никогда не должны делать это самостоятельно, выбросы просто должны быть! =)
EDIT: добавил na.rm = TRUE по умолчанию.
EDIT2: удалены добавил subscripting, следовательно, сделал функцию быстрее! =)
никто не опубликовал самый простой ответ:
x[!x %in% boxplot.stats(x)$out]
Также см. Это: http://www.r-statistics.com/2011/01/how-to-label-all-the-outliers-in-a-boxplot/
использовать outline = FALSE в качестве опции, когда вы делаете boxplot (прочитайте справку!).
> m <- c(rnorm(10),5,10)
> bp <- boxplot(m, outline = FALSE)
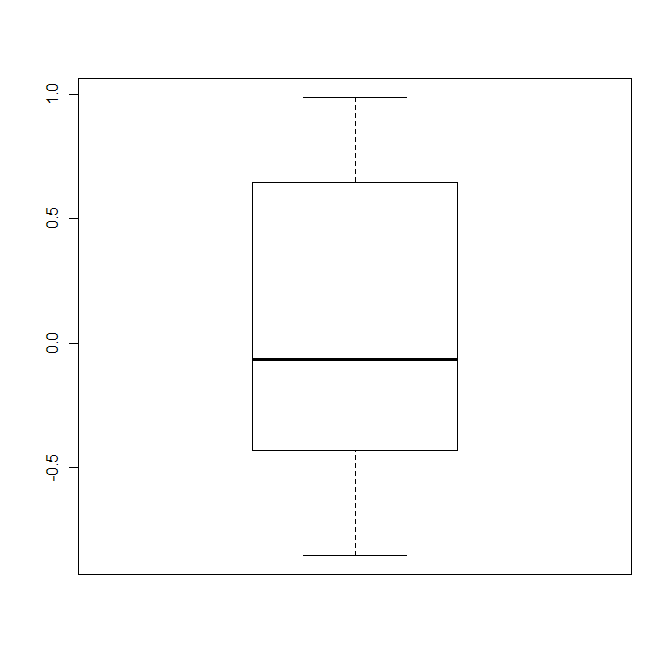
функция boxplot возвращает значения, используемые для построения графика (что фактически выполняется bxp ():
bstats <- boxplot(count ~ spray, data = InsectSprays, col = "lightgray")
#need to "waste" this plot
bstats$out <- NULL
bstats$group <- NULL
bxp(bstats) # this will plot without any outlier points
Я намеренно не ответил на конкретный вопрос, потому что считаю статистическую халатность удалить "выбросы". Я считаю приемлемой практикой не заносить их в картотеку, но их удаление-систематическое и неоправданное искажение данных наблюдений.
x<-quantile(retentiondata$sum_dec_incr,c(0.01,0.99))
data_clean <- data[data$attribute >=x[1] & data$attribute<=x[2],]
Я считаю, что это очень легко удалить выбросы. В приведенном выше примере я просто извлекаю 2 процентиля до 98 процентилей значений атрибутов.
Я искал пакеты, связанные с удалением выбросов, и нашел этот пакет (удивительно называемый "выбросами"!): https://cran.r-project.org/web/packages/outliers/outliers.pdf
если вы пройдете через него, вы увидите разные способы удаления выбросов, и среди них я нашел rm.outlier наиболее удобный в использовании и, как говорится в ссылке выше:
"Если выброс обнаружен и подтвержден статистическими тестами, эта функция может удалить его или заменить на
среднее или медианное значение выборки" а также Вот часть использования из того же источника:
"использование
rm.outlier(x, fill = FALSE, median = FALSE, opposite = FALSE)
Аргументы
x набор данных, чаще всего вектор. Если аргумент является dataframe, то выброс
удалены из каждой колонки sapply. Такое же поведение применяется применяется
когда матрица задана.
заполнить если установлено значение TRUE, медиана или среднее значение помещается вместо выбросов. В противном случае
выбросы is / are просто удаленный.
в среднем если установлено значение TRUE, медиана используется вместо среднего в замене выбросов.
напротив, если установлено значение TRUE, дает противоположное значение (если наибольшее значение имеет максимальную разницу
из среднего он дает наименьшее и наоборот)
"
добавив к предложению @sefarkas и используя квантиль в качестве отсечек, можно изучить следующий вариант:
newdata <- subset(mydata,!(mydata$var > quantile(mydata$var, probs=c(.01, .99))[2] | mydata$var < quantile(mydata$var, probs=c(.01, .99))[1]) )
это удалит точки точек за пределами 99-го квантиля. Нужно быть осторожным, как то, что aL3Xa говорил о сохранении выбросов. Он должен быть удален только для получения альтернативного консервативного представления данных.
не:
z <- df[df$x > quantile(df$x, .25) - 1.5*IQR(df$x) &
df$x < quantile(df$x, .75) + 1.5*IQR(df$x), ] #rows
выполнить эту задачу довольно легко?