Как ускорить это индексированное представление?
у меня есть простой индексированный вид. Когда я спрашиваю об этом, это довольно медленно. Сначала я покажу вам схемы и индексы. Затем простые вопросы. Наконец, план запроса screnie.
Update: доказательство решения в нижней части этого сообщения.
- схемы
вот как это выглядит: -
CREATE view [dbo].[PostsCleanSubjectView] with SCHEMABINDING AS
SELECT PostId, PostTypeId,
[dbo].[ToUriCleanText]([Subject]) AS CleanedSubject
FROM [dbo].[Posts]
мой udf ToUriCleanText просто заменяет различные символы пустым символом. Например. заменяет все символы " # " на ".
затем я добавлены два индекса на этом: -
индексы
индекс первичного ключа (т. е. Кластеризованный Индекс)
CREATE UNIQUE CLUSTERED INDEX [PK_PostCleanSubjectView] ON
[dbo].[PostsCleanSubjectView]
(
[PostId] ASC
)
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF,
ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
и некластеризованный индекс
CREATE NONCLUSTERED INDEX [IX_PostCleanSubjectView_PostTypeId_Subject] ON
[dbo].[PostsCleanSubjectView]
(
[CleanedSubject] ASC,
[PostTypeId] ASC
)
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF,
ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
теперь, это имеет около 25K строк. Ничего особенного.
когда я делаю следующие запросы, они оба занимают около 4 нечетных секунд. WTF? Так и должно быть.. в основном мгновенно!
запрос 1
SELECT a.PostId
FROM PostsCleanSubjectView a
WHERE a.CleanedSubject = 'Just-out-of-town'
запрос 2 (добавлено другое предложение where пункт)
SELECT a.PostId
FROM PostsCleanSubjectView a
WHERE a.CleanedSubject = 'Just-out-of-town' AND a.PostTypeId = 1
что я сделал не так? ОСО все портит? Я думал, что, поскольку у меня есть такой взгляд, он будет материализован. Таким образом, ему не нужно будет вычислять этот столбец строки.
вот screenie плана запроса, если это помогает :-
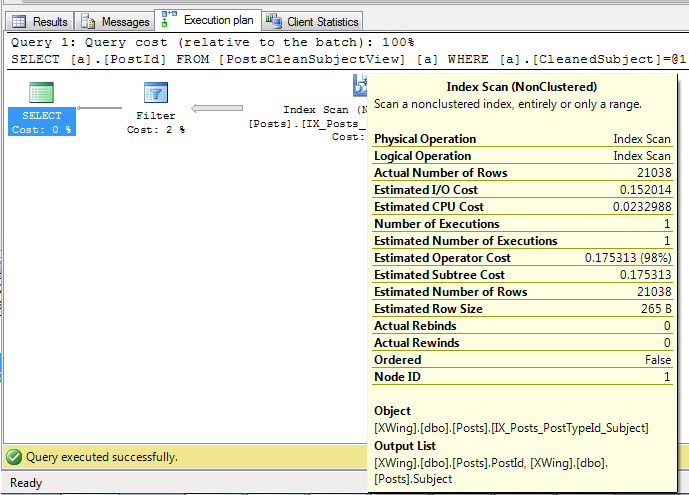
кроме того, обратите внимание на индекс он использует? Почему он использует этот индекс?
этот показатель...
CREATE NONCLUSTERED INDEX [IX_Posts_PostTypeId_Subject] ON [dbo].[Posts]
(
[PostTypeId] ASC,
[Subject] ASC
)
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF,
ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
так что да, любые идеи народ?
обновление 1: добавлена схема для udf.
CREATE FUNCTION [dbo].[ToUriCleanText]
(
@Subject NVARCHAR(300)
)
RETURNS NVARCHAR(350) WITH SCHEMABINDING
AS
BEGIN
<snip>
// Nothing insteresting in here.
//Just lots of SET @foo = REPLACE(@foo, '$', ''), etc.
END
Обновление 2: Решение
Да, это было потому, что я не использовал индекс в представлении и должен был вручную убедиться, что я не расширяю представление. Сервер является SQL Server 2008 Standard Edition. Полный ответ приведен ниже.
Вот доказательство, WITH (NOEXPAND)
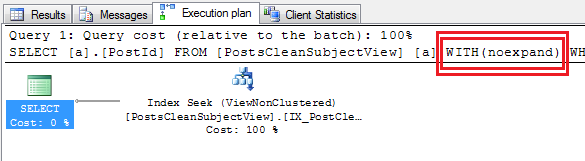
спасибо всем за помощь в решении этой проблемы:)
6 ответов
какой выпуск SQL Server? Я считаю, что только Enterprise и Developer Edition будет использовать индексированные представления автоматически, а другие поддерживают его с помощью подсказок запроса.
SELECT a.PostId
FROM PostsCleanSubjectView a WITH (NOEXPAND)
WHERE a.CleanedSubject = 'Just-out-of-town' AND a.PostTypeId = 1
С подсказки запросов (Transact SQL) в MSDN:
индексированное представление не расширяется только в том случае, если на него непосредственно ссылаются в выделенной части запроса и с (NOEXPAND) или с (NOEXPAND, INDEX( index_value [,...указан Н ] ) ) является.
Я вижу @ sign в коде запроса в вашем плане выполнения. Есть строковая переменная.
Sql Server имеет неприятное поведение, если тип строковой переменной не соответствует типу строкового столбца в индексе. Sql Server будет ... преобразовать весь столбец для этого типа выполните быстрый поиск, а затем выбросьте преобразованный индекс, чтобы он мог снова выполнить весь следующий запрос.
Саймон понял, но вот еще полезная деталь: http://msdn.microsoft.com/en-us/library/ms187373.aspx
Если запрос содержит ссылки на столбцы, присутствующие как в индексированном представлении, так и в базовых таблицах, и оптимизатор запросов определяет, что использование индексированного представления обеспечивает наилучший метод для выполнения запроса, оптимизатор запросов использует индекс в представлении. Эта функция называется сопоставление индексированного представления, и поддерживается только в SQL Server Enterprise и Разработчик изданий.
однако для того, чтобы оптимизатор рассматривал индексированные представления для сопоставления или использования индексированного представления, на которое ссылается подсказка NOEXPAND, следующие параметры набора должны быть установлены в ON:
Итак, то, что здесь происходит, это сопоставление индексированного представления не работает. Убедитесь, что вы используете Enterprise или Developer выпуски Sql Server (скорее всего). Затем проверьте параметры набора в соответствии со статьей.
недавно я построил большую базу данных, содержащую сотни миллионов подробных записей вызовов, и есть некоторые функции, которые я использовал в запросах и представлениях, которые я превратил в сохраненные вычисляемые столбцы. Это сработало намного лучше, потому что я мог индексировать вычисляемый столбец.
Я не использовал SQL Enterprise, поэтому у меня не было возможности использовать индексированные представления. Предполагается, что индексированное представление сможет индексировать детерминированные результаты UDF?
Я подозреваю, что он должен вызвать эту функцию для каждой строки, прежде чем он сможет выполнить сравнение в вашем предложении where. Я бы выставил тему, запустил запрос, проверяя это напрямую и посмотреть, как работают времена. Я обычно видел много медлительности, когда я изменяю значение с помощью функции, а затем использую его в предложении where...
какую пользу вы ищете, используя индексированное представление? Невозможно ли правильно индексировать сами таблицы(таблицы)? Без хорошего обоснования вы добавляете сложность и просите оптимизатора работать с большим количеством объектов базы данных с меньшей гибкостью.
вы оценивали ту же логику запроса со стандартными индексами?
смешивание в логике UDF мутит вещи еще больше.
Если все, что вам нужно, это сохранить возвращаемое значение UDF, рассмотрите сохраненный вычисляемый столбец, а не индексированное представление.