Как внутренняя реализация LinkedHashMap отличается от реализации HashMap?
Я читал, что HashMap имеет следующую реализацию:
main array
↓
[Entry] → Entry → Entry ← linked-list implementation
[Entry]
[Entry] → Entry
[Entry]
[null ]
таким образом, он имеет массив объектов ввода.
вопросы:
мне было интересно, как индекс этого массива может хранить несколько объектов ввода в случае одного и того же хэш-кода, но разных объектов.
чем это отличается от
LinkedHashMapреализация? Его двусвязная реализация списка map, но поддерживает ли он массив, подобный приведенному выше, и как он хранит указатели на следующий и предыдущий элемент?
5 ответов
HashMap не поддерживает порядок вставки, следовательно, не поддерживает двойной связанный список.
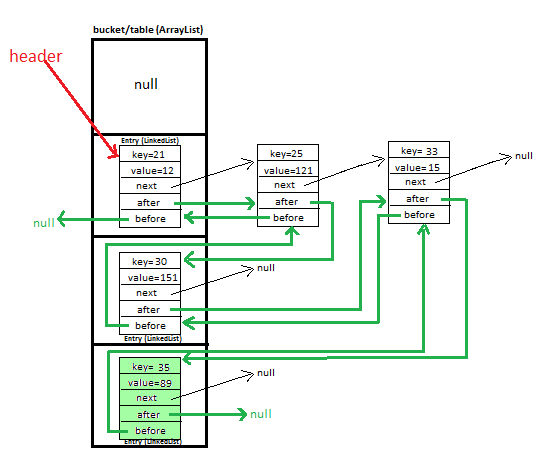
наиболее характерной особенностью LinkedHashMap является то, что он поддерживает порядок вставки пар ключ-значение. LinkedHashMap использует для этого дважды связанный список.
запись LinkedHashMap выглядит так -
static class Entry<K, V> {
K key;
V value;
Entry<K,V> next;
Entry<K,V> before, after; //For maintaining insertion order
public Entry(K key, V value, Entry<K,V> next){
this.key = key;
this.value = value;
this.next = next;
}
}
используя before и after-мы отслеживаем недавно добавленную запись в LinkedHashMap, что помогает нам поддерживать порядок вставки.
перед ссылкой на предыдущую запись и после ссылается на следующую запись в LinkedHashMap.
для схемы и пошаговые инструкции см. http://www.javamadesoeasy.com/2015/02/linkedhashmap-custom-implementation.html
спасибо..!!
взять посмотреть для себя. Для дальнейшего использования, вы можете просто google:
источник java LinkedHashMap
HashMap использует LinkedList для обработки коллизий, но разница между HashMap и LinkedHashMap это LinkedHashMap имеет прогнозируемый порядок итераций, который достигается за счет дополнительного двусвязного списка, который обычно поддерживает порядок вставки ключей. Исключение составляют случаи, когда ключ вставлен в в этом случае он возвращается к исходной позиции в списке.
для справки, повторяя через LinkedHashMap более эффективно, чем итерация через HashMap, а LinkedHashMap меньше оперативную память.
в случае, если это не было ясно из моего вышеописанного объяснения, процесс хэширования тот же, поэтому вы получаете преимущества обычного хэша, но вы также получаете преимущества итерации, как указано выше, так как вы используете дважды связанный список для поддержания порядка вашего Entry объекты, которые не зависят от связанного списка, используемого во время хэширования для коллизий, в случае, если это было неоднозначно..
EDIT: (в ответ на комментарий ОП):
А HashMap поддерживается массивом, в котором некоторые слоты содержат цепи Entry предметы для обработки столкновений. Чтобы перебрать все пары (ключ, значение), вам нужно будет пройти через все слоты в массиве, а затем пройти через LinkedLists; следовательно, ваше общее время будет пропорционально емкости.
при использовании LinkedHashMap, все, что вам нужно сделать, это пройти через дважды связанный список, поэтому общее время пропорционально размеру.
поскольку ни один из других ответов на самом деле не объясняет, как что-то подобное может быть реализовано, я дам ему шанс.
одним из способов было бы иметь некоторую дополнительную информацию в значении (пары ключ - > значение), не видимом пользователю, который имел ссылку на предыдущий и следующий элемент, вставленный в хэш-карту. Преимущества в том, что вы все еще можете удалять элементы в постоянное время удаление из hashmap-это постоянное время, а удаление из связанного списка-в этом случае потому что у вас есть ссылка на запись. Вы все еще можете вставлять в постоянное время, потому что вставка хэш-карты постоянна, связанный список обычно не является, но в этом случае у вас есть постоянный доступ к точке в связанном списке, чтобы вы могли вставлять в постоянное время, и, наконец, извлечение является постоянным временем, потому что вам нужно иметь дело только с частью хэш-карты структуры для него.
имейте в виду, что такая структура данных не приходит без затрат. Размер хэша карта значительно вырастет из-за всех дополнительных ссылок. Каждый из основных методов будет немного медленнее (может иметь значение, если они вызываются повторно). И косвенность структуры данных (не уверен, что это реальный термин :P) увеличивается, хотя это может быть не так важно, потому что ссылки гарантированно указывают на вещи внутри хэш-карты.
поскольку единственным преимуществом этого типа структуры является то, что он сохраняет порядок, будьте осторожны, когда используй его. Также при чтении ответа имейте в виду, что я не знаю, как это реализовано, но это то, как я бы это сделал, если бы дал задачу.
на oracle docs есть цитата, подтверждающая некоторые мои догадки.
эта реализация отличается от HashMap тем, что она поддерживает двусвязный список, проходящий через все его записи.
еще одна актуальная цитата с того же сайта.
этот класс предоставляет все необязательные операции сопоставления и разрешает нулевые элементы. Как и HashMap, он обеспечивает постоянную производительность для основных операций (add, contains и remove), предполагая, что хэш-функция правильно распределяет элементы между ведрами. Производительность, вероятно, будет немного ниже, чем у HashMap, из-за дополнительных расходов на поддержание связанного списка, за одним исключением: итерация по коллекции-представления LinkedHashMap требует время, пропорциональное размеру карты, независимо от ее емкости. Итерация по HashMap, вероятно, будет дороже, требуя времени, пропорционального его емкости.
hashCode будет сопоставлен с любым ведром хэш-функцией. Если есть столкновение в hashCode чем HashMap разрешить это столкновение путем цепочки, т. е. он добавит значение в связанный список. Ниже приведен код, который делает это:
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
392 Object k;
393 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
394 `enter code here` V oldValue = e.value;
395 e.value = value;
396 e.recordAccess(this);
397 return oldValue;
398 }
399 }
вы можете ясно видеть, что он пересекает связанный список, и если он находит ключ, то заменяет старое значение новым добавлением к связанному списку.
но разница между LinkedHashMap и HashMap is LinkedHashMap поддерживает порядок вставки. От docs:
этот связанный список определяет порядок итераций, который обычно является порядком, в котором ключи были вставлены в карту (порядок вставки). Обратите внимание, что порядок вставки не влияют, если ключ вставлен в карту. (Ключ k повторно вставляется в карту m, Если m.put (k, v) вызывается, когда m.containsKey (k) вернет true непосредственно перед вызовом).