Кластеризация текста с расстояниями Левенштейна
У меня есть набор (2k - 4k) небольших строк (3-6 символов), и я хочу их кластеризировать. Поскольку я использую строки, предыдущие ответы на как работает кластеризация (особенно кластеризация строк)?, сообщил мне, что расстояние Левенштейна хорошо использоваться в качестве функции расстояния для строк. Кроме того, поскольку я не знаю заранее количество кластеров, иерархическая кластеризация - это путь, а не k-средних.
хотя я получаю проблема в ее абстрактной форме, я не знаю, что такое легкий способ на самом деле это сделать. Например, является ли MATLAB или R лучшим выбором для фактической реализации иерархической кластеризации с помощью пользовательской функции (расстояние Левенштейна). Для обоих программ можно легко найти реализацию расстояния Левенштейна. Часть кластеризации кажется сложнее. Например кластеризация текста в MATLAB вычисляет расстояние массив всех строк, но я не могу понять, как использовать расстояние массив, чтобы фактически получить кластеризацию. Можете ли вы, гуру, показать мне, как реализовать иерархическую кластеризацию в MATLAB или R с помощью пользовательской функции?
4 ответов
это может быть немного упрощенно, но вот пример кода, который использует иерархическую кластеризацию на основе расстояния Левенштейна в р.
set.seed(1)
rstr <- function(n,k){ # vector of n random char(k) strings
sapply(1:n,function(i){do.call(paste0,as.list(sample(letters,k,replace=T)))})
}
str<- c(paste0("aa",rstr(10,3)),paste0("bb",rstr(10,3)),paste0("cc",rstr(10,3)))
# Levenshtein Distance
d <- adist(str)
rownames(d) <- str
hc <- hclust(as.dist(d))
plot(hc)
rect.hclust(hc,k=3)
df <- data.frame(str,cutree(hc,k=3))
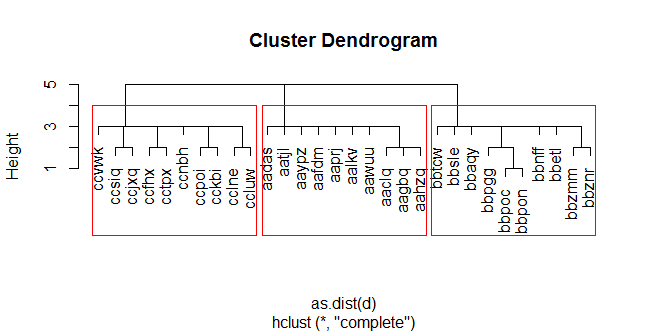
в этом примере мы создаем набор из 30 случайных строк char(5) искусственно в 3 группах (начиная с "aa", "bb" и "cc"). Мы вычисляем матрицу расстояний Левенштейна, используя adist(...), и мы запускаем кластеризацию heirarchal с помощью hclust(...). Затем мы разрезаем дендрограмму на три группы с помощью cutree(...) и добавить идентификатор кластера для исходных строк.
елки включает расстояние Левенштейна и предлагает широкий выбор передовых алгоритмов кластеризации, например оптика кластеризации.
поддержка кластеризации текста была предоставлена Феликсом Штальбергом в рамках его работы над:
Штальберг, Ф. Шлиппе, Т., Фогель, С., & Шульц, Т.
сегментация слова через кросс-лингвальное выравнивание слова к фонеме.
мастерская технологии разговорного языка (SLT), 2012 IEEE. IEEE, 2012.
мы, конечно, были бы признательны за дополнительные взносы.
в то время как ответ зависит в определенной степени от смысл строк, в целом ваша проблема решается семейством методов анализа последовательности. Более конкретно, анализ оптимального соответствия (OMA).
чаще всего ОМА осуществляется в три этапа. Во-первых, вы определяете свои последовательности. Из вашего описания я могу предположить, что каждая буква является отдельным "состоянием", строительным блоком в последовательности. Во-вторых, вы будете использовать один из нескольких алгоритмов вычислите расстояния между всеми последовательностями в наборе данных, получив таким образом матрицу расстояний. Наконец, вы подадите эту матрицу расстояний в алгоритм кластеризации, такой как иерархическая кластеризация или разбиение вокруг Медоидов (PAM), которая, по-видимому, приобретает популярность из-за дополнительной информации о качестве кластеров. Последний направляет вас в выборе количества кластеров, один из нескольких субъективных шагов в анализе последовательности.
на R в наиболее удобным пакетом с большим количеством функций является TraMineR на сайте можно найти здесь. Его руководство пользователя очень доступно, и разработчики более или менее активны на SO, а также.
вы, вероятно, обнаружите, что кластеризация не самая сложная часть, за исключением решения о количестве кластеров. Руководство для TraMineR показывает, что синтаксис очень прямой, и результаты легко интерпретировать на основе графов визуальной последовательности. Здесь пример из руководства пользователя:
clusterward1 <- agnes(dist.om1, diss = TRUE, method = "ward")
dist.om1 - это матрица расстояний, полученная OMA, членство в кластере содержится в clusterward1 объект, который вы можете делать все, что хотите: построение, перекодирование в качестве переменных и т. д. The diss=TRUE опция указывает, что объект данных является матрицей несходства (или расстояния). Полегче, а? Самый сложный выбор (не синтаксически, а методологически) - выбрать правильный алгоритм расстояния, подходящий для вашего конкретного приложение. Как только у вас есть это, будучи в состоянии оправдать выбор, остальное довольно легко. Удачи!
Если вы хотите получить четкое объяснение того, как использовать секционированную кластеризацию (которая, безусловно, будет быстрее) для решения вашей проблемы, проверьте эту статью: эффективные методы проверки орфографии с использованием алгоритмов кластеризации. https://www.researchgate.net/publication/255965260_Effective_Spell_Checking_Methods_Using_Clustering_Algorithms?ev=prf_pub
авторы объясняют, как кластеризировать словарь, используя модифицированную (PAM-подобную) версию iK-Means.
лучше Удачи!