кривая scikit-learn-ROC с доверительными интервалами
я могу получить кривую ROC, используя scikit-learn с
fpr, tpr, thresholds = metrics.roc_curve(y_true,y_pred, pos_label=1), где y_true список значений на основе моего золотого стандарта (т. е. 0 для отрицательных и 1 для положительных случаев) и y_pred соответствующий список баллов (например,0.053497243, 0.008521122, 0.022781548, 0.101885263, 0.012913795, 0.0, 0.042881547 [...])
я пытаюсь выяснить, как добавить доверительные интервалы к этой кривой, но не нашел простого способа сделать это с помощью sklearn.
1 ответов
вы можете загрузить вычисления roc (образец с заменой новых версий y_true / y_pred из оригинала y_true / y_pred и пересчитать новое значение для roc_curve каждый раз) и оценить доверительный интервал таким образом.
чтобы учесть изменчивость, вызванную тестом поезда, вы также можете использовать ShuffleSplit CV итератор много раз, подходит модель на поезде сплит, генерировать y_pred для каждой модели и таким образом собрать эмпирическое распределение roc_curves, а также и, наконец, вычислить доверительные интервалы для них.
редактировать: boostrapping в python
вот пример загрузки оценки ROC AUC из прогнозов одной модели. Я выбрал bootstap ROC AUC, чтобы было проще следовать в качестве ответа переполнения стека, но его можно адаптировать для загрузки всей кривой:
import numpy as np
from scipy.stats import sem
from sklearn.metrics import roc_auc_score
y_pred = np.array([0.21, 0.32, 0.63, 0.35, 0.92, 0.79, 0.82, 0.99, 0.04])
y_true = np.array([0, 1, 0, 0, 1, 1, 0, 1, 0 ])
print("Original ROC area: {:0.3f}".format(roc_auc_score(y_true, y_pred)))
n_bootstraps = 1000
rng_seed = 42 # control reproducibility
bootstrapped_scores = []
rng = np.random.RandomState(rng_seed)
for i in range(n_bootstraps):
# bootstrap by sampling with replacement on the prediction indices
indices = rng.random_integers(0, len(y_pred) - 1, len(y_pred))
if len(np.unique(y_true[indices])) < 2:
# We need at least one positive and one negative sample for ROC AUC
# to be defined: reject the sample
continue
score = roc_auc_score(y_true[indices], y_pred[indices])
bootstrapped_scores.append(score)
print("Bootstrap #{} ROC area: {:0.3f}".format(i + 1, score))
вы можете видеть, что нам нужно отклонить некоторые недопустимые повторные выборки. Однако на реальных данных со многими прогнозами это очень редкое событие и не должно существенно влиять на доверительный интервал (вы можете попробовать изменить rng_seed чтобы проверить).
вот гистограмма:
import matplotlib.pyplot as plt
plt.hist(bootstrapped_scores, bins=50)
plt.title('Histogram of the bootstrapped ROC AUC scores')
plt.show()
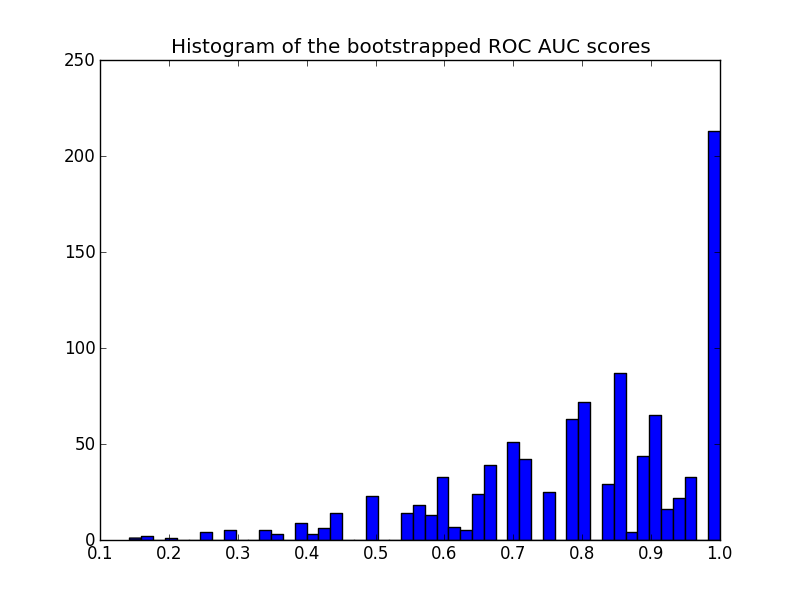
обратите внимание, что пересчитанные баллы цензурируются в диапазоне [0 - 1], вызывая большое количество баллов в последнем бункере.
чтобы получить доверительный интервал можно сортировать образцы:
sorted_scores = np.array(bootstrapped_scores)
sorted_scores.sort()
# Computing the lower and upper bound of the 90% confidence interval
# You can change the bounds percentiles to 0.025 and 0.975 to get
# a 95% confidence interval instead.
confidence_lower = sorted_scores[int(0.05 * len(sorted_scores))]
confidence_upper = sorted_scores[int(0.95 * len(sorted_scores))]
print("Confidence interval for the score: [{:0.3f} - {:0.3}]".format(
confidence_lower, confidence_upper))
что дает:
Confidence interval for the score: [0.444 - 1.0]
доверительный интервал очень широк, но это, вероятно, следствие моего выбора предсказаний (3 ошибки из 9 предсказаний) и общее количество предсказаний довольно мало.
еще одно замечание по сюжету: оценки квантованы (много пустых ячеек гистограммы). Это является следствием небольшого числа предсказаний. Можно было бы ввести немного гауссовского шума на счетах (или y_pred значения) для сглаживания распределения и улучшения гистограммы. Но тогда выбор полосы пропускания сглаживания является сложным.
наконец, как было сказано ранее, этот доверительный интервал специфичен для вас. Чтобы получить лучшую оценку изменчивости ROC, индуцированной вашим классом модели и параметрами, вместо этого следует выполнить итерационную перекрестную проверку. Однако это часто намного дороже, так как вам нужно обучать новую модель для каждого случайного поезда / теста расщеплять.