Кусочная регрессия с R: построение сегментов
у меня 54 балла. Они представляют собой предложение и спрос на продукцию. Я хотел бы показать, что в предложении есть точка разрыва.
во-первых, я сортирую ось x (предложение) и удаляю значения, которые появляются дважды. У меня 47 значений, но я удаляю первое и последнее (не имеет смысла рассматривать их как точки останова). Перерыв имеет длину 45:
Break<-(sort(unique(offer))[2:46])
затем для каждой из этих потенциальных точек разрыва я оцениваю модель и сохраняю в "d" остаточную стандартную ошибку (шестой элемент в объекте сводки модели).
d<-numeric(45)
for (i in 1:45) {
model<-lm(demand~(offer<Break[i])*offer + (offer>=Break[i])*offer)
d[i]<-summary(model)[[6]] }
построив D, я замечаю, что моя меньшая остаточная Стандартная ошибка равна 34, что соответствует "Break[34]": 22.4. Поэтому я пишу свою модель с моей конечной точкой разрыва:
model<-lm(demand~(offer<22.4)*offer + (offer>=22.4)*offer)
наконец, я доволен своей новой моделью. Это значительно лучше, чем простой линейный. И я хочу нарисовать его:
plot(demand~offer)
i <- order(offer)
lines(offer[i], predict(model,list(offer))[i])
но у меня есть предупреждение:
Warning message:
In predict.lm(model, list(offer)) :
prediction from a rank-deficient fit may be misleading
и что более важно, линии действительно странно на моем участке.
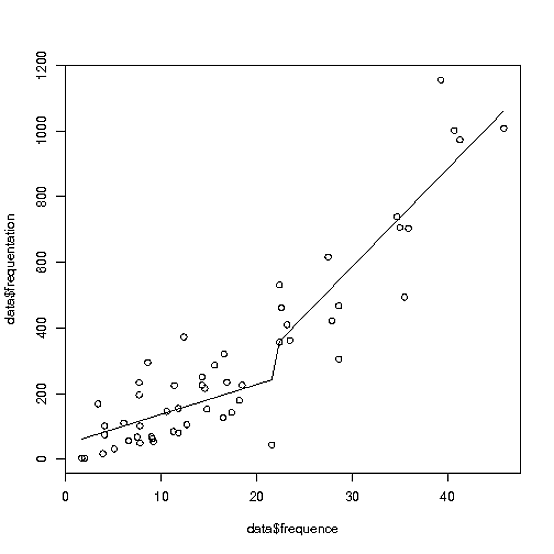
вот мои данные:
demand <- c(1155, 362, 357, 111, 703, 494, 410, 63, 616, 468, 973, 235,
180, 69, 305, 106, 155, 422, 44, 1008, 225, 321, 1001, 531, 143,
251, 216, 57, 146, 226, 169, 32, 75, 102, 4, 68, 102, 462, 295,
196, 50, 739, 287, 226, 706, 127, 85, 234, 153, 4, 373, 54, 81,
18)
offer <- c(39.3, 23.5, 22.4, 6.1, 35.9, 35.5, 23.2, 9.1, 27.5, 28.6, 41.3,
16.9, 18.2, 9, 28.6, 12.7, 11.8, 27.9, 21.6, 45.9, 11.4, 16.6,
40.7, 22.4, 17.4, 14.3, 14.6, 6.6, 10.6, 14.3, 3.4, 5.1, 4.1,
4.1, 1.7, 7.5, 7.8, 22.6, 8.6, 7.7, 7.8, 34.7, 15.6, 18.5, 35,
16.5, 11.3, 7.7, 14.8, 2, 12.4, 9.2, 11.8, 3.9)
3 ответов
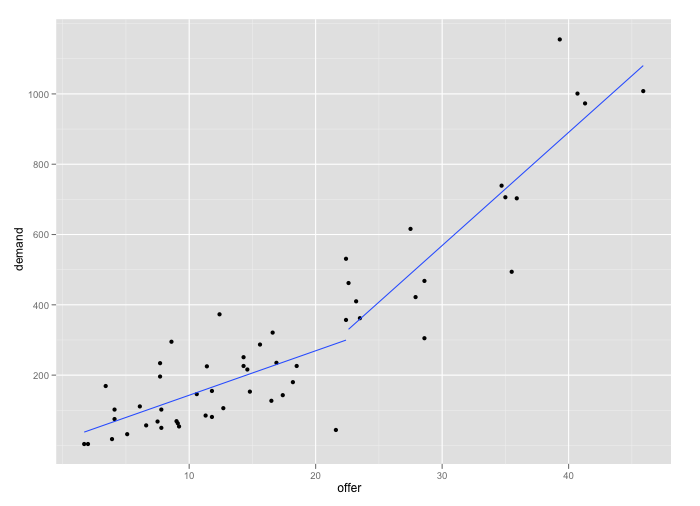
вот более простой подход, используя ggplot2.
require(ggplot2)
qplot(offer, demand, group = offer > 22.4, geom = c('point', 'smooth'),
method = 'lm', se = F, data = dat)
правка. Я бы также рекомендовал взглянуть на этот пакет segmented который поддерживает автоматическое обнаружение и оценку сегментированных регрессионных моделей.
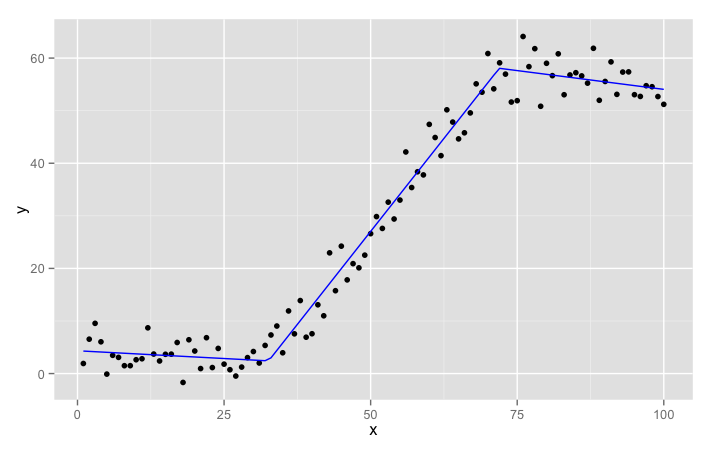
обновление:
вот пример, который использует пакет R сегментированный для автоматического обнаружения перерывов
library(segmented)
set.seed(12)
xx <- 1:100
zz <- runif(100)
yy <- 2 + 1.5*pmax(xx - 35, 0) - 1.5*pmax(xx - 70, 0) + 15*pmax(zz - .5, 0) +
rnorm(100,0,2)
dati <- data.frame(x = xx, y = yy, z = zz)
out.lm <- lm(y ~ x, data = dati)
o <- segmented(out.lm, seg.Z = ~x, psi = list(x = c(30,60)),
control = seg.control(display = FALSE)
)
dat2 = data.frame(x = xx, y = broken.line(o)$fit)
library(ggplot2)
ggplot(dati, aes(x = x, y = y)) +
geom_point() +
geom_line(data = dat2, color = 'blue')
Винсент держит вас на правильном пути. Единственное, что "странно" о линиях в вашем результирующем сюжете, это то, что lines проводит линию между каждого последовательная точка, что означает, что "прыжок" вы видите, если он просто соединяет два конца каждой линии.
Если вы не хотите этот разъем, вы должны разделить lines звонок на две отдельные части.
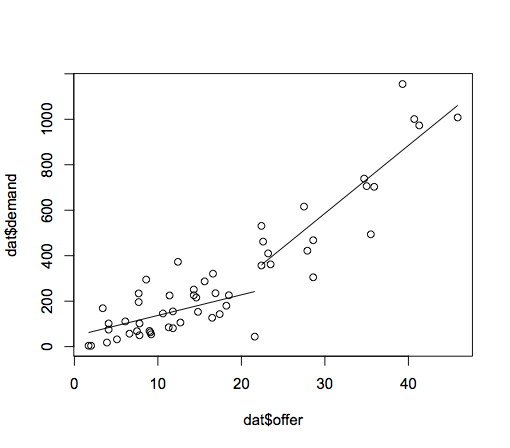
кроме того, я чувствую, что вы можете немного упростить свою регрессию. Вот что я сделал:
#After reading your data into dat
Break <- 22.4
dat$grp <- dat$offer < Break
#Note the addition of the grp variable makes this a bit easier to read
m <- lm(demand~offer*grp,data = dat)
dat$pred <- predict(m)
plot(dat$offer,dat$demand)
dat <- dat[order(dat$offer),]
with(subset(dat,offer < Break),lines(offer,pred))
with(subset(dat,offer >= Break),lines(offer,pred))
который производит этот сюжет:
странные линии просто из-за порядка, в котором точки строятся. Лучше должно выглядеть следующее:
i <- order(offer)
lines(offer[i], predict(model,list(offer))[i])
предупреждение исходит из того, что * символ интерпретируется lm.
> lm(demand~(offer<22.4)*offer + (offer>=22.4)*offer)
Call:
lm(formula = demand ~ (offer < 22.4) * offer + (offer >= 22.4) * offer)
Coefficients:
(Intercept) offer < 22.4TRUE offer
-309.46 356.08 29.86
offer >= 22.4TRUE offer < 22.4TRUE:offer offer:offer >= 22.4TRUE
NA -20.79 NA
кроме того, (offer<22.4)*offer является разрывной функцией:именно отсюда происходит разрыв.
следующая должна быть ближе к тому, что вы хотите.
model <- lm(
demand ~ ifelse(offer<22.4,offer-22.4,0)
+ ifelse(offer>=22.4,offer-22.4,0) )