Массив или список в Java. Что быстрее?
Я должен хранить тысячи строк в памяти для последовательного доступа в Java. Должен ли я хранить их в массиве или использовать какой-то список ?
поскольку массивы хранят все данные в непрерывном куске памяти (в отличие от списков), вызовет ли использование массива для хранения тысяч строк проблемы ?
ответ: общий консенсус заключается в том, что разница в производительности незначительна. Интерфейс списка обеспечивает большую гибкость.
30 ответов
Я предлагаю вам использовать профайлер, чтобы проверить что быстрее.
мое личное мнение, что вы должны использовать списки.
Я работаю над большой кодовой базой, а предыдущая группа разработчиков использовала массивы везде. Это делает код очень сложно. После изменения больших кусков его в списки мы не заметили никакой разницы в скорости.
путь Java заключается в том, что вы должны рассмотреть, какие данные абстрагирование наиболее соответствует вашим потребностям. Помните, что в Java список является абстрактным, а не конкретным типом данных. Вы должны объявить строки как список, а затем инициализировать его с помощью реализации ArrayList.
List<String> strings = new ArrayList<String>();
такое разделение абстрактного типа данных и конкретной реализации является одним из ключевых аспектов объектно-ориентированного программирования.
ArrayList реализует абстрактные данные списка Тип, использующий массив в качестве базовой реализации. Скорость доступа практически идентична массиву, с дополнительными преимуществами возможности добавления и вычитания элементов в список(хотя это операция O (n) с ArrayList), и что если вы решите изменить базовую реализацию позже, вы можете. Например, если вы понимаете, что вам нужен синхронизированный доступ, вы можете изменить реализацию на вектор без перезаписи всего кода.
в самом деле, ArrayList был специально разработан для замены низкоуровневой конструкции массива в большинстве контекстов. Если бы Java разрабатывался сегодня, вполне возможно, что массивы были бы полностью исключены в пользу конструкции ArrayList.
поскольку массивы хранят все данные в непрерывном куске памяти (в отличие от списков), вызовет ли использование массива для хранения тысяч строк проблемы ?
в Java все коллекции хранят только ссылки на объекты, а не сами объекты. Оба массива и ArrayList будут хранить несколько тысяч ссылок в непрерывном массиве, поэтому они по существу идентичны. Вы можете считать, что непрерывный блок из нескольких тысяч 32-битных ссылок всегда будет легко доступен на современном оборудовании. Это не гарантирует, что у вас не закончится память полностью, конечно, только то, что требование смежного блока памяти не сложно выполнить.
вы должны предпочесть общие типы массивам. Как упоминалось другими, массивы являются негибкими и не обладают выразительной силой общих типов. (Однако они поддерживают проверку типов во время выполнения, но это плохо сочетается с универсальными типами.)
но, как всегда, при оптимизации вы всегда должны следовать этим шагам:
- не оптимизируйте, пока у вас нет хорошего, чистого и работающего версия вашего кода. Переход на универсальные типы вполне может быть мотивация на этом этапе уже есть.
- когда у вас есть версия, которая хорошая и чистая, решите, достаточно ли она быстрая.
- если это не достаточно быстро, измерить его производительность. Этот шаг важен по двум причинам. Если вы не измеряете, вы не будете (1) знать влияние любых оптимизаций, которые вы делаете, и (2) знать, где оптимизировать.
- оптимизируйте самую горячую часть вашего кода.
- снова измерить. это так же важно, как измерять раньше. Если оптимизация не улучшила ситуацию,вернуться. Запомните, код без оптимизация была чистый, хороший и рабочий.
хотя ответы, предлагающие использовать ArrayList, имеют смысл в большинстве сценариев, фактический вопрос относительной производительности на самом деле не был дан ответ.
есть несколько вещей, которые вы можете сделать с массивом:
- создать
- установить элемент
- получить элемент
- клонировать/копировать
общий вывод
хотя операции get и set несколько медленнее на Коллекция ArrayList (респ. 1 и 3 наносекунды за вызов на моем компьютере),существует очень мало накладных расходов на использование ArrayList против массива для любого неинтенсивного использования. есть несколько вещей, чтобы иметь в виду:
- операции изменения размера в списке (при вызове
list.add(...)) являются дорогостоящими, и следует попытаться установить начальную емкость на достаточном уровне, когда это возможно (обратите внимание, что та же проблема возникает при использовании массива) - при работе с примитивы, массивы могут быть значительно быстрее, так как они позволят избежать многих конверсий бокса/распаковки
- приложение, которое получает / задает значения только в ArrayList (не очень распространено!) можно увидеть увеличение производительности более чем на 25% путем переключения на массив
подробные результаты
вот результаты, которые я измерил для этих трех операций с помощью jmh бенчмаркинг библиотека (раз в наносекундах) с JDK 7 на a стандартной архитектуры x86 компьютере. Обратите внимание, что ArrayList никогда не изменяется в тестах, чтобы убедиться, что результаты сопоставимы. контрольный код доступен здесь.
Создание Массива / ArrayList
я провел 4 теста, выполнив следующие инструкции:
- createArray1:
Integer[] array = new Integer[1]; - createList1:
List<Integer> list = new ArrayList<> (1); - createArray10000:
Integer[] array = new Integer[10000]; - createList10000:
List<Integer> list = new ArrayList<> (10000);
результаты (в наносекундах на вызов, 95% доверительный):
a.p.g.a.ArrayVsList.CreateArray1 [10.933, 11.097]
a.p.g.a.ArrayVsList.CreateList1 [10.799, 11.046]
a.p.g.a.ArrayVsList.CreateArray10000 [394.899, 404.034]
a.p.g.a.ArrayVsList.CreateList10000 [396.706, 401.266]
вывод: нет заметной разницы.
операции get
я провел 2 теста, выполнив следующие инструкции:
- getList:
return list.get(0); - getArray:
return array[0];
результаты (в наносекундах на вызов, 95% доверительный):
a.p.g.a.ArrayVsList.getArray [2.958, 2.984]
a.p.g.a.ArrayVsList.getList [3.841, 3.874]
вывод: получение из массива примерно на 25% быстрее чем получение от ArrayList, хотя разница составляет только порядка одной наносекунды.
набор операций
я провел 2 теста, выполнив следующие инструкции:
- setList:
list.set(0, value); - setArray:
array[0] = value;
результаты (в наносекундах на один вызов):
a.p.g.a.ArrayVsList.setArray [4.201, 4.236]
a.p.g.a.ArrayVsList.setList [6.783, 6.877]
заключение: набор операций с массивами составляет около 40% быстрее!--34--> чем в списках, но, что касается get, каждая операция набора занимает несколько наносекунд - поэтому для достижения разницы в 1 секунду нужно будет установить элементы в списке/массиве сотни миллионов раз!
клон/копию
делегаты конструктора копирования ArrayList в Arrays.copyOf таким образом, производительность идентична копии массива (копирование массива через clone, Arrays.copyOf или System.arrayCopy не делает никакой материальной разницы представление-мудрый).
Я предполагаю, что оригинальный плакат исходит из фона C++/STL, который вызывает некоторую путаницу. В C++ std::list представляет собой двухсвязный список.
В Java [java.util.]List - это интерфейс без реализации (чистый абстрактный класс в терминах C++). List может быть дважды связанный список -java.util.LinkedList - это предусмотрено. Тем не менее, 99 раз из 100, когда вы хотите сделать новый List, вы хотите использовать java.util.ArrayList вместо этого, что является грубым эквивалентом C++ std::vector. Есть и другие стандарты реализации, такие как возвращаемые java.util.Collections.emptyList() и java.util.Arrays.asList().
С точки зрения производительности есть очень маленький хит от необходимости проходить через интерфейс и дополнительный объект, однако во время выполнения подстановка означает, что это редко имеет какое-то значение. Также помните, что String обычно являются массивом object plus. Поэтому для каждой записи у вас, вероятно, есть еще два объекта. В C++ std::vector<std::string>, хотя копирование по значению без указателя как такового, массивы символов образуют объект для string (и они обычно не будут общими).
если этот конкретный код действительно чувствителен к производительности, вы можете создать один char[] массив (или даже byte[]) для всех символов всех строк, а затем массив смещений. IIRC, вот как реализуется javac.
Ну, во-первых, стоит уточнить, Вы имеете в виду" список " в классическом смысле структуры данных comp sci (т. е. связанный список) или вы имеете в виду java.утиль.Список? Если вы имеете в виду java.утиль.Лист, это интерфейс. Если вы хотите использовать массив, просто используйте реализацию ArrayList, и вы получите поведение и семантику, подобные массиву. Проблема решена.
Если вы имеете в виду массив против связанного списка, это немного другой аргумент, для которого мы возвращаемся к Big O (вот простом английском языке объяснение если это незнакомый термин.
массив;
- Произвольный Доступ: O (1);
- вставить: O (n);
- исключить: O (n).
Список Ссылок:
- произвольный доступ: O (n);
- Вставить: O (1);
- Исключить: O (1).
поэтому вы выбираете тот, который лучше всего подходит для изменения размера массива. Если вы изменяете размер, вставляете и удаляете много, то, возможно, связанный список хороший выбор. То же самое происходит, если случайный доступ редок. Вы упомянули серийный доступ. Если вы в основном делаете последовательный доступ с очень небольшой модификацией, то, вероятно, не имеет значения, какой вы выбираете.
связанные списки имеют немного более высокие накладные расходы, так как, как вы говорите, вы имеете дело с потенциально несмежными блоками памяти и (эффективно) указателями на следующий элемент. Это, вероятно,не является важным фактором, если вы не имеете дело с миллионами записей.
Я написал небольшой тест для сравнения ArrayLists с массивами. На моем старом ноутбуке время прохождения через 5000-элементный arraylist, 1000 раз, было примерно на 10 миллисекунд медленнее, чем эквивалентный код массива.
Итак, если вы ничего не делаете, кроме повторения списка, и вы делаете это много, то может быть это стоит оптимизации. В противном случае я бы использовал список, потому что это облегчит вам do нужно оптимизировать код.
Н.б. Я сделал обратите внимание, что с помощью for String s: stringsList был примерно на 50% медленнее, чем использование старого стиля for-loop для доступа к списку. Иди разберись... Вот две функции, которые я синхронизировал; массив и список были заполнены 5000 случайными (разными) строками.
private static void readArray(String[] strings) {
long totalchars = 0;
for (int j = 0; j < ITERATIONS; j++) {
totalchars = 0;
for (int i = 0; i < strings.length; i++) {
totalchars += strings[i].length();
}
}
}
private static void readArrayList(List<String> stringsList) {
long totalchars = 0;
for (int j = 0; j < ITERATIONS; j++) {
totalchars = 0;
for (int i = 0; i < stringsList.size(); i++) {
totalchars += stringsList.get(i).length();
}
}
}
Я согласен, что в большинстве случаев вы должны выбрать гибкость и элегантность ArrayLists над массивами - и в большинстве случаев влияние на производительность программы будет незначительным.
однако, если вы делаете постоянную, тяжелую итерацию с небольшим структурным изменением (без добавления и удаления) для, скажем, рендеринга программного обеспечения или пользовательской виртуальной машины, мои тесты последовательного доступа показывают, что ArrayLists на 1.5 x медленнее, чем arrays в моей системе (Java 1.6 на моем годовалом iMac).
код:
import java.util.*;
public class ArrayVsArrayList {
static public void main( String[] args ) {
String[] array = new String[300];
ArrayList<String> list = new ArrayList<String>(300);
for (int i=0; i<300; ++i) {
if (Math.random() > 0.5) {
array[i] = "abc";
} else {
array[i] = "xyz";
}
list.add( array[i] );
}
int iterations = 100000000;
long start_ms;
int sum;
start_ms = System.currentTimeMillis();
sum = 0;
for (int i=0; i<iterations; ++i) {
for (int j=0; j<300; ++j) sum += array[j].length();
}
System.out.println( (System.currentTimeMillis() - start_ms) + " ms (array)" );
// Prints ~13,500 ms on my system
start_ms = System.currentTimeMillis();
sum = 0;
for (int i=0; i<iterations; ++i) {
for (int j=0; j<300; ++j) sum += list.get(j).length();
}
System.out.println( (System.currentTimeMillis() - start_ms) + " ms (ArrayList)" );
// Prints ~20,800 ms on my system - about 1.5x slower than direct array access
}
}
нет, потому что технически, массив хранит только ссылки на строки. Сами строки располагаются в другом месте. Для тысячи элементов я бы сказал, что список будет лучше, он медленнее, но он предлагает большую гибкость и проще в использовании, особенно если вы собираетесь изменить их размер.
Если у вас есть тысячи, рассмотрите возможность использования дерева. Trie-это древовидная структура, которая объединяет общие префиксы хранимой строки.
например, если строки были
intern
international
internationalize
internet
internets
trie будет хранить:
intern
->
international
->
-> ize
net
->
->s
строки требуют 57 символов (включая нулевой Терминатор, '\0') для хранения, а также независимо от размера строкового объекта, который их содержит. (На самом деле, мы, вероятно, должны округлить все размеры до кратных 16, но...) Призывать это 57 + 5 = 62 байт, грубо говоря.
trie требует 29 (включая нулевой Терминатор, '\0') для хранения, плюс размер узлов trie, которые являются ссылкой на массив и список дочерних узлов trie.
для этого примера это, вероятно, выходит примерно одинаково; для тысяч это, вероятно, выходит меньше, пока у вас есть общие префиксы.
теперь, при использовании trie в другом коде, вам придется преобразовать в String, вероятно, используя StringBuffer в качестве промежуточный. Если многие строки используются сразу как строки, вне trie, это потеря.
но если вы используете только несколько в то время-скажем, чтобы посмотреть вещи в словаре-trie может сэкономить вам много места. Наверняка меньше места, чем хранение их в HashSet.
вы говорите, что обращаетесь к ним "последовательно" - если это означает последовательно по алфавиту, trie также, очевидно, дает вам алфавитный порядок бесплатно, если вы его повторяете глубина-первых.
обновление:
как отметил Марк, после прогрева JVM нет существенной разницы (несколько тестовых проходов). Проверено с повторно созданным массивом или даже новым пропуском, начинающимся с новой строки матрицы. С большой вероятностью этот знаковый простой массив с индексным доступом не должен использоваться в пользу коллекций.
еще первый 1-2 проходит простой массив в 2-3 раза быстрее.
ОРИГИНАЛЬНЫЙ ПОСТ:
слишком много слов для предмета, слишком простого для проверки. без каких-либо вопросов массив в несколько раз быстрее, чем любой контейнер класса. Я бегу по этому вопросу, ища Альтернативы для моего критического раздела производительности. Вот прототип кода, который я построил, чтобы проверить реальную ситуацию:
import java.util.List;
import java.util.Arrays;
public class IterationTest {
private static final long MAX_ITERATIONS = 1000000000;
public static void main(String [] args) {
Integer [] array = {1, 5, 3, 5};
List<Integer> list = Arrays.asList(array);
long start = System.currentTimeMillis();
int test_sum = 0;
for (int i = 0; i < MAX_ITERATIONS; ++i) {
// for (int e : array) {
for (int e : list) {
test_sum += e;
}
}
long stop = System.currentTimeMillis();
long ms = (stop - start);
System.out.println("Time: " + ms);
}
}
и вот ответ:
на основе массива (строка 16 активна):
Time: 7064
на основе списка (строка 17 активна):
Time: 20950
есть еще комментарии по "быстрее"? Это вполне понятно. Этот вопрос в том, когда около 3 раз быстрее лучше для Вас, чем гибкость списка. Но это уже другой вопрос.
Кстати я проверил, это тоже на основе вручную построены ArrayList. Почти такой же результат.
поскольку здесь уже есть много хороших ответов, я хотел бы дать вам некоторую другую информацию практического вида, которая сравнение производительности вставки и итерации : примитивный массив против связанного списка в Java.
это фактическая простая проверка производительности.
таким образом, результат будет зависеть от производительности машины.
исходный код, используемый для этого ниже:
import java.util.Iterator;
import java.util.LinkedList;
public class Array_vs_LinkedList {
private final static int MAX_SIZE = 40000000;
public static void main(String[] args) {
LinkedList lList = new LinkedList();
/* insertion performance check */
long startTime = System.currentTimeMillis();
for (int i=0; i<MAX_SIZE; i++) {
lList.add(i);
}
long stopTime = System.currentTimeMillis();
long elapsedTime = stopTime - startTime;
System.out.println("[Insert]LinkedList insert operation with " + MAX_SIZE + " number of integer elapsed time is " + elapsedTime + " millisecond.");
int[] arr = new int[MAX_SIZE];
startTime = System.currentTimeMillis();
for(int i=0; i<MAX_SIZE; i++){
arr[i] = i;
}
stopTime = System.currentTimeMillis();
elapsedTime = stopTime - startTime;
System.out.println("[Insert]Array Insert operation with " + MAX_SIZE + " number of integer elapsed time is " + elapsedTime + " millisecond.");
/* iteration performance check */
startTime = System.currentTimeMillis();
Iterator itr = lList.iterator();
while(itr.hasNext()) {
itr.next();
// System.out.println("Linked list running : " + itr.next());
}
stopTime = System.currentTimeMillis();
elapsedTime = stopTime - startTime;
System.out.println("[Loop]LinkedList iteration with " + MAX_SIZE + " number of integer elapsed time is " + elapsedTime + " millisecond.");
startTime = System.currentTimeMillis();
int t = 0;
for (int i=0; i < MAX_SIZE; i++) {
t = arr[i];
// System.out.println("array running : " + i);
}
stopTime = System.currentTimeMillis();
elapsedTime = stopTime - startTime;
System.out.println("[Loop]Array iteration with " + MAX_SIZE + " number of integer elapsed time is " + elapsedTime + " millisecond.");
}
}
результат производительности ниже :

помните, что ArrayList инкапсулирует массив, поэтому есть небольшая разница по сравнению с использованием примитивного массива (за исключением того, что список намного проще работать с java).
практически единственный раз, когда имеет смысл предпочесть массив ArrayList, - это когда вы храните примитивы, то есть byte, int и т. д., И вам нужна конкретная эффективность пространства, которую вы получаете с помощью примитивных массивов.
выбор массива против списка не так важен (учитывая производительность) в случае хранения строковых объектов. Поскольку и массив, и список будут хранить ссылки на строковые объекты, а не фактические объекты.
- Если количество строк почти постоянно, используйте массив (или ArrayList). Но если число слишком сильно меняется, вам лучше использовать LinkedList.
- Если есть (или будет) необходимость добавления или удаления элементов в середине, то у вас, безусловно, есть использовать LinkedList.
Если вы заранее знаете, как большие данные, то массив будет быстрее.
список более гибкий. Вы можете использовать ArrayList, который поддерживается массивом.
список медленнее массивов.Если вам нужна эффективность, используйте массивы.Если вам нужна гибкость, используйте список.
Это вы можете жить с фиксированным размером, массивы будут быстрее и потребуется меньше памяти.
Если вам нужна гибкость интерфейса списка с добавлением и удалением элементов, остается вопрос, какую реализацию Вы должны выбрать. Часто ArrayList рекомендуется и используется для любого случая, но также ArrayList имеет проблемы с производительностью, если элементы в начале или в середине списка должны быть удалены или вставлены.
поэтому вы можете захотеть иметь посмотрите наhttp://java.dzone.com/articles/gaplist-%E2%80%93-lightning-fast-list который вводит GapList. Эта новая реализация списка сочетает в себе сильные стороны ArrayList и LinkedList, что приводит к очень хорошей производительности почти для всех операций.
в зависимости от реализации. возможно, что массив примитивных типов будет меньше и эффективнее, чем ArrayList. Это связано с тем, что массив будет хранить значения непосредственно в непрерывном блоке памяти, а простейшая реализация ArrayList будет хранить указатели на каждое значение. Особенно на 64-битной платформе это может иметь огромное значение.
конечно, реализация jvm может иметь особый случай для этой ситуации, в которой если производительность будет такой же.
список является предпочтительным способом в java 1.5 и за его пределами, поскольку он может использовать дженерики. Массивы не могут иметь дженериков. Также массивы имеют заранее определенную длину, которая не может динамично развиваться. Инициализация массива с большим размером не является хорошей идеей. ArrayList-это способ объявить массив с дженериками, и он может динамически расти. Но если delete и insert используются чаще, то linked list является самой быстрой структурой данных.
массивы, рекомендуемые везде, где вы можете использовать их вместо списка, особенно если вы знаете, что количество и размер элементов не будут меняться.
см. Oracle Java best practice:http://docs.oracle.com/cd/A97688_16/generic.903/bp/java.htm#1007056
конечно, если вам нужно добавить или удалить объекты из коллекции много раз легко использовать списки.
ArrayList хранит свои элементы в Object[] массив и использовать нетипизированные toArray метод, который намного быстрее (синяя полоса), чем типизированный. Это typesafe, так как нетипизированный массив завернут в универсальный тип ArrayList<T> Это проверяется компилятором.
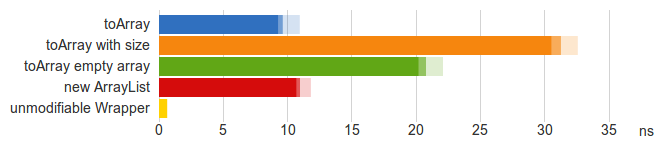
на этой диаграмме показан тест с n = 5 на Java 7. Однако изображение не сильно меняется с большим количеством элементов или другой виртуальной машиной. Накладные расходы CPU не могут показаться радикальными,но это складывается. Скорее всего, потребители массива должны преобразовать его в коллекцию, чтобы что-то с ним сделать, а затем преобразовать результат обратно в массив, чтобы передать его в другой метод интерфейса и т. д.
Используя простой ArrayList вместо массива улучшает производительность, не добавляя много места. ArrayList добавляет постоянные накладные расходы в 32 байта к обернутому массиву. Например,array десять объектов требует 104 байт ArrayList 136 байт.
эта операция выполняется в постоянное время, поэтому оно намного быстрее, чем любое из вышеперечисленных (желтая полоса). Это не то же самое, что защитная копия. Неизменяемая коллекция изменится при изменении внутренних данных. Если это произойдет, клиенты могут столкнуться с ConcurrentModificationException при повторении элементов. Можно считать плохим дизайном, что интерфейс предоставляет методы, которые бросают UnsupportedOperationException во время выполнения. Однако, по крайней мере для внутреннего использования, этот метод может быть высокопроизводительной альтернативой защитной копии-то, что не является возможно с массивами.
ни один из ответов не имел информации, которая меня интересовала-повторяющееся сканирование одного и того же массива много-много раз. Пришлось создать тест JMH для этого.
результаты (Java 1.8.0_66 x32, итерация простого массива по крайней мере в 5 раз быстрее, чем ArrayList):
Benchmark Mode Cnt Score Error Units
MyBenchmark.testArrayForGet avgt 10 8.121 ? 0.233 ms/op
MyBenchmark.testListForGet avgt 10 37.416 ? 0.094 ms/op
MyBenchmark.testListForEach avgt 10 75.674 ? 1.897 ms/op
тест
package my.jmh.test;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
import org.openjdk.jmh.annotations.Benchmark;
import org.openjdk.jmh.annotations.BenchmarkMode;
import org.openjdk.jmh.annotations.Fork;
import org.openjdk.jmh.annotations.Measurement;
import org.openjdk.jmh.annotations.Mode;
import org.openjdk.jmh.annotations.OutputTimeUnit;
import org.openjdk.jmh.annotations.Scope;
import org.openjdk.jmh.annotations.State;
import org.openjdk.jmh.annotations.Warmup;
@State(Scope.Benchmark)
@Fork(1)
@Warmup(iterations = 5, timeUnit = TimeUnit.SECONDS)
@Measurement(iterations = 10)
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
public class MyBenchmark {
public final static int ARR_SIZE = 100;
public final static int ITER_COUNT = 100000;
String arr[] = new String[ARR_SIZE];
List<String> list = new ArrayList<>(ARR_SIZE);
public MyBenchmark() {
for( int i = 0; i < ARR_SIZE; i++ ) {
list.add(null);
}
}
@Benchmark
public void testListForEach() {
int count = 0;
for( int i = 0; i < ITER_COUNT; i++ ) {
for( String str : list ) {
if( str != null )
count++;
}
}
if( count > 0 )
System.out.print(count);
}
@Benchmark
public void testListForGet() {
int count = 0;
for( int i = 0; i < ITER_COUNT; i++ ) {
for( int j = 0; j < ARR_SIZE; j++ ) {
if( list.get(j) != null )
count++;
}
}
if( count > 0 )
System.out.print(count);
}
@Benchmark
public void testArrayForGet() {
int count = 0;
for( int i = 0; i < ITER_COUNT; i++ ) {
for( int j = 0; j < ARR_SIZE; j++ ) {
if( arr[j] != null )
count++;
}
}
if( count > 0 )
System.out.print(count);
}
}
"тысячи" - это не большое число. Несколько тысяч строк длины абзаца имеют размер порядка пары мегабайт. Если все, что вы хотите сделать, это получить доступ к ним последовательно, используйте неизменяемый односвязный список.
Не попадайте в ловушку оптимизации без надлежащего бенчмаркинга. Как и другие предложили использовать профилировщик, прежде чем делать какие-либо предположения.
различные структуры данных, которые вы перечислили, имеют разные цели. Список очень эффективен при вставке элементов в начале и в конце, но сильно страдает при доступе к случайным элементам. Массив имеет фиксированное хранилище, но обеспечивает быстрый случайный доступ. Наконец, ArrayList улучшает интерфейс к массиву с помощью позволяя ему расти. Обычно используемая структура данных должна быть продиктована тем, как будут доступны или добавлены хранимые данные.
о потреблении памяти. Вы, кажется, смешивая некоторые вещи. Массив даст вам только непрерывный кусок памяти для типа данных, которые у вас есть. Не забывайте, что java имеет фиксированные типы данных: boolean, char, int, long, float и Object (это включает все объекты, даже массив является объектом). Это означает, что если вы объявляете массив string strings [1000] или MyObject myObjects [1000] вы получаете только 1000 ячеек памяти, достаточно больших для хранения местоположения (ссылок или указателей) объектов. Вы не получаете 1000 ящиков памяти, достаточно больших, чтобы соответствовать размеру объектов. Не забывайте, что ваши объекты сначала создаются "новые". Это когда распределение памяти сделано и позже ссылка (их адрес памяти) хранится в массиве. Объект не копируется в массив, только это ссылка.
Я не думаю, что это имеет реальное значение для строк. То, что является непрерывным в массиве строк, - это ссылки на строки, сами строки хранятся в случайных местах в памяти.
массивы и списки могут иметь значение для примитивных типов, а не для объектов. Если вы заранее знаете количество элементов и не нуждаетесь в гибкости, массив из миллионов целых чисел или двойников будет более эффективным в памяти и незначительно в скорости, чем список, потому что действительно они будут храниться непрерывно и доступны мгновенно. Вот почему Java по-прежнему использует массивы символов для строк, массивы ints для данных изображений и т. д.
много микробных меток, приведенных здесь, нашли числа в несколько наносекунд для таких вещей, как чтение массива/ArrayList. Это вполне разумно, если все в кэше L1.
кэш более высокого уровня или доступ к основной памяти может иметь порядок раз что-то вроде 10nS-100nS, против больше, как 1nS для кэша L1. Доступ к ArrayList имеет дополнительную косвенную память, и в реальном приложении вы можете заплатить эту стоимость от почти никогда до каждого раза, в зависимости о том, что ваш код делает между доступами. И, конечно, если у вас много маленьких ArrayLists, это может добавить к вашей памяти и сделать его более вероятным, у вас будут промахи кэша.
оригинальный плакат, похоже, использует только один и получает доступ к большому количеству содержимого за короткое время, поэтому это не должно быть большим трудом. Но это может быть по-другому для других людей, и вы должны следить за интерпретацией микробных меток.
строки Java, однако, ужасающе расточительно, особенно если вы храните много маленьких (просто посмотрите на них с помощью анализатора памяти, кажется, > 60 байт для строки из нескольких символов). Массив строк имеет косвенное отношение к объекту String, а другой-от объекта String к char [], который содержит саму строку. Если что-то собирается взорвать ваш кэш L1, это в сочетании с тысячами или десятками тысяч строк. Итак, если вы серьезно-действительно серьезно - о выскабливании столько производительности, сколько возможно, тогда вы могли бы посмотреть на это по-другому. Вы можете, скажем, держать два массива, char[] со всеми строками в нем, один за другим, и int[] с смещениями к началу. Это будет Пита для чего угодно, и вам почти наверняка она не понадобится. И если да, то вы выбрали не тот язык.
Я пришел сюда, чтобы получить лучшее представление о влиянии на производительность использования списков над массивами. Мне пришлось адаптировать код здесь для моего сценария: массив / список ~1000 ints, используя в основном геттеры, что означает array[j] против list.get (j)
принимая лучшее из 7, чтобы быть ненаучным об этом (первые несколько со списком, где 2.5 x медленнее), я получаю это:
array Integer[] best 643ms iterator
ArrayList<Integer> best 1014ms iterator
array Integer[] best 635ms getter
ArrayList<Integer> best 891ms getter (strange though)
- итак, очень примерно на 30% быстрее с array
вторая причина публикации сейчас заключается в том, что никто не упоминает влияние, если вы делаете математику / матрицу / моделирование / оптимизационный код с вложенные петли.
скажем, у вас есть три вложенных уровня, и внутренний цикл в два раза медленнее, чем вы смотрите на 8 раз. Что-то, что будет работать в день, теперь занимает неделю.
*редактировать Довольно шокирован здесь, для пинков я попытался объявить int[1000] а не Integer[1000]
array int[] best 299ms iterator
array int[] best 296ms getter
использование Integer [] vs. int [] представляет собой двойной хит производительности, ListArray с итератором - 3x медленнее, чем int[]. Действительно думал, что реализации списка Java были похожи на собственные массивы...
код для справки (звоните несколько раз):
public static void testArray()
{
final long MAX_ITERATIONS = 1000000;
final int MAX_LENGTH = 1000;
Random r = new Random();
//Integer[] array = new Integer[MAX_LENGTH];
int[] array = new int[MAX_LENGTH];
List<Integer> list = new ArrayList<Integer>()
{{
for (int i = 0; i < MAX_LENGTH; ++i)
{
int val = r.nextInt();
add(val);
array[i] = val;
}
}};
long start = System.currentTimeMillis();
int test_sum = 0;
for (int i = 0; i < MAX_ITERATIONS; ++i)
{
// for (int e : array)
// for (int e : list)
for (int j = 0; j < MAX_LENGTH; ++j)
{
int e = array[j];
// int e = list.get(j);
test_sum += e;
}
}
long stop = System.currentTimeMillis();
long ms = (stop - start);
System.out.println("Time: " + ms);
}
Это зависит от того, как вы должны получить к нему доступ.
после хранения, Если вы в основном хотите выполнить операцию поиска, с небольшим количеством или без вставки / удаления, перейдите к массиву(как поиск выполняется в O (1) в массивах, тогда как добавление/удаление может потребовать повторного упорядочения элементов).
после хранения, Если ваша основная цель-добавить / удалить строки, с небольшим или без операции поиска, перейдите к списку.
ArrayList внутренне использует объект array для добавления (или хранения) элементы. Другими словами, ArrayList поддерживается данными массива -структура.Массив ArrayList является изменяемым (или динамическим).
Array быстрее, чем Array потому что ArrayList внутренне использует массив. если мы можем напрямую добавлять элементы в массив и косвенно добавлять элемент в Массив через ArrayList всегда напрямую механизм быстрее, чем косвенно механизм.
в классе ArrayList есть два перегруженных метода add ():
1. add(Object) : добавляет объект в конец списка.
2. add(int index , Object ): вставляет указанный объект в указанное положение в списке.
как размер ArrayList растет динамически?
public boolean add(E e)
{
ensureCapacity(size+1);
elementData[size++] = e;
return true;
}
важным моментом, который следует отметить из приведенного выше кода, является то , что мы проверяем емкость ArrayList перед добавлением элемента. ensureCapacity() определяет текущий размер занятых элементов и максимальный размер массива. Если размер заполненных элементов (включая новый элемент, добавляемый в класс ArrayList) больше максимального размера массива, увеличьте размер массива. Но размер массива не может быть динамически увеличена. Итак, что происходит внутри, новый массив создается с емкостью
До Java 6
int newCapacity = (oldCapacity * 3)/2 + 1;
(Обновление) С Java 7
int newCapacity = oldCapacity + (oldCapacity >> 1);
кроме того, данные из старого массива копируются в новый массив.
имея накладные методы в ArrayList, поэтому Array быстрее, чем ArrayList.