модуле itertools.groupby в шаблоне django
у меня странная проблема с использованием itertools.groupby для группировки элементов набора запросов. У меня есть модель Resource:
from django.db import models
TYPE_CHOICES = (
('event', 'Event Room'),
('meet', 'Meeting Room'),
# etc
)
class Resource(models.Model):
name = models.CharField(max_length=30)
type = models.CharField(max_length=5, choices=TYPE_CHOICES)
# other stuff
у меня есть несколько ресурсов в моей базе данных sqlite:
>>> from myapp.models import Resource
>>> r = Resource.objects.all()
>>> len(r)
3
>>> r[0].type
u'event'
>>> r[1].type
u'meet'
>>> r[2].type
u'meet'
поэтому, если я группирую по типу, я, естественно, получаю два кортежа:
>>> from itertools import groupby
>>> g = groupby(r, lambda resource: resource.type)
>>> for type, resources in g:
... print type
... for resource in resources:
... print 't%s' % resource
event
resourcex
meet
resourcey
resourcez
теперь у меня такая же логика, на мой взгляд:
class DayView(DayArchiveView):
def get_context_data(self, *args, **kwargs):
context = super(DayView, self).get_context_data(*args, **kwargs)
types = dict(TYPE_CHOICES)
context['resource_list'] = groupby(Resource.objects.all(), lambda r: types[r.type])
return context
но когда я повторяю это в своем шаблоне, некоторые ресурсы отсутствуют:
<select multiple="multiple" name="resources">
{% for type, resources in resource_list %}
<option disabled="disabled">{{ type }}</option>
{% for resource in resources %}
<option value="{{ resource.id }}">{{ resource.name }}</option>
{% endfor %}
{% endfor %}
</select>
это делает as:
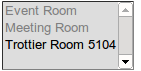
Я думаю, что каким-то образом субитераторы уже повторяются, но я не уверен, как это может произойти.
(используя python 2.7.1, Django 1.3).
(EDIT: если кто-то читает это, я бы рекомендовал использовать встроенный regroup тег шаблона вместо groupby.)
2 ответов
Я думаю, что вы правы. Я не понимаю, почему, но мне кажется ваш groupby итератор выполняется предварительная итерация. Это проще объяснить с помощью кода:
>>> even_odd_key = lambda x: x % 2
>>> evens_odds = sorted(range(10), key=even_odd_key)
>>> evens_odds_grouped = itertools.groupby(evens_odds, key=even_odd_key)
>>> [(k, list(g)) for k, g in evens_odds_grouped]
[(0, [0, 2, 4, 6, 8]), (1, [1, 3, 5, 7, 9])]
пока все хорошо. Но что происходит, когда мы пытаемся сохранить содержимое итератора в списке?
>>> evens_odds_grouped = itertools.groupby(evens_odds, key=even_odd_key)
>>> groups = [(k, g) for k, g in evens_odds_grouped]
>>> groups
[(0, <itertools._grouper object at 0x1004d7110>), (1, <itertools._grouper object at 0x1004ccbd0>)]
конечно, мы только что кэшировали результаты, и итераторы все еще хороши. Правильно? Неправильный.
>>> [(k, list(g)) for k, g in groups]
[(0, []), (1, [9])]
в процессе получения ключей, группы повторяемых свыше. Поэтому мы просто кэшировали ключи и выбрасывали группы, сохраняя самый последний элемент.
Я не знаю, как django обрабатывает итераторы, но исходя из этого, моя догадка заключается в том, что он кэширует их как списки внутри. Вы могли бы хотя бы частично подтвердить эту интуицию, выполнив вышеизложенное, но с большим количеством ресурсов. Если единственный отображаемый ресурс является последним, то у вас почти наверняка есть вышеуказанная проблема где-то.
шаблоны Django хотят знать длину вещей, которые зациклены на использовании {% for %}, но генераторы не имеют длины.
поэтому Django решает преобразовать его в список перед итерацией, чтобы он имел доступ к списку.
это ломает генераторы, созданные с помощью itertools.groupby. Если вы не будете перебирать каждую группу, вы потеряете содержимое. Вот пример от разработчика Django core Алекса Гейнора первый нормальный метод groupBy:
>>> groups = itertools.groupby(range(10), lambda x: x < 5)
>>> print [list(items) for g, items in groups]
[[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]
вот что делает Django; он преобразует генератор в список:
>>> groups = itertools.groupby(range(10), lambda x: x < 5)
>>> groups = list(groups)
>>> print [list(items) for g, items in groups]
[[], [9]]
есть два способа обойти это: преобразовать в список, прежде чем Django делает или предотвратить Django от этого.
преобразование в список себя
как показано ниже:
[(grouper, list(values)) for grouper, values in my_groupby_generator]
но, конечно, у вас больше нет преимуществ использования генератора, если это проблема для вас.
предотвращение преобразования Django в список
другой способ обойти это, чтобы обернуть его в объект, который обеспечивает __len__ метод (если вы знаете, какая длина будет):
class MyGroupedItems(object):
def __iter__(self):
return itertools.groupby(range(10), lambda x: x < 5)
def __len__(self):
return 2
Django сможет получить длину, используя len() и не нужно конвертировать ваш генератор в список. Жаль, что Джанго это делает. Мне повезло, что я мог использовать этот обходной путь, так как я уже использовал такой объект и знал, какой длины всегда будет.