Может ли кто-нибудь привести реальный пример контролируемого обучения и бесконтрольного обучения?
недавно я изучал о контролируемом обучении и бесконтрольном обучении. Из теории я знаю, что под наблюдением подразумевается получение информации из помеченных наборов данных, а без надзора-кластеризация данных без каких-либо меток.
но проблема в том, что я всегда путаюсь, чтобы определить, является ли данный пример контролируемым обучением или неконтролируемым обучением во время моих занятий.
может ли кто-нибудь привести пример реальной жизни?
6 ответов
обучающийся:
- вы получаете кучу фотографий С informaton что на них и вы обучаете модель распознавать новые фотографии
- у вас есть куча молекул и информация, что наркотики и вы тренируете модель, чтобы ответить, является ли новая молекула также лекарством
обучение без учителя:
- у вас есть куча фотографий 6 человек, но без информации кто на какой один и хотите разделить этот набор данных в 6 свай, каждая с фотографиями одного человека
- у вас есть молекулы, часть из них-это лекарства, а не но вы не знаете, какие из них какие и вы хотите алгоритм, чтобы обнаружить наркотики
Обучающийся
Это просто, и вы бы сделали это несколько раз, например:
- Cortana или любая автоматизированная система речи в вашем мобильном телефоне тренирует ваш голос, а затем начинает работать на основе этого обучения.
- на основе различных функций (прошлые записи голова к голове, шаг, бросок, игрок против игрока) Оса прогнозирует выигрышный % обеих команд.
- обучите свой почерк OCR система и после обучения, она сможет конвертировать ваши рукописные изображения в текст (до некоторой точности, очевидно)
- основанный на некотором предварительном знании (когда свое солнечное, температура выше; когда свое пасмурное, влажность выше, ЕТК.) погодные приложения прогнозируют параметры в течение заданного времени.
на основе прошлой информации о спам, фильтрации нового входящего письма в почтовый (нормальная) или папка нежелательной почты (Спам)
биометрическая посещаемость или системы АТМ ЕТК где вы тренируете машину после пары входных сигналов (вашей биометрической идентичности - будь то большой палец или радужка или мочка уха, ЕТК.), машина может проверить ваш будущий входной сигнал и определить вас.
Обучение Без Учителя
друг приглашает вас на вечеринку, где вы встретите совершенно незнакомых людей. Теперь вы классифицируете их с помощью неконтролируемого обучения (без предварительного знание), и эта классификация может быть на основе пола, возрастной группы, одежды, образовательной квалификации или любым другим способом. почему это обучение отличается от обучения? Поскольку вы не использовали никаких прошлых/предварительных знаний о людях и классифицировали их "на ходу".
NASA обнаруживает новые небесные тела и находит их отличными от ранее известные астрономические объекты - звезды, планеты, астероиды, черной дыре двое и т. д. (т. е. не знает об этих новых телах) и классифицирует их так, как хотелось бы (расстояние от Млечного Пути, интенсивность, гравитационная сила, красное/синее смещение или что-то еще)
предположим, вы никогда раньше не видели крикетный матч и случайно смотрите видео в интернете, теперь вы можете классифицировать игроков на основе разных критериев: игроки, носящие одинаковые наборы, находятся в одном классе, игроки одного стиля находятся в одном классе (бэтсмены, Боулер, филдеры) или на поле. основа игровой руки (RH vs LH) или каким бы образом вы ни наблюдали [и классифицировали] ее.
мы проводим опрос 500 вопросов о прогнозировании уровня IQ студентов в колледже. Поскольку эта анкета слишком велика, поэтому после 100 студентов администрация решает сократить анкету до меньшего количества вопросов, и для этого мы используем некоторую статистическую процедуру, такую как PCA чтобы обрезать его.
Я надеюсь, что эти пару примеры объясняют разницу в деталях.
Обучающийся:
- это как учиться у учителя
- набор данных обучения похож на учителя
- набор данных обучения используется для обучения машины
пример:
классификация: машина обучена классифицировать что-то в некоторый класс.
- классификация имеет ли пациент болезнь или нет
- классифицировать, является ли письмо спамом или нет
регрессия: машина натренирована для того чтобы предсказать некоторое значение как цена, вес или высота.
- прогнозирование цены на дом / недвижимость
- прогнозирование цены фондового рынка
Обучение Без Учителя:
- это как учиться без учителя
- машины узнает посредством наблюдения и найти структуры в данных
пример:
кластеризации: проблема кластеризации заключается в том, где вы хотите обнаружить присущие группировки в данных
- например, группировка клиентов по покупательскому поведению
Обучающийся
контролируемое обучение довольно часто встречается в проблемах классификации, потому что цель часто состоит в том, чтобы заставить компьютер изучить систему классификации, которую мы создали. Распознавание цифр, еще раз, является распространенным примером обучения классификации. В более общем плане изучение классификации подходит для любой проблемы, где вывод классификации полезен, и классификацию легко определить. В некоторых случаях это может даже не необходимо дать заранее определенные классификации каждому экземпляру проблемы, если агент может разработать классификации для себя. Это было бы примером неконтролируемого обучения в контексте классификации.
обучения является наиболее распространенным методом для обучения нейронных сетей и деревьев решений. Оба эти метода в значительной степени зависят от информации, предоставляемой заранее определенными классификациями. В случае нейронных сетей, классификация используется для определения ошибки сети, а затем настройки сети для ее минимизации, а в деревьях решений классификации используются для определения того, какие атрибуты предоставляют наибольшую информацию, которая может быть использована для решения головоломки классификации. Мы рассмотрим их более подробно, но пока достаточно знать, что оба эти примера процветают благодаря некоторому "надзору" в форме предопределенных классификаций.
распознавание речи с помощью скрытые марковские модели и байесовские сети опираются на некоторые элементы наблюдения, а также для настройки параметров, чтобы, как обычно, минимизировать ошибку на заданных входах.
заметили кое-что важное: в задаче классификации, целью алгоритма обучения является минимизация ошибки по отношению к данному входов. Эти входные данные, часто называемые "обучающим набором", являются примерами, из которых агент пытается учиться. Но обучение в обучающей выборке не обязательно лучшее, что можно сделать. Например, если бы я попытался научить вас исключительному-или, но только показал вам комбинации, состоящие из одного истинного и одного ложного, но никогда оба ложных или оба истинных, вы могли бы узнать правило, что ответ всегда истинен. Аналогично, с алгоритмами машинного обучения общей проблемой является чрезмерная подгонка данных и, по существу, запоминание учебного набора, а не изучение более общей Методики классификации.
без присмотра Обучение
бесконтрольное обучение кажется намного сложнее: цель состоит в том, чтобы компьютер научился делать то, что мы не говорим ему, как это сделать! На самом деле существует два подхода к неконтролируемому обучению. Первый подход состоит в том, чтобы научить агента не давать явных классификаций, а использовать какую-то систему вознаграждения, чтобы показать успех. Обратите внимание, что этот тип обучения, как правило, вписывается в рамки решения проблемы, потому что цель не заключается в создании классификация, но принимать решения, которые максимизируют вознаграждение. Этот подход хорошо обобщает реальный мир, где агенты могут быть вознаграждены за определенные действия и наказаны за другие.
часто форма обучения подкреплению может использоваться для неконтролируемого обучения, где агент основывает свои действия на предыдущих наградах и наказаниях, даже не обязательно изучая какую-либо информацию о точных способах, которыми его действия влияют на мир. В некотором смысле, все это информация не нужна, потому что, изучая функцию вознаграждения, агент просто знает, что делать без какой-либо обработки, потому что он знает точную награду, которую он ожидает получить за каждое действие, которое он может предпринять. Это может быть чрезвычайно полезно в тех случаях, когда вычисление каждой возможности занимает очень много времени (даже если все вероятности перехода между мировыми государствами были известны). С другой стороны, это может быть очень много времени, чтобы узнать, по существу, проб и ошибка.
но этот вид обучения может быть мощным, потому что он не предполагает заранее открытой классификации примеров. В некоторых случаях, например, наши классификации могут быть не самыми лучшими. Одним из поразительных примеров является то, что общепринятая мудрость об игре в нарды была перевернута с ног на голову, когда серия компьютерных программ (нейро-гаммон и TD-гаммон), которые учились через бесконтрольное обучение, стали сильнее, чем лучшие шахматисты просто играя себя снова и снова. Эти программы открыли некоторые принципы, которые удивили экспертов по нардам и работали лучше, чем программы по нардам, обученные на заранее засекреченных примерах.
второй тип неконтролируемого обучения называется кластеризацией. В этом типе обучения цель заключается не в максимизации функции полезности, а просто в поиске сходства в данных обучения. Часто предполагается, что обнаруженные кластеры будут достаточно хорошо сочетаться с интуитивным классификация. Например, объединение людей в группы на основе демографических данных может привести к объединению богатых в одну группу и бедных в другую.
обучающийся имеет вход и правильный выход. например: у нас есть данные, если человеку понравился фильм или нет. На основе опроса людей и сбора их ответов, понравился им фильм или нет, мы собираемся предсказать, будет ли фильм хитом или нет.
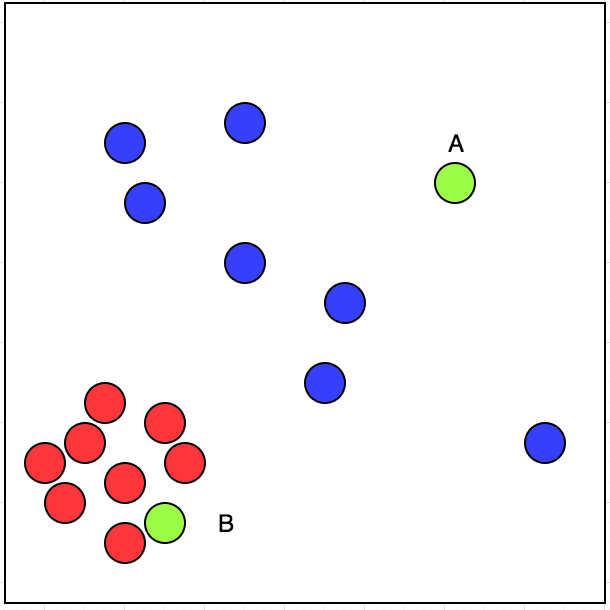
давайте посмотрим на изображение в ссылке выше. Я посетил рестораны, отмеченные красным кругом. Рестораны, которые я не посещал, отмечены синий круг.
теперь, если у меня есть два ресторана на выбор, A и B, отмеченные зеленым цветом, какой из них я выберу?
простой. Мы можем классифицировать данные линейно на две части. Это означает, что мы можем провести линию, разделяющую красный и синий круги. Посмотрите на картинку в ссылке ниже:
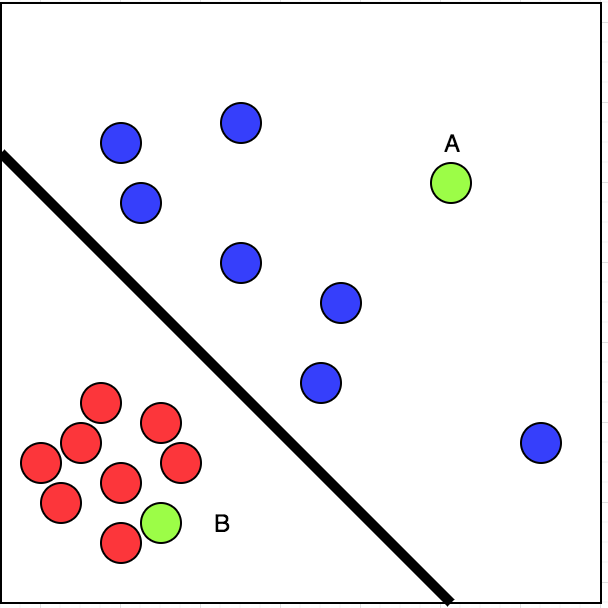
теперь мы можем с некоторой уверенностью сказать, что шансы моего посещения B больше, чем A. Это случай контролируемого обучающий.
неконтролируемое обучение имеет входные данные. предположим, у нас есть таксист, у которого есть возможность принять или отклонить заказы. Мы нанесли его принятое местоположение бронирования на карту с синим кругом и показано ниже:
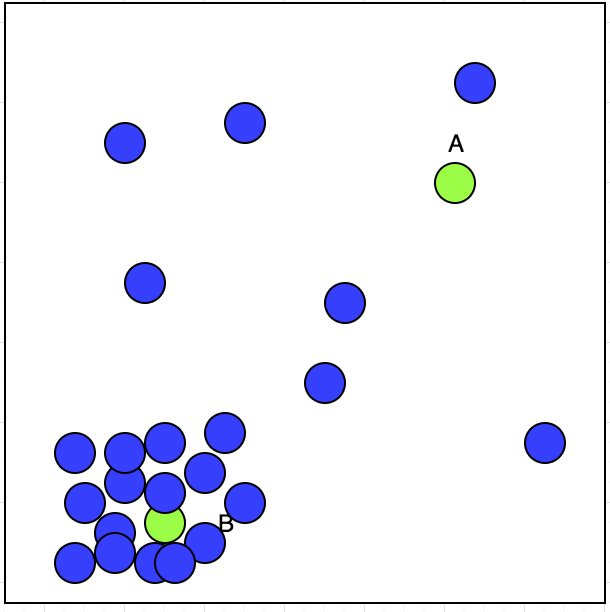
теперь у таксиста есть два заказа A и B; какой из них он примет? Если мы рассмотрим сюжет, мы увидим, что его принятое бронирование показывает кластер в левом нижнем углу. Это можно показать в изображение ниже:
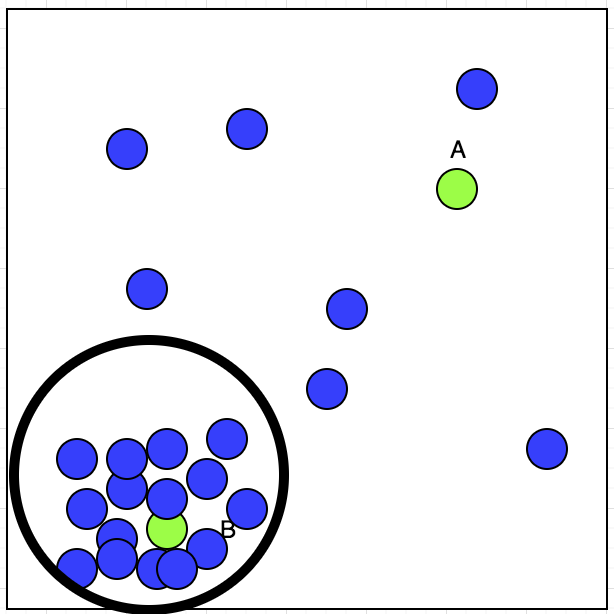
контролируемое обучение: проще говоря, у вас есть определенные входы и ожидайте некоторых результатов. Например, у вас есть данные фондового рынка, которые из предыдущих данных и получить результаты текущего ввода в течение следующих нескольких лет, давая некоторые инструкции он может дать вам необходимый выход.
бесконтрольное обучение: у вас есть такие параметры, как цвет, тип, размер чего-то, и вы хотите, чтобы программа предсказывала, что это фрукт, растение, животное или что-то еще, это где Приходит надзиратель. Это дает вам выход, принимая некоторые входы.