Можно ли использовать scrapy для очистки динамического контента с веб-сайтов, использующих AJAX?
недавно я изучал Python и погружаю руку в создание веб-скребка. Это ничего особенного; его единственная цель-получить данные с веб-сайта ставок и поместить эти данные в Excel.
большинство проблем разрешимы, и у меня есть хороший маленький беспорядок. Однако я столкнулся с огромным препятствием по одному вопросу. Если сайт загружает таблицу лошадей и перечисляет текущие цены ставок, эта информация не находится ни в одном исходном файле. Ключ в том, что эти данные иногда живут, причем номера обновляются, очевидно, с какого-то удаленного сервера. HTML на моем ПК просто имеет отверстие, где их серверы проталкивают все интересные данные, которые мне нужны.
теперь мой опыт работы с динамическим веб-контентом низок, поэтому у меня возникли проблемы с головой.
Я думаю, что Java или Javascript-это ключ, это часто всплывает.
скребок-это просто механизм сравнения шансов. Некоторые у сайтов есть API, но мне это нужно для тех, кто этого не делает. Я использую библиотеку scrapy с Python 2.7
Я прошу прощения, если этот вопрос слишком открытый. Короче говоря, мой вопрос: как scrapy можно использовать для очистки этих динамических данных, чтобы я мог их использовать? Так что я могу наскрести эти данные ставок в режиме реального времени?
7 ответов
браузеры на основе Webkit (например, Google Chrome или Safari) имеют встроенные инструменты разработчика. В Chrome вы можете открыть его Menu->Tools->Developer Tools. The Network вкладка позволяет просматривать всю информацию о каждом запросе и ответе:
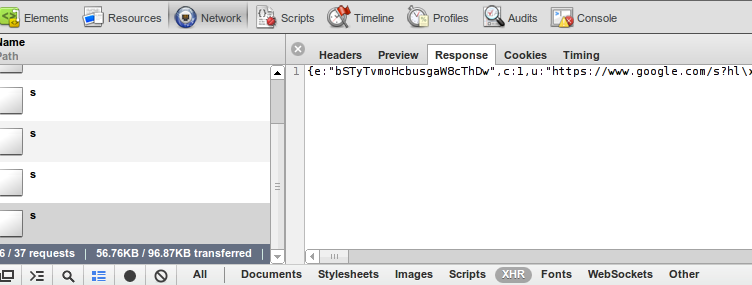
в нижней части изображения вы можете видеть, что я отфильтровал запрос до XHR - это запросы, выполняемые кодом javascript.
Совет: журнал очищается каждый раз, когда вы загружаете страницу, в нижней части картины, кнопка black dot сохранит журнал.
после анализа запросов и ответов вы можете имитировать эти запросы из своего веб-искателя и извлекать ценные данные. Во многих случаях будет проще получить ваши данные, чем синтаксический анализ HTML, потому что эти данные не содержат логики представления и отформатированы для доступа к коду javascript.
Firefox имеет аналогичное расширение, оно называется firebug. Некоторые будут утверждать, что firebug еще более мощный, но Мне нравится простота webkit.
вот простой пример использования scrapy с ajax-запросом. Пусть посмотреть сайт http://www.rubin-kazan.ru/guestbook.html Все сообщения загружаются с запросом ajax. Моя цель-получить эти сообщения со всеми их атрибутами (автор, дата,...).
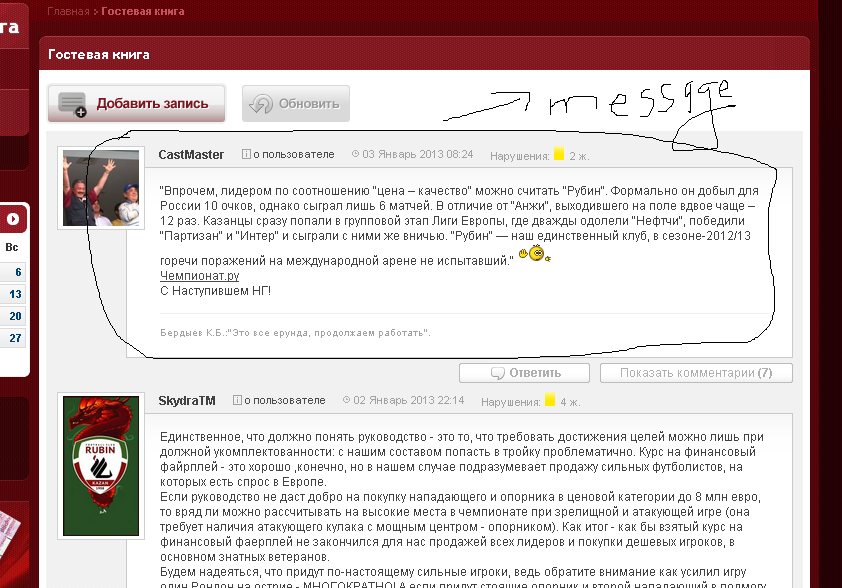
когда я анализирую исходный код страницы, я не вижу всех этих сообщений, потому что веб-страница использует технологию ajax. Но я могу с Firebug из Mozila Firefox (или аналоговый инструмент в другом браузере) для анализа Http-запроса, который генерирует сообщения на веб-странице.
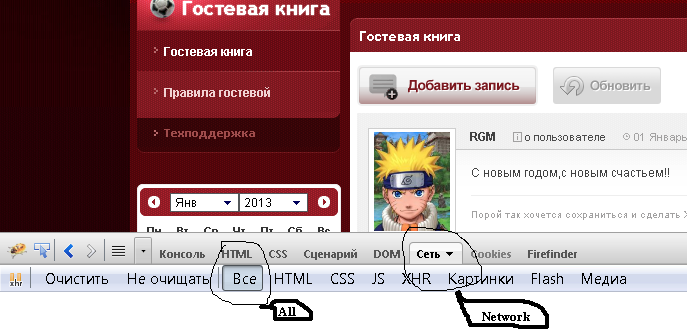
для этой цели я не перезагружаю всю страницу, а только часть страницы, содержащую сообщения. Для этого я нажимаю произвольное количество страниц внизу  и я наблюдаю HTTP-запрос, который отвечает за тело сообщения
и я наблюдаю HTTP-запрос, который отвечает за тело сообщения
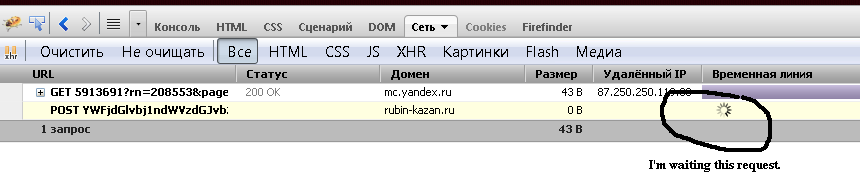
после завершения Я анализирую заголовки запроса (я должен процитировать, что этот url я извлеку из исходной страницы из var раздел, см. код ниже).
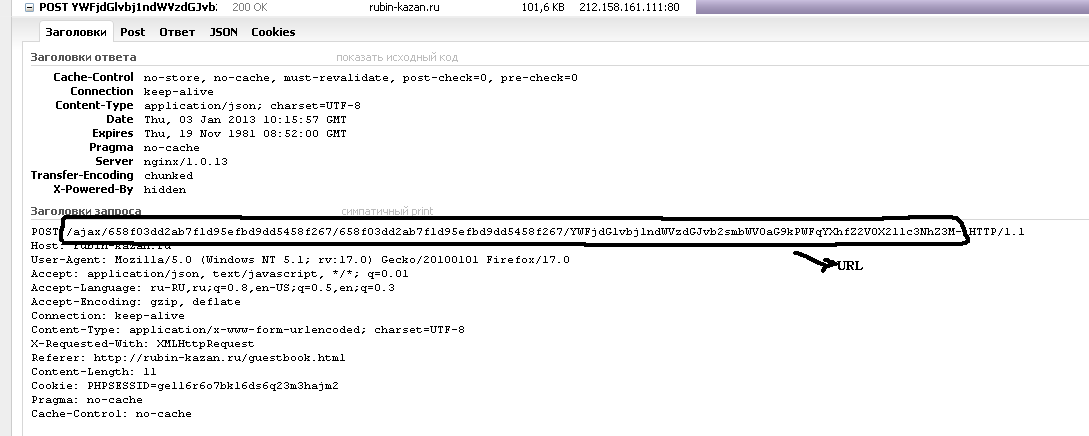
и содержание данных формы запроса (метод Http "Post")
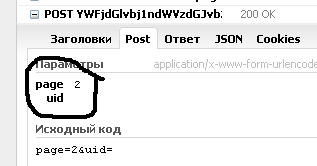
и содержание ответа, который является файлом Json,
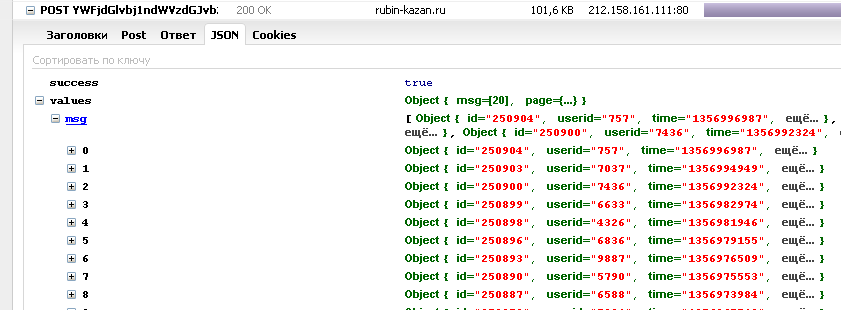
, которые представляют всю информацию я ищу.
теперь я должен реализовать все эти знания в scrapy. Давайте определим паука для этой цели.
class spider(BaseSpider):
name = 'RubiGuesst'
start_urls = ['http://www.rubin-kazan.ru/guestbook.html']
def parse(self, response):
url_list_gb_messages = re.search(r'url_list_gb_messages="(.*)"', response.body).group(1)
yield FormRequest('http://www.rubin-kazan.ru' + url_list_gb_messages, callback=self.RubiGuessItem, formdata={'page': str(page + 1), 'uid': ''})
def RubiGuessItem(self, response):
json_file = response.body
в функции parse у меня есть ответ для первого запрос. В RubiGuessItem у меня есть файл json со всей информацией.
много раз при обходе мы сталкиваемся с проблемами, когда контент, отображаемый на странице, генерируется с помощью Javascript, и поэтому scrapy не может его сканировать (например. запросы ajax, безумие jQuery).
однако, если вы используете Scrapy вместе с Selenium Платформы веб-тестирования, то мы можем сканировать все, что отображается в обычном веб-браузере.
обратите внимание:
у вас должна быть версия Selenium RC на Python установлено для этого, чтобы работать, и вы должны правильно настроить Selenium. Также это просто искатель шаблонов. Вы могли бы стать намного более сумасшедшим и продвинутым с вещами, но я просто хотел показать основную идею. Поскольку код стоит сейчас, вы будете делать два запроса для любого заданного url. Один запрос сделан Scrapy и другое сделано селеном. Я уверен, что есть способы обойти это, так что вы могли бы просто сделать Selenium сделать один и единственный запрос, но я не потрудился реализовать что и делаем два запроса вам сканировать страницу с Scrapy.
-
Это довольно мощно, потому что теперь у вас есть весь визуализированный DOM, доступный для обхода, и вы все еще можете использовать все приятные функции обхода в Scrapy. Это, конечно, замедлит ползание, но в зависимости от того, насколько вам нужен визуализированный DOM, это может стоить ожидания.
from scrapy.contrib.spiders import CrawlSpider, Rule from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor from scrapy.selector import HtmlXPathSelector from scrapy.http import Request from selenium import selenium class SeleniumSpider(CrawlSpider): name = "SeleniumSpider" start_urls = ["http://www.domain.com"] rules = ( Rule(SgmlLinkExtractor(allow=('\.html', )), callback='parse_page',follow=True), ) def __init__(self): CrawlSpider.__init__(self) self.verificationErrors = [] self.selenium = selenium("localhost", 4444, "*chrome", "http://www.domain.com") self.selenium.start() def __del__(self): self.selenium.stop() print self.verificationErrors CrawlSpider.__del__(self) def parse_page(self, response): item = Item() hxs = HtmlXPathSelector(response) #Do some XPath selection with Scrapy hxs.select('//div').extract() sel = self.selenium sel.open(response.url) #Wait for javscript to load in Selenium time.sleep(2.5) #Do some crawling of javascript created content with Selenium sel.get_text("//div") yield item # Snippet imported from snippets.scrapy.org (which no longer works) # author: wynbennett # date : Jun 21, 2011
ссылка: http://snipplr.com/view/66998/
другим решением было бы реализовать обработчик загрузки или промежуточное программное обеспечение обработчика загрузки. Следующий пример middleware с помощью Селена с безголовым помощи PhantomJS с WebDriver:
class JsDownload(object):
@check_spider_middleware
def process_request(self, request, spider):
driver = webdriver.PhantomJS(executable_path='D:\phantomjs.exe')
driver.get(request.url)
return HtmlResponse(request.url, encoding='utf-8', body=driver.page_source.encode('utf-8'))
Я хотел, чтобы возможность сказать различным паукам, какое промежуточное ПО использовать, поэтому я реализовал эту оболочку:
def check_spider_middleware(method):
@functools.wraps(method)
def wrapper(self, request, spider):
msg = '%%s %s middleware step' % (self.__class__.__name__,)
if self.__class__ in spider.middleware:
spider.log(msg % 'executing', level=log.DEBUG)
return method(self, request, spider)
else:
spider.log(msg % 'skipping', level=log.DEBUG)
return None
return wrapper
settings.py:
DOWNLOADER_MIDDLEWARES = {'MyProj.middleware.MiddleWareModule.MiddleWareClass': 500}
для работы обертки все пауки должны иметь как минимум:
middleware = set([])
включить middleware:
middleware = set([MyProj.middleware.ModuleName.ClassName])
основным преимуществом реализации этого способа, а не в spider является то, что вы делаете только один запрос. В решении T, например: обработчик загрузки обрабатывает запрос, а затем передает ответ пауку. Затем паук делает новый запрос в своей функции parse_page - это два запроса для одного и того же контента.
я использовал пользовательский загрузчик middleware, но не был очень доволен этим, так как мне не удалось заставить кэш работать с ним.
лучшим подходом было реализовать пользовательский обработчик загрузки.
есть рабочий пример здесь. Выглядит это так:
# encoding: utf-8
from __future__ import unicode_literals
from scrapy import signals
from scrapy.signalmanager import SignalManager
from scrapy.responsetypes import responsetypes
from scrapy.xlib.pydispatch import dispatcher
from selenium import webdriver
from six.moves import queue
from twisted.internet import defer, threads
from twisted.python.failure import Failure
class PhantomJSDownloadHandler(object):
def __init__(self, settings):
self.options = settings.get('PHANTOMJS_OPTIONS', {})
max_run = settings.get('PHANTOMJS_MAXRUN', 10)
self.sem = defer.DeferredSemaphore(max_run)
self.queue = queue.LifoQueue(max_run)
SignalManager(dispatcher.Any).connect(self._close, signal=signals.spider_closed)
def download_request(self, request, spider):
"""use semaphore to guard a phantomjs pool"""
return self.sem.run(self._wait_request, request, spider)
def _wait_request(self, request, spider):
try:
driver = self.queue.get_nowait()
except queue.Empty:
driver = webdriver.PhantomJS(**self.options)
driver.get(request.url)
# ghostdriver won't response when switch window until page is loaded
dfd = threads.deferToThread(lambda: driver.switch_to.window(driver.current_window_handle))
dfd.addCallback(self._response, driver, spider)
return dfd
def _response(self, _, driver, spider):
body = driver.execute_script("return document.documentElement.innerHTML")
if body.startswith("<head></head>"): # cannot access response header in Selenium
body = driver.execute_script("return document.documentElement.textContent")
url = driver.current_url
respcls = responsetypes.from_args(url=url, body=body[:100].encode('utf8'))
resp = respcls(url=url, body=body, encoding="utf-8")
response_failed = getattr(spider, "response_failed", None)
if response_failed and callable(response_failed) and response_failed(resp, driver):
driver.close()
return defer.fail(Failure())
else:
self.queue.put(driver)
return defer.succeed(resp)
def _close(self):
while not self.queue.empty():
driver = self.queue.get_nowait()
driver.close()
предположим, что ваш скребок называется "скребок". Если вы поместите упомянутый код в файл с именем handlers.py в корне папки "скребок", затем вы можете добавить в свой settings.py:
DOWNLOAD_HANDLERS = {
'http': 'scraper.handlers.PhantomJSDownloadHandler',
'https': 'scraper.handlers.PhantomJSDownloadHandler',
}
и вуаля, JS проанализировал DOM, со скрипучим кэшем, повторными попытками и т. д.
я обрабатываю запрос ajax с помощью Selenium и веб-драйвера Firefox. Это не так быстро, если вам нужен Искатель в качестве демона, но намного лучше, чем любое ручное решение. Я написал короткий учебник здесь для справки
как можно использовать scrapy для очистки этих динамических данных, чтобы я мог использовать это?
интересно, почему никто не опубликовал решение, используя только Scrapy.
Проверьте сообщение в блоге от Scrapy team ВЫСКАБЛИВАНИЕ БЕСКОНЕЧНЫХ СТРАНИЦ ПРОКРУТКИ . Пример лоскутков http://spidyquotes.herokuapp.com/scroll веб-сайт, который использует бесконечную прокрутку.
идея используйте инструменты разработчика Вашего браузера и обратите внимание на запросы AJAX, а затем на основе этой информации создайте запросы для Scrapy.
import json
import scrapy
class SpidyQuotesSpider(scrapy.Spider):
name = 'spidyquotes'
quotes_base_url = 'http://spidyquotes.herokuapp.com/api/quotes?page=%s'
start_urls = [quotes_base_url % 1]
download_delay = 1.5
def parse(self, response):
data = json.loads(response.body)
for item in data.get('quotes', []):
yield {
'text': item.get('text'),
'author': item.get('author', {}).get('name'),
'tags': item.get('tags'),
}
if data['has_next']:
next_page = data['page'] + 1
yield scrapy.Request(self.quotes_base_url % next_page)