Нормализация Unicode в Postgres
у меня есть большое количество шотландских и валлийских акцентированных топонимов (сочетающих grave, acute, circumflex и diareses), которые мне нужно обновить до их нормализованной формы unicode, например, более короткая форма 00E1 (xe1) для á вместо 0061 + 0301 (x61x301)
Я нашел решение из старого почтового списка Postgres nabble с 2009 года, используя pl / python,
create or replace function unicode_normalize(str text) returns text as $$
import unicodedata
return unicodedata.normalize('NFC', str.decode('UTF-8'))
$$ LANGUAGE PLPYTHONU;
это работает, как и ожидалось, но заставило меня задуматься, есть ли способ сделать это напрямую со встроенным Функции Постгреса. Я пробовал различные преобразования с помощью convert_to, все напрасно.
EDIT: как отметил Крейг, и одна из вещей, которые я пробовал:
SELECT convert_to(E'u00E1', 'iso-8859-1');
возвращает xe1, а
SELECT convert_to(E'u0061u0301', 'iso-8859-1');
выдает ERROR: character 0xcc81 of encoding "UTF8" has no equivalent in "LATIN1"
1 ответов
Я думаю, что это ошибка Pg.
PostgreSQL должен нормализовать utf-8 в предварительно составленную форму перед выполнением преобразований кодирования. Результаты приведенных преобразований неверны.
Я подниму его на pgsql-багах ... сделанный.
http://www.postgresql.org/message-id/53E179E1.3060404@2ndquadrant.com
вы должны иметь возможность следить за потоком там.
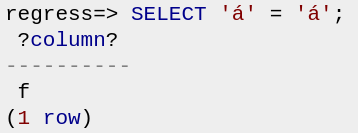
BTW, это можно упростить вниз кому:
regress=> SELECT 'á' = 'á';
?column?
----------
f
(1 row)
что является простым сумасшедшим разговором, но разрешено. Первый составлен заранее, второй-нет. (Чтобы увидеть этот результат, вам нужно скопировать и вставить, и он будет работать, только если Ваш браузер или терминал не нормализуют utf-8).
Если вы используете Firefox, вы можете не увидеть выше правильно; Chrome отображает его правильно. Вот что вы должны увидеть, если Ваш браузер правильно обрабатывает разложенный Unicode: