Обнаружение объектов с помощью Surf
Я пытаюсь обнаружить автомобиль из видео, я сделаю это в режиме реального времени, но на данный момент и для хорошего понимания я делаю это на видео , код ниже:
void surf_detection(Mat img_1,Mat img_2); /** @function main */
int main( int argc, char** argv )
{
int i;
int key;
CvCapture* capture = cvCaptureFromAVI("try2.avi");// Read the video file
if (!capture){
std::cout <<" Error in capture video file";
return -1;
}
Mat img_template = imread("images.jpg"); // read template image
int numFrames = (int) cvGetCaptureProperty(capture, CV_CAP_PROP_FRAME_COUNT);
IplImage* img = 0;
for(i=0;i<numFrames;i++){
cvGrabFrame(capture); // capture a frame
img=cvRetrieveFrame(capture); // retrieve the captured frame
surf_detection (img_template,img);
cvShowImage("mainWin", img);
key=cvWaitKey(20);
}
return 0;
}
void surf_detection(Mat img_1,Mat img_2)
{
if( !img_1.data || !img_2.data )
{
std::cout<< " --(!) Error reading images " << std::endl;
}
//-- Step 1: Detect the keypoints using SURF Detector
int minHessian = 400;
SurfFeatureDetector detector( minHessian );
std::vector<KeyPoint> keypoints_1, keypoints_2;
std::vector< DMatch > good_matches;
do{
detector.detect( img_1, keypoints_1 );
detector.detect( img_2, keypoints_2 );
//-- Draw keypoints
Mat img_keypoints_1; Mat img_keypoints_2;
drawKeypoints( img_1, keypoints_1, img_keypoints_1, Scalar::all(-1), DrawMatchesFlags::DEFAULT );
drawKeypoints( img_2, keypoints_2, img_keypoints_2, Scalar::all(-1), DrawMatchesFlags::DEFAULT );
//-- Step 2: Calculate descriptors (feature vectors)
SurfDescriptorExtractor extractor;
Mat descriptors_1, descriptors_2;
extractor.compute( img_1, keypoints_1, descriptors_1 );
extractor.compute( img_2, keypoints_2, descriptors_2 );
//-- Step 3: Matching descriptor vectors using FLANN matcher
FlannBasedMatcher matcher;
std::vector< DMatch > matches;
matcher.match( descriptors_1, descriptors_2, matches );
double max_dist = 0;
double min_dist = 100;
//-- Quick calculation of max and min distances between keypoints
for( int i = 0; i < descriptors_1.rows; i++ )
{
double dist = matches[i].distance;
if( dist < min_dist )
min_dist = dist;
if( dist > max_dist )
max_dist = dist;
}
//-- Draw only "good" matches (i.e. whose distance is less than 2*min_dist )
for( int i = 0; i < descriptors_1.rows; i++ )
{
if( matches[i].distance < 2*min_dist )
{
good_matches.push_back( matches[i]);
}
}
}while(good_matches.size()<100);
//-- Draw only "good" matches
Mat img_matches;
drawMatches( img_1, keypoints_1, img_2, keypoints_2,good_matches, img_matches, Scalar::all(-1), Scalar::all(-1),
vector<char>(), DrawMatchesFlags::NOT_DRAW_SINGLE_POINTS );
//-- Localize the object
std::vector<Point2f> obj;
std::vector<Point2f> scene;
for( int i = 0; i < good_matches.size(); i++ )
{
//-- Get the keypoints from the good matches
obj.push_back( keypoints_1[ good_matches[i].queryIdx ].pt );
scene.push_back( keypoints_2[ good_matches[i].trainIdx ].pt );
}
Mat H = findHomography( obj, scene, CV_RANSAC );
//-- Get the corners from the image_1 ( the object to be "detected" )
std::vector<Point2f> obj_corners(4);
obj_corners[0] = Point2f(0,0);
obj_corners[1] = Point2f( img_1.cols, 0 );
obj_corners[2] = Point2f( img_1.cols, img_1.rows );
obj_corners[3] = Point2f( 0, img_1.rows );
std::vector<Point2f> scene_corners(4);
perspectiveTransform( obj_corners, scene_corners, H);
//-- Draw lines between the corners (the mapped object in the scene - image_2 )
line( img_matches, scene_corners[0] , scene_corners[1] , Scalar(0, 255, 0), 4 );
line( img_matches, scene_corners[1], scene_corners[2], Scalar( 0, 255, 0), 4 );
line( img_matches, scene_corners[2] , scene_corners[3], Scalar( 0, 255, 0), 4 );
line( img_matches, scene_corners[3] , scene_corners[0], Scalar( 0, 255, 0), 4 );
imshow( "Good Matches & Object detection", img_matches );
}
Я получаю следующий вывод
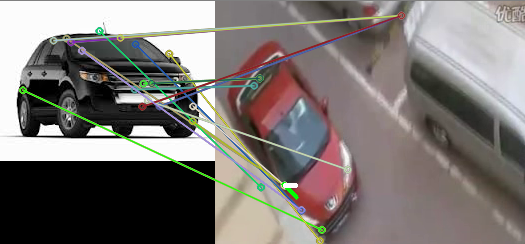
и std:: cout
![std::cout << scene_corners[i] (Result)](/images/content/17570421/3095287f0a4702a03ca0c6beba1165ac.png)
значение H:
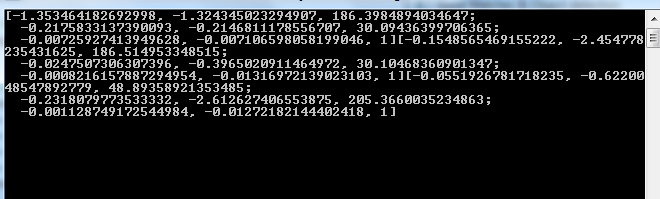
но мой вопрос в том, почему его не рисовать прямоугольник на объект, который обнаруживается как:
Я делаю это на простом видео и изображении, но когда я сделал это на неподвижной камере, так что это может быть трудно без этого прямоугольника
4 ответов
во-первых, на изображении, которое вы показываете, прямоугольник не рисуется вообще. Можете ли вы нарисовать прямоугольник, скажем, в середине вашего изображения?
потом, глядя на следующий код:
int x1 , x2 , y1 , y2 ;
x1 = scene_corners[0].x + Point2f( img_1.cols, 0).x ;
y1 = scene_corners[0].y + Point2f( img_1.cols, 0).y ;
x2 = scene_corners[0].x + Point2f( img_1.cols, 0).x + in_box.width ;
y2 = scene_corners[0].y + Point2f( img_1.cols, 0).y + in_box.height ;
я не понимаю, почему вы добавляете in_box.width и in_box.height к каждому углу (где они определены?). Вы должны использовать . Но комментируемые строки должны где-то печатать прямоугольник.
так как вы попросили более подробную информацию, давайте посмотрим, что происходит в вашем код.
во-первых, как добраться до perspectiveTransform()?
- определить feature points используя
detector.detect. Это дает вам точки интереса в обоих изображениях. - вы описания эти функции с помощью
extractor.compute. Это дает вам возможность сравнить достопримечательности. Сравнение дескрипторов двух функций отвечает на вопрос: насколько похожи эти точки?* - вы фактически сравниваете каждую функцию на первом изображении с все функции во втором изображении (вроде), и сохранить лучшее соответствие для каждой функции. На данный момент Вы знаете пары функций, которые выглядят наиболее похожими.
- вы только держать
good_matches. Потому что может случиться так, что для одной функции наиболее похожий на другой образ на самом деле совершенно другой (это все еще наиболее похожие так как у вас не было лучшего выбора). Это первый фильтр для удаления неправильных совпадений. - вы находите гомографию преобразования, соответствующие играм, вы нашли. Это означает, что вы пытаетесь найти, как точка на первом изображении должна проецироваться на втором изображении. Матрица гомографии, которую вы получаете, позволяет проецировать любую точку первого изображения на его соответствие во втором изображении.
во-вторых, что делать с этим?
теперь становится интересно. у вас есть матрица гомографии, которая позволяет проецировать любую точку первого изображения на его соответствие во втором изображении. Таким образом, вы можете нарисовать прямоугольник вокруг вашего объекта (то есть obj_corners), и проецировать его на второе изображение (perspectiveTransform( obj_corners, scene_corners, H);). Результат в scene_corners.
теперь вы хотите нарисовать прямоугольник с помощью scene_corners. Но есть еще один момент:drawMatches() видимо, ставит оба изображения рядом друг с другом в img_matches. Но проекция (матрица гомографии) была вычислена на изображениях отдельно! Что означает, что каждый scene_corner должен быть переводится соответственно. Поскольку изображение сцены было нарисовано справа от изображения объекта, вы должны добавить ширину изображения объекта к каждому scene_corner для того, чтобы перевести их вправо.
вот почему вы добавить 0 to y1 и y2 так как вам не нужно переводить их вертикально. Но для x1 и x2, вы должны добавить img_1.cols.
//-- Draw lines between the corners (the mapped object in the scene - image_2 )
line( img_matches, scene_corners[0] + Point2f( img_1.cols, 0), scene_corners[1] + Point2f( img_1.cols, 0), Scalar(0, 255, 0), 4 );
line( img_matches, scene_corners[1] + Point2f( img_1.cols, 0), scene_corners[2] + Point2f( img_1.cols, 0), Scalar( 0, 255, 0), 4 );
line( img_matches, scene_corners[2] + Point2f( img_1.cols, 0), scene_corners[3] + Point2f( img_1.cols, 0), Scalar( 0, 255, 0), 4 );
line( img_matches, scene_corners[3] + Point2f( img_1.cols, 0), scene_corners[0] + Point2f( img_1.cols, 0), Scalar( 0, 255, 0), 4 );
поэтому я предлагаю вам раскомментировать эти линии и посмотреть, нарисован ли прямоугольник. Если нет, попробуйте жесткие значения кода (например,Point2f(0, 0) и Point2f(100, 100)), пока ваш прямоугольник не будет нарисован успешно. Возможно, ваша проблема связана с использованием cvPoint и Point2f вместе. Также попробуйте использовать Scalar(0, 255, 0, 255)...
надеюсь, что это помогает.
вы сделали следующие шаги:
- совпадение ключевых точек на 2 изображениях.
- предполагая, что совпадение было правильным, вычислите гомографию (матрицу проекции).
- используйте гомографию для проецирования углов исходного изображения, чтобы нарисовать четырехугольную форму (которую вы называете прямоугольником).
проблема заключается в том, что, когда Шаг 1 терпит неудачу, вы получаете неправильную гомографию на Шаге 2 (Неправильная матрица) и когда вы проецируете углы на Шаге 3, они могут выпасть из изображения, и вы не видите линий.
то, что вы на самом деле хотите, это способ узнать, является ли рассчитанная вами гомография правильной формы. Для этого, пожалуйста, смотрите ответ здесь:Как проверить, является ли полученная матрица гомографии хорошей? Используйте его, чтобы проверить правильность вашей гомографии. Если нет, то вы знаете, что матч закончился неудачей. Если это правильно, вы можете нарисовать прямоугольник, и вы увидите его, но он может будьте не так точны, если матч между ключевыми точками не был точным.
наконец, я думаю, что ваш алгоритмический подход неверен. Распознавание / обнаружение транспортного средства сверху, сопоставляя его с изображением транспортного средства спереди, является тупиком. Вы не должны использовать ключевые точки, соответствующие вообще. Просто отметьте вручную все транспортные средства на изображениях и отправьте его в SVM. Если это слишком много работы, используйте механическую платформу Turk для автоматической маркировки автомобилей. В заключение - ключевые моменты матча это подход, который просто не соответствует вашим потребностям, потому что он имеет сильное предположение, что внешний вид автомобиля на обоих изображениях похож. В вашем случае эти изображения слишком разные (из-за 3D-структуры автомобиля и разных углов обзора)
то, что вы на самом деле делаете, это найти опорные точки в изображениях (ключевые точки) и сравнить их друг с другом, чтобы найти их повторение в других изображениях (на основе вектора функций SURF). Это важный шаг в обнаружении и распознавании объектов, но не следует ошибаться с сегментацией изображения (http://en.wikipedia.org/wiki/Image_segmentation) или локализация объекта, где вы найдете точные контуры (или набор пикселей или суперпикселей) желаемого объект.
получаем ограничивающий прямоугольник объекта, особенно в перспективе, как в вашем примере, не является тривиальной задачей. Вы можете начать с ограничивающей рамки ключевых точек, которые были найдены. Однако, это будет охватывать только часть объекта. Особенно ограничивающую рамку в перспективе в вашем примере может быть трудно найти без 3D-регистрации изображения, т. е. зная значение 3-го измерения (z-значение, глубина) каждого пикселя на изображении.
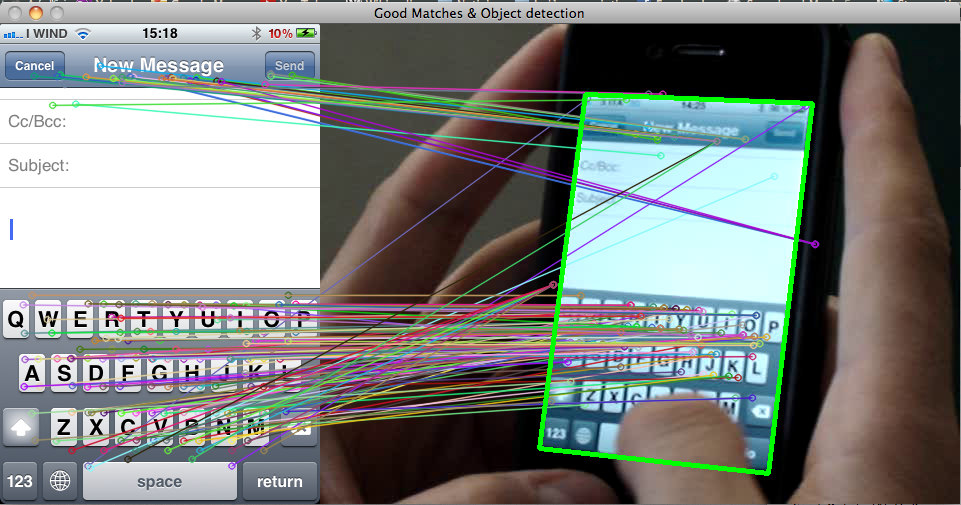
так же, как этот? рисование прямоугольника вокруг обнаруженного объекта с помощью SURF
насколько я могу судить, единственная причина, по которой контур не нарисован, заключается в том, что раздел кода, который делает это, закомментирован, поэтому раскомментируйте его. Эта часть кода описала тестовый образ для меня:
/*
//-- Draw lines between the corners (the mapped object in the scene - image_2 )
line( img_matches, scene_corners[0] + Point2f( img_1.cols, 0), scene_corners[1] + Point2f( img_1.cols, 0), Scalar(0, 255, 0), 4 );
line( img_matches, scene_corners[1] + Point2f( img_1.cols, 0), scene_corners[2] + Point2f( img_1.cols, 0), Scalar( 0, 255, 0), 4 );
line( img_matches, scene_corners[2] + Point2f( img_1.cols, 0), scene_corners[3] + Point2f( img_1.cols, 0), Scalar( 0, 255, 0), 4 );
line( img_matches, scene_corners[3] + Point2f( img_1.cols, 0), scene_corners[0] + Point2f( img_1.cols, 0), Scalar( 0, 255, 0), 4 ); */
вы, вероятно, не хотите рисовать прямоугольник вокруг соответствующего шаблона в видеоизображении, потому что он может быть искажен. Подключите деформированный scene_corners с линиями, вместо. Я бы убрал все это x1, x2, y1, y2 и cvRect square вещи.
отметим, что scene_corners не дает вам прямоугольник, потому что объект может быть повернут в видео иначе, чем в изображении шаблона. Изображение сотового телефона, размещенное выше, является отличным примером, - зеленый контур вокруг экрана телефона является четырехугольником. Если вы хотите работать с прямоугольным ROI, содержащим весь объект, вы можете рассмотреть возможность поиска ограничивающего прямоугольника, содержащего весь объект на видео. Вот как я это сделаю:
// draw the *rectangle* that contains the entire detected object (a quadrilateral)
// i.e. bounding box in the scene (not the corners)
// upper left corner of bounding box
cv::Point2f low_bound = cv::Point2f( min(scene_corners[0].x, scene_corners[3].x) , min(scene_corners[0].y, scene_corners[1].y) );
// lower right corner of bounding box
cv::Point2f high_bound = cv::Point2f( max(scene_corners[2].x, scene_corners[1].x) , max(scene_corners[2].y, scene_corners[3].y) );
// bounding box offset introduced by displaying the images side-by-side
// *only for side-by-side display*
cv::Point2f matches_offset = cv::Point2f( img_1.cols, 0);
// draw the bounding rectangle in the side-by-side display
cv::rectangle( img_matches , low_bound + matches_offset , high_bound + matches_offset , cv::Scalar::all(255) , 2 );
/*
if you want the rectangle around the object in the original video images, don't add the
offset and use the following line instead:
cv::rectangle( img_matches , low_bound , high_bound , cv::Scalar::all(255) , 2 );
*/
// Here is the actual rectangle, you can use as the ROI in you video images:
cv::Rect video_rect = cv::Rect( low_bound , high_bound );
последняя строка в блоке кода выше может иметь прямоугольник вы пытались сделать в своем первоначально написал код. Это должен быть прямоугольник в видеоизображение, img. Вы можете использовать его для работы с подмножеством изображения, которое содержит объект (ROI).
как упоминал Анум, вы также смешиваете старый и новый стиль OpenCV. Вы можете очистить вещи, последовательно используя Point2f а не cvPoint, между прочем.