обновление строки таблицы с UpdateResource
Я задал вопрос здесь -обновление таблицы строк с помощью UpdateResource (добавление нескольких строк)
и теперь я спрашиваю снова, так как на этот раз я могу добавить больше деталей к вопросу.
Я пробовал это в течение последнего дня или что-то безрезультатно.
Я хочу, чтобы результат был таким (я вручную добавил строки в MSVS):
Как вы можете видеть, несколько записей, и это "чистый" и может быть легко доступен программа!
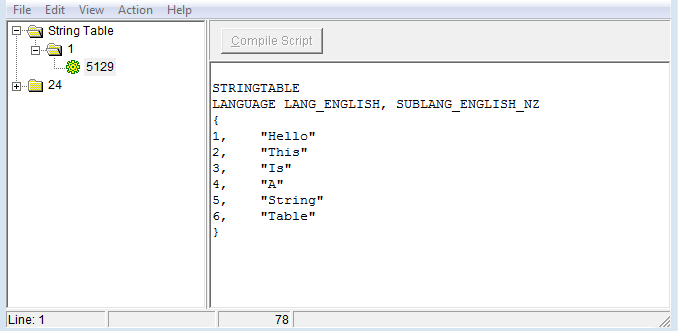
сейчас, мой источник:
wstring buffer[5] = {L" Meow",L" I",L" Am",L" A",L" Dinosaur"}; // ignore the string
if (HANDLE hRes = BeginUpdateResource("Output.exe",TRUE))
{
for (int i = 0; i < 5; i++)
{
wchar_t * temp;
temp = new wchar_t[(buffer[i].length()+1)];
wcscpy(temp,buffer[i].c_str());
wcout << temp << endl;
UpdateResource(hRes,RT_STRING,MAKEINTRESOURCE(1),MAKELANGID(LANG_NEUTRAL, SUBLANG_DEFAULT),
temp, 48); //buffer[i].length()+1
delete[] temp;
}
EndUpdateResource(hRes,FALSE);
}
производит:
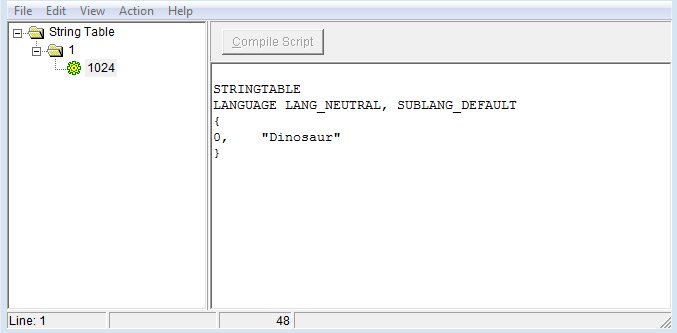
что неверно, так как, похоже, добавлена только последняя строка в таблицу, а не строки перед ней!
когда я пытаюсь изменить источник, поэтому MAKEINTRESOURCE (1) теперь " MAKEINTRESOURCE (i)", результат таков, как показано на различных рисунках:
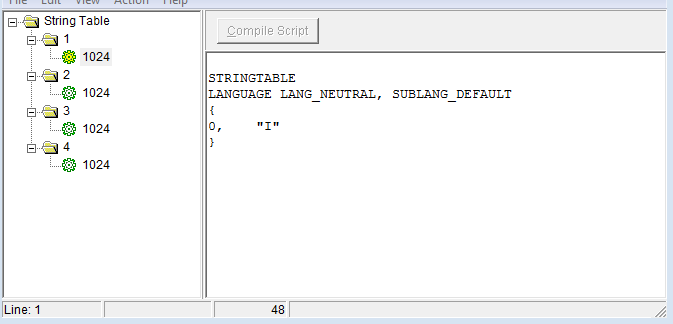
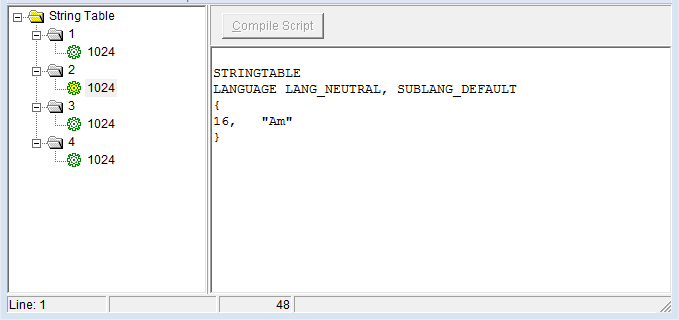
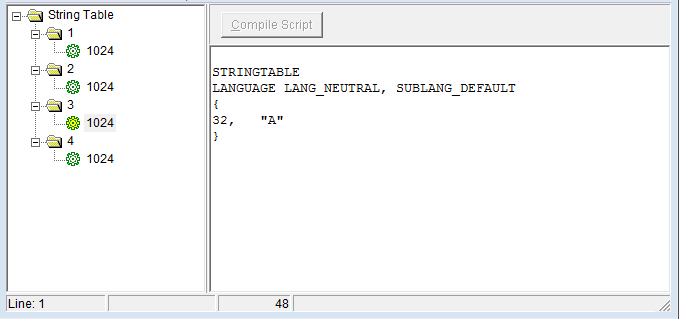
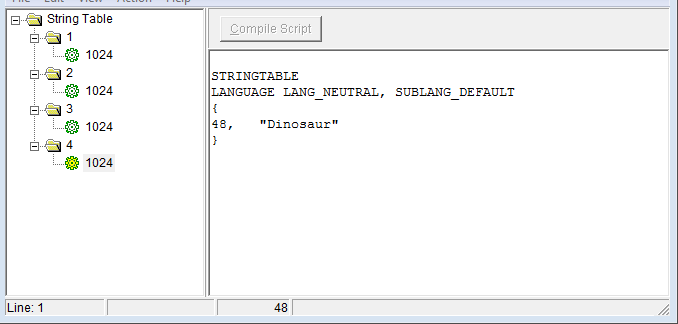
успех в том, что он добавил все строки, но, кажется, есть создал различные строковые таблицы, которые не то, что было желательно. Хотя я замечаю, что идентификаторы увеличились на 16 на каждом снимке, что может что-то объяснить. В принципе, я хочу, чтобы строки были отформатированы как на первом рисунке (с несколькими строками), но не имею реального представления, как это сделать.
Спасибо за помощь.
1 ответов
строковые ресурсы отличаются от любого другого формата ресурсов. Они не хранятся как отдельные записи, а упакованы в группы по 16 строк каждая. Первая группа хранит строки с 0 по 15, вторая группа хранит строки с 16 по 31 и так далее. На ваших скриншотах выше группы отображаются как первый уровень под родителем в treeview слева.
строковые ресурсы также отличаются тем, что они хранятся в виде строк Юникода (без нулевого Терминатора) в отличие от нулевых c-строк. Так, например, C-string 'T' 'e' 's' 't' '' будет храниться в виде 0004 0054 0065 0073 0074 где первая WORD указывает длину и оставшиеся 4 WORDs представляют символы Юникода.
следствием этого формата ресурса является то, что если есть пробелы в идентификаторах строк в группе, отсутствующие строки должны учитываться строками нулевой длины или просто 0000 в формате ресурса говорить. Итак, если ваша таблица string имеет строки с идентификаторами 2 и 5 будет одна группа (1) с 16 записями: 0000 0000 <string 2> 0000 0000 <string 5> 0000 0000 ... 0000.
требуется еще одна информация, а именно, какой идентификатор ресурса передать для в вызове UpdateResource: поскольку группы ресурсов строки могут быть обновлены только в целом, вы должны предоставить идентификатор группы, где первая группа имеет ID 1. Вычисление идентификатора группы из идентификатора строки выполняется с помощью groupID = ( strID >> 4 ) + 1, в то время как относительное (нулевое) смещение в группе равно strOffset = strID % 16. Если вы посмотрите на результат, полученный от прохождения MAKEINTRESOURCE(1) теперь вы можете понять, почему он оказался в группе 1 с идентификатором 0.
сложение всех частей вместе вы можете обновить строковый ресурс, используя следующий код:
void ReplaceStringTable() {
HANDLE hRes = BeginUpdateResource( _T( "Output.exe" ), TRUE );
if ( hRes != NULL ) {
wstring data[] = { L"", // empty string to skip string ID 0
L"Raymond",
L"Chen",
L"is",
L"my",
L"Hero!",
// remaining strings to complete the group
L"", L"", L"", L"", L"", L"", L"", L"", L"", L""
};
vector< WORD > buffer;
for ( size_t index = 0;
index < sizeof( data ) / sizeof( data[ 0 ] );
++index ) {
size_t pos = buffer.size();
buffer.resize( pos + data[ index ].size() + 1 );
buffer[ pos++ ] = static_cast< WORD >( data[ index ].size() );
copy( data[ index ].begin(), data[ index ].end(),
buffer.begin() + pos );
}
UpdateResource( hRes,
RT_STRING,
MAKEINTRESOURCE( 1 ),
MAKELANGID( LANG_NEUTRAL, SUBLANG_DEFAULT ),
reinterpret_cast< void* >( &buffer[ 0 ] ),
buffer.size() * sizeof( WORD ) );
EndUpdateResource( hRes, FALSE );
}
}