Обработка естественного языка для умных домов
Я пишу умное домашнее программное обеспечение для моей степени бакалавра, которое будет только имитировать фактический дом, но я застрял в части НЛП проекта. Идея состоит в том, чтобы клиент прослушивал голосовые входы (уже сделано), преобразовывал их в текст (сделано) и отправлял его на сервер, который делает все тяжелое / принятие решений.
поэтому все мои входы будут довольно короткими (например, "пожалуйста, включите свет на крыльце"). Исходя из этого, я хочу принять решение о том, какой объект действовать, и как действовать. Поэтому я придумал несколько вещей, чтобы написать что-то более эффективное.
- избавьтесь от ненужных слов (в предыдущем примере " пожалуйста "и" the "- это слова, которые не меняют значения того, что нужно сделать; но если я скажу " выключить мой огни", " мой " имеет довольно важное значение).
- дело с синонимами ("включить свет "должно делать то же самое, что и" включить свет " - я знаю, что это глупый пример). Я предполагаю, что единственный вариант-иметь какой-то словарь (возможно, XML) и просто иметь список возможных слов для одного конкретного объекта в доме.
- обнаружение глагола и субъекта. "включить" - это глагол,а" свет " - субъект. Мне нужен хороший способ обнаружить это.
- общие реализации. Как эти вещи обычно разрабатываются с точки зрения алгоритмов? Мне удалось найти только одну статью о НЛП в умных домах, которая была очень расплывчатой (и имела плохой Английский.) Любые ссылки приветствуются.
Я надеюсь, что вопрос достаточно уникален (я видел вопросы НЛП на SO, никто не помог), что он не будет закрыт.
3 ответов
Я никоим образом не пионер в НЛП(мне это нравится), но позвольте мне попробовать свои силы на этом. Для вашего проекта я бы предложил вам пройти Стэнфордский Парсер
из вашего определения проблемы я думаю, вам не нужно ничего другого, кроме глаголов и существительных. SP генерирует POS (часть речевых тегов), которые можно использовать для обрезки слов, которые вам не нужны.
для этого я не могу придумать лучшего варианта, чем то, что у вас есть в прямо сейчас.
для этого снова вы можете использовать грамматическую структуру зависимостей от SP, и я почти уверен, что она достаточно хороша для решения этой проблемы.
вот где лежит ваша исследовательская часть. Я думаю, вы можете найти достаточно шаблонов, используя теги GD и POS, чтобы придумать алгоритм для вашей проблемы. Я вряд ли сомневаюсь, что любой алгоритм будет достаточно эффективен для обработки каждого набора входных предложений (структурированных+неструктурированных), но должно быть достаточно хорошо для вас то, что более 85% точно.
Если у вас нет много времени, чтобы провести с проблемой НЛП, вы можете использовать Wit API (http://wit.ai) который сопоставляет предложения естественного языка с JSON:
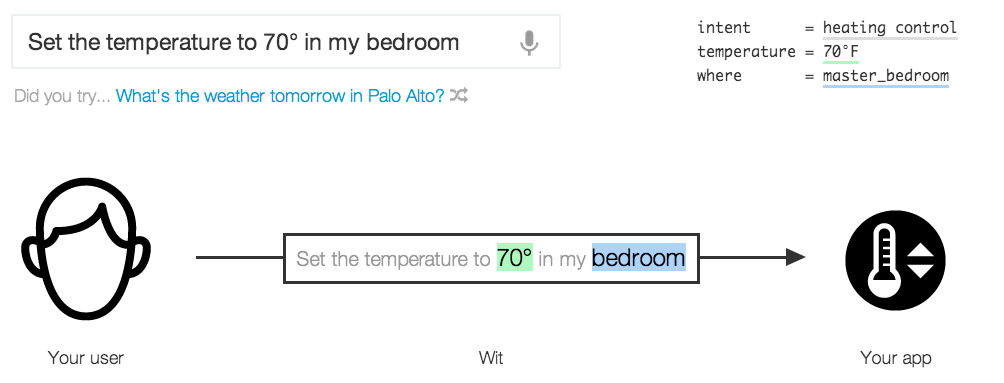
Он основан на машинном обучении, поэтому вам нужно предоставить примеры предложений + вывод JSON, чтобы настроить его для ваших нужд. Он должен быть намного более надежным, чем грамматические подходы, особенно потому, что движок голос-речь может совершать ошибки, которые нарушат вашу грамматику (но модуль машинного обучения все еще может получить значение предложения).
во-первых, я бы построил список всех возможных команд (не каждый возможный способ сказать команду, просто сама фактическая функция: "свет на кухне" и "включить свет на кухне" - одна и та же команда) на основе фактической функциональности, доступной в умном доме. Я предполагаю, что существует дискретное число их в порядке не более сотен. Присвоить каждому какой-то код идентификатора.
ваша задача затем становится сопоставить вход из:
- предложение английского текста
- расположение динамиков
- время суток, день недели
- любые другие входные данные
к выходу доверительного уровня (от 0.0 до 1.0) для каждой команды.
система затем выполнит команду best match, если доверие превышает некоторый настраиваемый порог (скажем, более 0.70).
отсюда становится машинного обучения. Существует ряд различные подходы (и, кроме того, подходы могут быть объединены вместе, если они конкурируют на основе особенностей ввода).
для начала я бы работал через книги НЛП от Jurafsky/Мэннинг из Стэнфордского. Это хороший обзор современных алгоритмов НЛП.
оттуда вы получите некоторые идеи о том, как отображение может быть изучено машиной. Более важно, как естественный язык может быть разбит на математическую структуру для машины обучающий.
Как только текст семантически проанализирован, простейший алгоритм ML для первой попытки будет из контролируемых. Чтобы сгенерировать обучающие данные с обычным графическим интерфейсом, произнесите свою команду, затем нажмите соответствующую команду вручную. Это образует единый обучающий случай под наблюдением. Сделайте из них большое количество. Отложите некоторые для тестирования. Это также неквалифицированная работа, поэтому другие люди могут помочь. Затем вы можете использовать их в качестве тренировочного набора для своего алгоритма ML.